設定 Apache Spark 設定
HDInsight Spark 叢集包含 Apache Spark 連結庫的安裝。 每個 HDInsight 叢集都包含所有已安裝服務的預設組態參數,包括 Spark。 管理 HDInsight Apache Hadoop 叢集的關鍵層面是監視工作負載,包括 Spark 作業。 若要最佳執行 Spark 作業,請在判斷叢集的邏輯組態時考慮實體叢集組態。
預設 HDInsight Apache Spark 叢集包含下列節點:三個 Apache ZooKeeper 節點、兩個前端節點和一或多個背景工作節點:
HDInsight 叢集中節點的 VM 數目和 VM 大小可能會影響 Spark 設定。 非預設 HDInsight 組態值通常需要非預設的 Spark 組態值。 當您建立 HDInsight Spark 叢集時,會顯示每個元件的建議 VM 大小。 Azure 的 記憶體優化 Linux VM 大小 目前為 D12 v2 或更新版本。
Apache Spark 版本
為您的叢集使用最佳的Spark版本。 HDInsight 服務包含數個版本的 Spark 和 HDInsight 本身。 每個版本的 Spark 都包含一組預設叢集設定。
當您建立新的叢集時,有多個Spark版本可供選擇。 若要查看完整清單, 請參閱 HDInsight 元件和版本。
注意
HDInsight 服務中 Apache Spark 的預設版本可能會變更,而不需通知。 如果您有版本相依性,Microsoft 建議您在使用 .NET SDK、Azure PowerShell 和 Azure 傳統 CLI 建立叢集時指定該特定版本。
Apache Spark 有三個系統設定位置:
- Spark 屬性控制大部分的應用程式參數,而且可以使用 對象或透過 Java 系統屬性來設定
SparkConf。 - 環境變數可用來透過每個節點上的
conf/spark-env.sh腳本來設定每部計算機設定,例如IP位址。 - 您可以透過
log4j.properties來設定記錄。
當您選取特定版本的 Spark 時,您的叢集會包含預設組態設定。 您可以使用自訂 Spark 組態檔來變更預設的 Spark 組態值。 範例如下所示。
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
上述範例會覆寫五個 Spark 組態參數的數個預設值。 這些值是壓縮編解碼器、Apache Hadoop MapReduce 分割最小大小和 parquet 區塊大小。 此外,Spark SQL 磁碟分區和開啟檔案大小預設值。 系統會選擇這些組態變更,因為相關聯的數據和作業(在此範例中為基因數據)具有特定特性。 這些特性會更妥善地使用這些自定義組態設定。
檢視叢集組態設定
在叢集上執行效能優化之前,請先確認目前的 HDInsight 叢集組態設定。 單擊 Spark 叢集窗格上的 [儀錶板] 連結,從 Azure 入口網站 啟動 HDInsight 儀錶板。 使用叢集管理員的使用者名稱和密碼登入。
Apache Ambari Web UI 隨即出現,其中包含密鑰叢集資源使用計量的儀錶板。 Ambari 儀錶板會顯示 Apache Spark 設定和其他已安裝的服務。 [儀錶板] 包含 [設定歷程記錄] 索引標籤,您可以在其中檢視已安裝服務的資訊,包括Spark。
若要查看 Apache Spark 的組態值,請選取 [設定歷程記錄],然後選取 [Spark2]。 選取 [ 設定] 索引 標籤,然後在服務列表中選取 Spark [或 Spark2],視您的版本而定。 您會看到叢集的組態值清單:
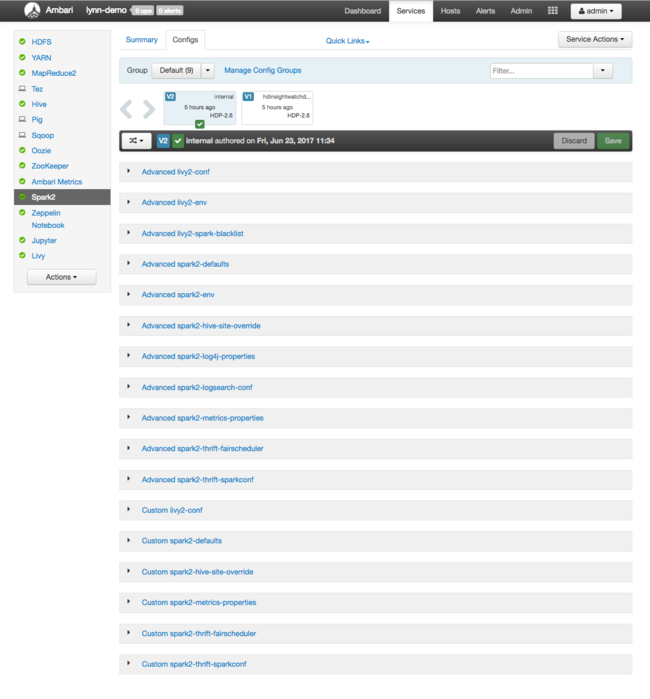
若要查看並變更個別的Spark組態值,請選取標題中包含 「spark」 的任何連結。 Spark 的組態包括下列類別中的自訂和進階組態值:
- 自訂 Spark2 預設值
- 自定義Spark2-metrics-properties
- 進階 Spark2 預設值
- 進階 Spark2-env
- 進階 spark2-hive-site-override
如果您建立非預設組態值,則會顯示您的更新歷程記錄。 此設定歷程記錄有助於查看哪些非預設組態具有最佳效能。
注意
若要查看但未變更的常見 Spark 叢集組態設定,請選取最上層 Spark 作業 UI 介面上的 [環境] 索引卷標。
設定 Spark 執行程式
下圖顯示主要 Spark 對象:驅動程式程式及其相關聯的 Spark 內容,以及叢集管理員及其 n 背景工作節點。 每個背景工作節點都包含執行程式、快取和 n 個工作實例。
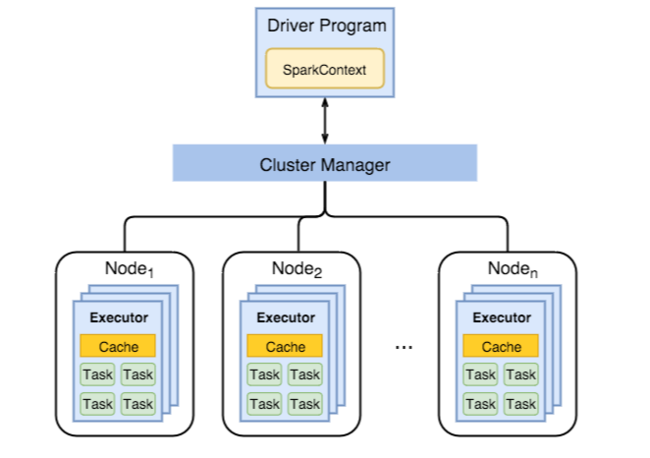
Spark 作業會使用背景工作資源,特別是記憶體,因此通常會調整背景工作節點執行程式所使用的Spark組態值。
經常調整以微調 Spark 組態以改善應用程式需求的三個主要參數為 spark.executor.instances、 spark.executor.cores和 spark.executor.memory。 執行程式是針對 Spark 應用程式啟動的程序。 執行程式會在背景工作節點上執行,並負責應用程式的工作。 背景工作節點和背景工作節點大小的數目會決定執行程序的數目,以及執行程式大小。 這些值會儲存在 spark-defaults.conf 叢集前端節點上。 您可以在執行中的叢集中選取 [自定義 Spark 預設值],在 Ambari Web UI 中編輯這些值。 進行變更之後,UI 會提示您 重新啟動 所有受影響的服務。
注意
這三個組態參數可以在叢集層級設定(針對叢集上執行的所有應用程式),並針對每個個別應用程式指定。
Spark 執行程式所使用資源的另一個資訊來源是 Spark 應用程式 UI。 在UI中, 執行程式 會顯示組態和取用資源的摘要和詳細數據檢視。 判斷要變更整個叢集的執行程式值,還是特定作業執行集的值。
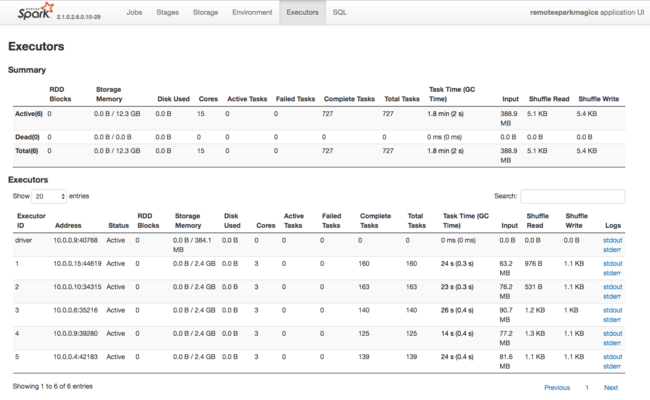
或者,您可以使用Ambari REST API以程式設計方式驗證 HDInsight 和Spark 叢集組態設定。 如需詳細資訊,請參閱 GitHub 上的 Apache Ambari API 參考。
根據您的 Spark 叢集工作負載,您可能會判定非預設 Spark 設定可提供最佳化程度較高的 Spark 作業執行。 使用範例工作負載進行基準檢驗,以驗證任何非預設叢集組態。 您可以考慮調整某些通用參數:
| 參數 | 描述 |
|---|---|
| --num-executors | 設定執行程式的數目。 |
| --executor-cores | 設定每個執行程式的核心數目。 我們建議使用中型執行程式,因為其他進程也會耗用部分可用的記憶體。 |
| --executor-memory | 控制 Apache Hadoop YARN 上每個執行程式的記憶體大小(堆積大小),您必須留下一些記憶體來執行額外負荷。 |
以下是兩個具有不同組態值的背景工作節點範例:

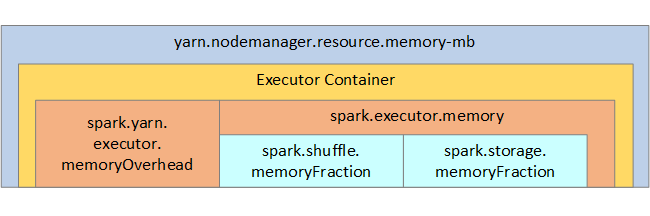
下列清單顯示金鑰 Spark 執行程式記憶體參數。
| 參數 | 描述 |
|---|---|
| spark.executor.memory | 定義執行程式可用的記憶體總量。 |
| spark.storage.memoryFraction | (預設 ~60%) 會定義可用於儲存保存 RDD 的記憶體數量。 |
| spark.shuffle.memoryFraction | (預設 ~20%) 會定義保留給洗牌的記憶體數量。 |
| spark.storage.unrollFraction 和 spark.storage.safetyFraction | (總計約 30% 的總記憶體) - 這些值是由 Spark 內部使用,不應該變更。 |
YARN 控制每個 Spark 節點上容器所使用的記憶體總和上限。 下圖顯示 YARN 組態物件與 Spark 物件之間的每個節點關聯性。
變更在 Jupyter Notebook 中執行之應用程式的參數
HDInsight 中的Spark叢集預設包含許多元件。 這些元件都包含預設元件都包含預設元件值,您可以視需要覆寫這些值。
| 元件 | 描述 |
|---|---|
| Spark 核心 | Spark Core、Spark SQL、Spark 串流 API、GraphX 和 Apache Spark MLlib。 |
| Anaconda | Python 套件管理員。 |
| Apache Livy | 用來將遠端作業提交至 HDInsight Spark 叢集的 Apache Spark REST API。 |
| Jupyter Notebook 和 Apache Zeppelin Notebooks | 與 Spark 叢集互動的互動式瀏覽器型 UI。 |
| ODBC 驅動程式 | 連線 HDInsight 中的 Spark 叢集到商業智慧(BI)工具,例如 Microsoft Power BI 和 Tableau。 |
針對在 Jupyter Notebook 中執行的應用程式,請使用 %%configure 命令從筆記本本身進行組態變更。 這些組態變更會套用至從筆記本實例執行的Spark作業。 在執行第一個程式代碼數據格之前,請先在應用程式開頭進行這類變更。 變更的組態會在建立時套用至 Livy 工作階段。
注意
若要在稍後的應用程式中變更組態,請使用 -f (force) 參數。 不過,應用程式中的所有進度都會遺失。
下列程式代碼示範如何變更在 Jupyter Notebook 中執行之應用程式的設定。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
推論
監視核心組態設定,以確保Spark作業以可預測的高效能方式執行。 這些設定有助於判斷您特定工作負載的最佳 Spark 叢集組態。 您也需要監視長時間執行的 和 或耗用資源的 Spark 作業執行。 最常見的挑戰是以記憶體壓力為中心,因為設定不正確,例如大小不正確的執行程式。 此外,長時間執行的作業和工作,這會導致笛卡兒運算。