了解如何存取如 Apache Ambari UI、Apache Hadoop YARN UI,以及與 Apache Spark 叢集相關聯的 Spark 記錄伺服器等介面的方式,以及如何調整叢集設定以取得最佳效能。
開啟 Spark 歷程記錄伺服器
「Spark 記錄伺服器」是已完成和執行中 Spark 應用程式的 Web UI。 其是 Spark Web UI 的延伸模組。 如需完整資訊,請參閱 Spark 歷程記錄伺服器。
開啟 Yarn UI
您可以使用 YARN UI 來監視目前在 Spark 叢集上執行的應用程式。
從 Azure 入口網站,開啟 Spark 叢集。 如需詳細資訊,請參閱列出和顯示叢集。
從 [叢集儀表板] 中,選取 [Yarn]。 出現提示時,輸入 Spark 叢集的系統管理員認證。
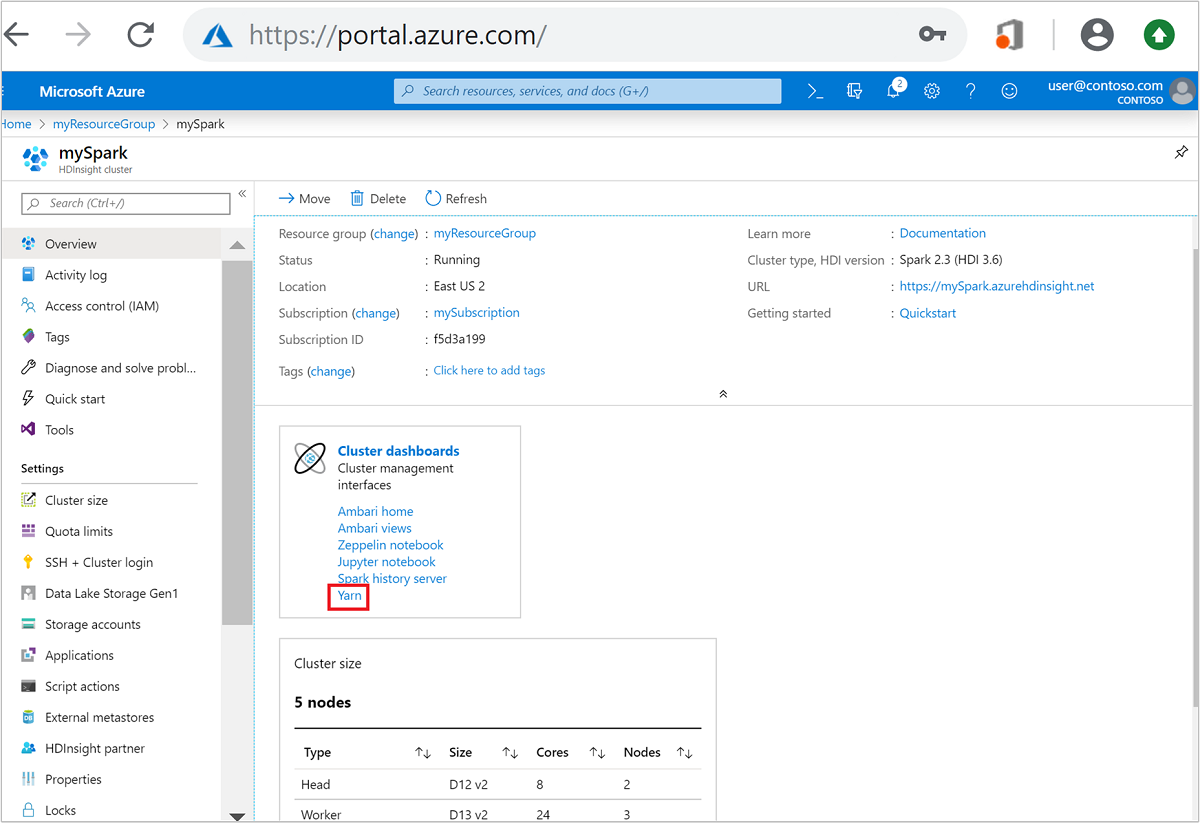
提示
或者,您也可以從 Ambari UI 啟動 YARN UI。 從 Ambari UI 中,瀏覽至 [YARN]>[快速連結]>[作用中]>[Resource Manager UI]。
針對 Spark 應用程式進行叢集最佳化
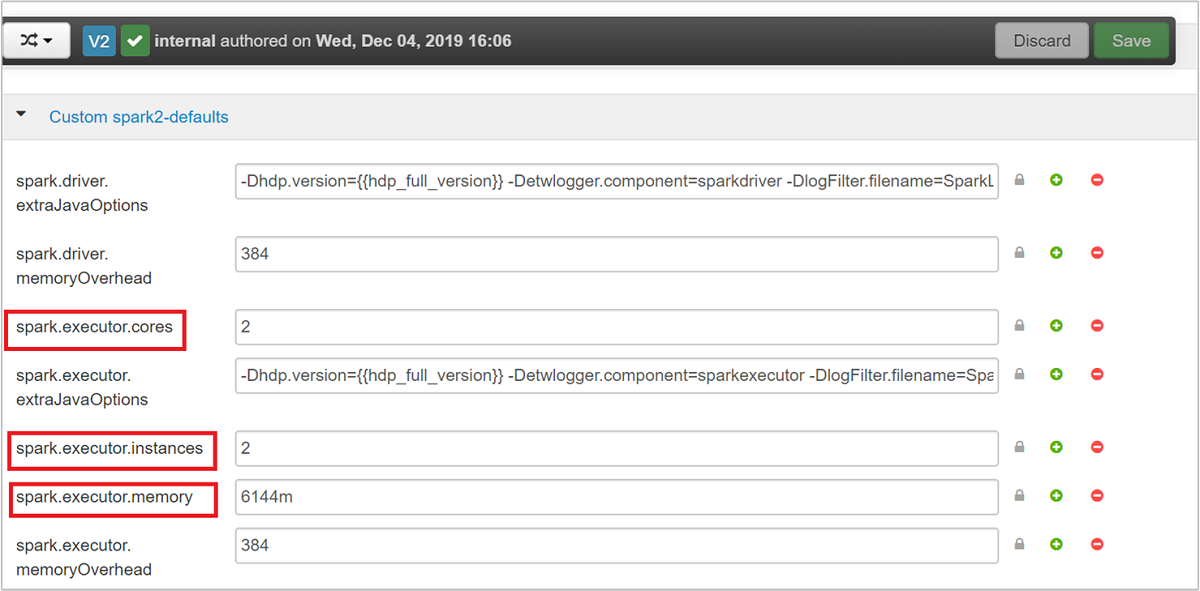
根據應用程式需求,可用於 Spark 組態的三個主要參數為 spark.executor.instances、spark.executor.cores 和 spark.executor.memory。 執行程式是針對 Spark 應用程式啟動的程序。 它會在背景工作角色節點上執行,並負責執行應用程式的工作。 執行程式的預設數目和每個叢集的執行程式大小,是根據背景工作角色節點數目和背景工作角色節點大小計算。 這項資訊會儲存在叢集前端節點上的 spark-defaults.conf。
這三個組態參數可以在叢集層級設定 (適用於在叢集執行的所有應用程式),或者也可以針對每個個別應用程式指定。
使用 Ambari UI 變更參數
從 Ambari UI 中,瀏覽至 [Spark2] > [設定] > [自訂 spark2-defaults]。
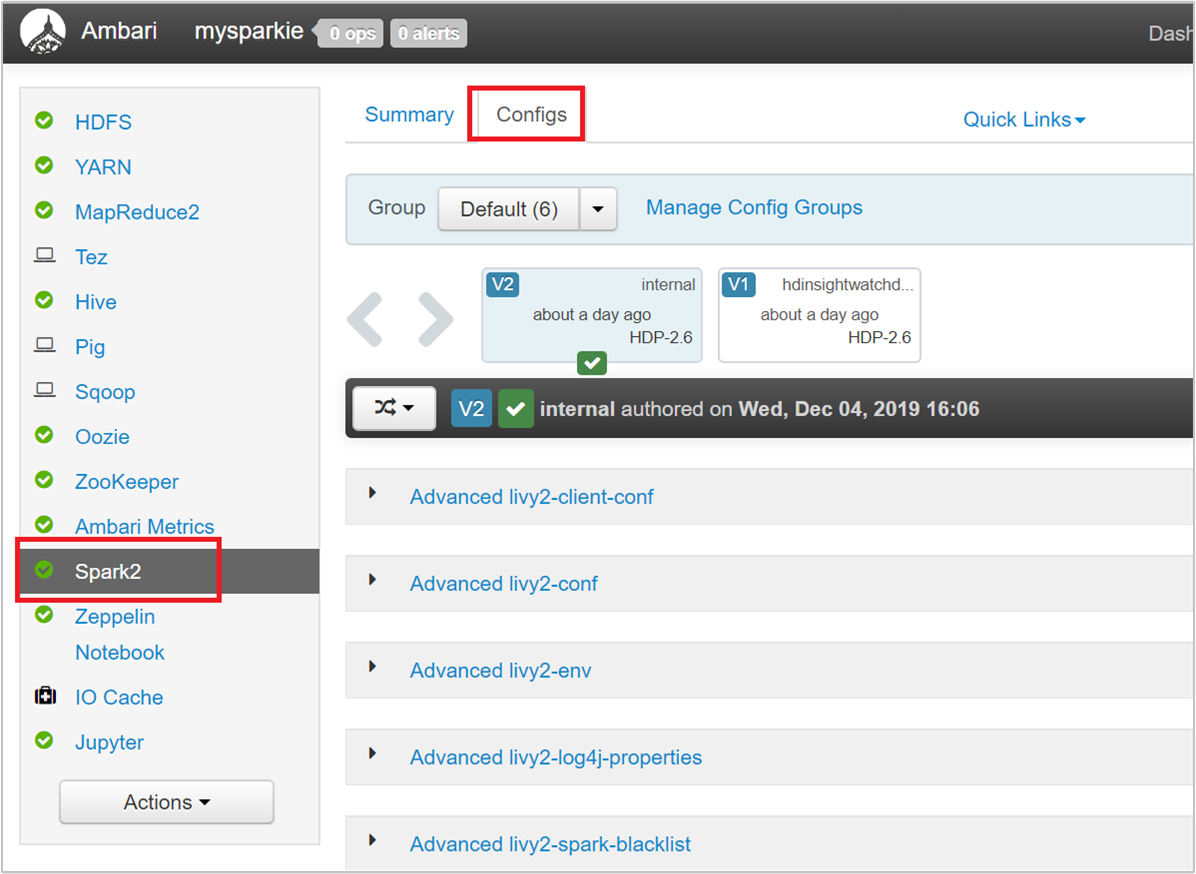
預設值適用於在叢集上同時執行 4 個 Spark 應用程式。 您可以從使用者介面變更這些值,如以下螢幕擷取畫面所示:
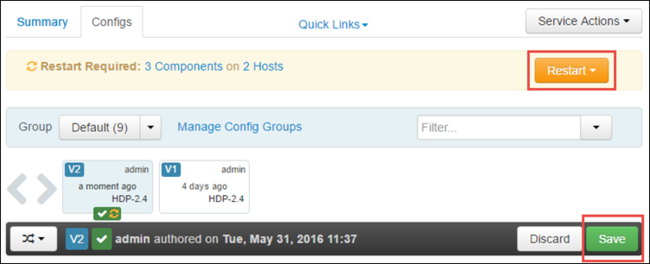
選取 [儲存] 以儲存設定變更。 在頁面頂端,系統會提示您重新啟動所有受影響的服務。 選取重新啟動。
變更 Jupyter Notebook 中所執行應用程式的參數
針對 Jupyter Notebook 中執行的應用程式,您可以使用 %%configure magic 進行設定變更。 在理想情況下,您必須在應用程式開頭進行此類變更,才能執行您的第一個程式碼儲存格。 這樣可確保組態會在 Livy 工作階段建立時套用至其中。 如果您想要變更應用程式中稍後的階段的組態,您必須使用 -f 參數。 不過,這麼做會讓應用程式中的所有進度遺失。
下列程式碼片段說明如何變更在 Jupyter 中執行之應用程式的設定。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
組態參數必須以 JSON 字串傳遞,且必須在 magic 之後的下一行,如範例資料行中所示。
使用 spark-submit 變更已提交應用程式的參數
下列命令是如何針對使用 spark-submit提交的批次應用程式變更組態參數的範例。
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
使用 cURL 變更已提交應用程式的參數
下列命令是一個範例,說明如何為使用 cURL 提交的批次應用程式變更設定參數。
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
注意
將 JAR 檔案複製到叢集儲存體帳戶。 請不要直接將 JAR 檔案複製到前端節點。
在 Spark Thrift 伺服器上變更這些參數
Spark Thrift 伺服器提供對 Spark 叢集的 JDBC/ODBC 存取,並且用來服務 Spark SQL 查詢。 像是 Power BI、Tableau 等等的工具,會使用 ODBC 通訊協定與 Spark Thrift 伺服器通訊,將 Spark SQL 查詢當作 Spark 應用程式執行。 建立 Spark 叢集時,會啟動 Spark Thrift 伺服器的兩個執行個體,每個前端節點上一個執行個體。 每個 Spark Thrift 伺服器會顯示為 YARN UI 中的 Spark 應用程式。
Spark Thrift 伺服器會使用 Spark 動態執行程式配置,因此不會使用 spark.executor.instances。 而是 Spark Thrift 伺服器會使用 spark.dynamicAllocation.maxExecutors 和 spark.dynamicAllocation.minExecutors 來指定執行程式計數。 設定參數 spark.executor.cores 和 spark.executor.memory 用來修改執行程式大小。 您可以變更這些參數,如下列步驟所示:
展開進階 spark2-thrift-sparkconf 類別以更新參數
spark.dynamicAllocation.maxExecutors和spark.dynamicAllocation.minExecutors。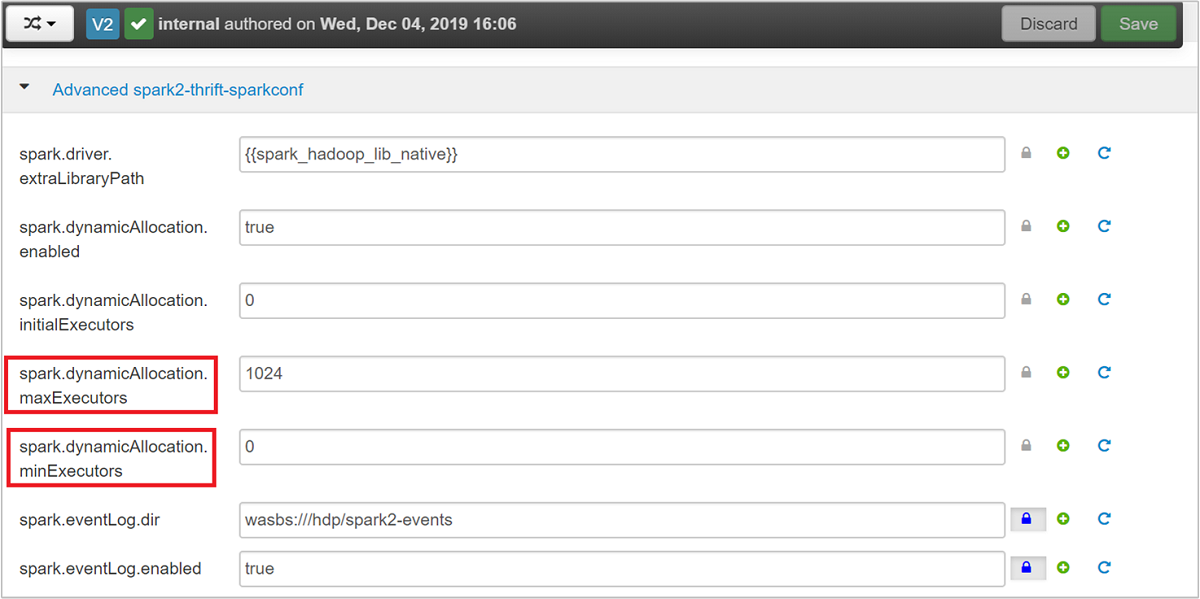
展開自訂 spark2-thrift-sparkconf 類別以更新參數
spark.executor.cores和spark.executor.memory。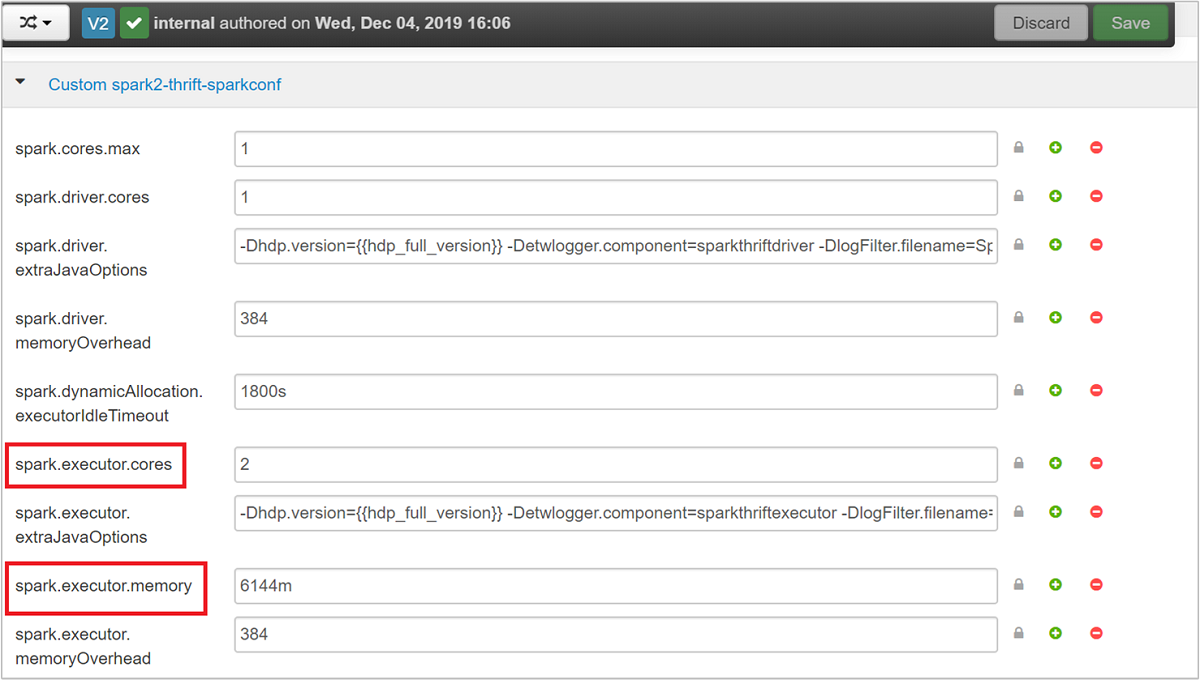
變更 Spark Thrift 伺服器的驅動程式記憶體
「Spark Thrift 伺服器」驅動程式記憶體是設定為前端節點 RAM 大小的 25%,其中假設前端節點的 RAM 大小總計大於 14 GB。 您可以使用 Ambari UI 來變更驅動程式記憶體設定,如以下螢幕擷取畫面所示:
從 Ambari UI 中,瀏覽至 [Spark2]>[設定]>[進階 spark2-env]。 然後提供 spark_thrift_cmd_opts 的值。
回收 Spark 叢集資源
由於會進行 Spark 動態配置,因此 Thrift 伺服器所使用的唯一資源是兩個應用程式主機的資源。 若要回收這些資源,您必須停止在叢集上執行的「Thrift 伺服器」服務。
從 Ambari UI 的左窗格中,選取 [Spark2]。
在下一個頁面中,選取 [Spark2 Thrift 伺服器]。
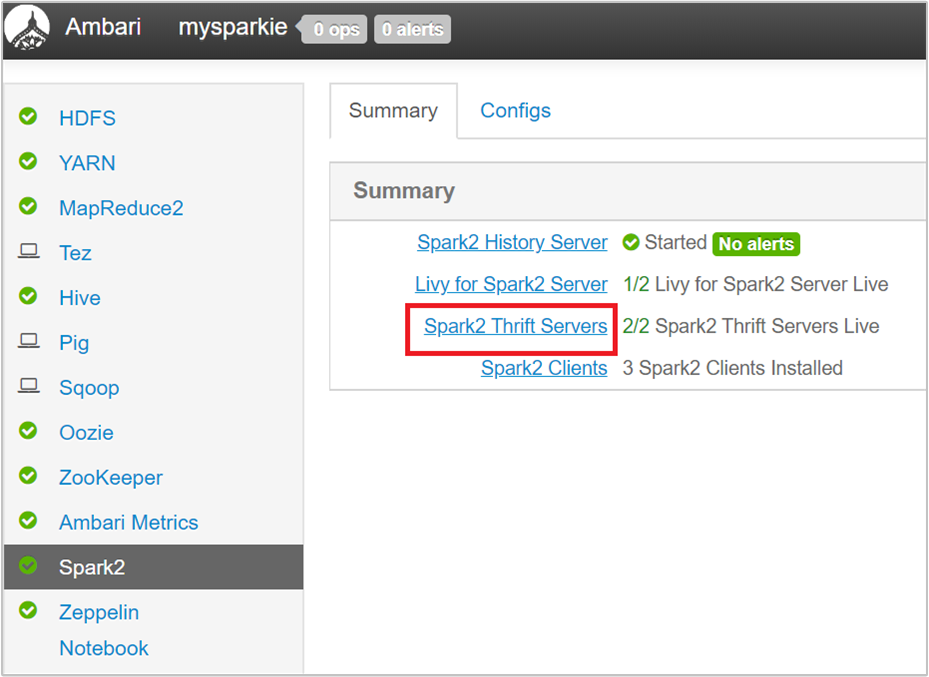
您應該會看到兩個前端節點,Spark 2 Thrift 伺服器正在該節點上執行。 選取其中一個前端節點。
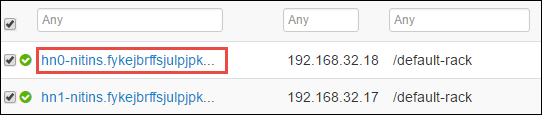
下一個頁面列出在該前端節點上執行的所有服務。 從清單中,選取 Spark 2 Thrift 伺服器旁邊的下拉式按鈕,然後選取 [停止]。
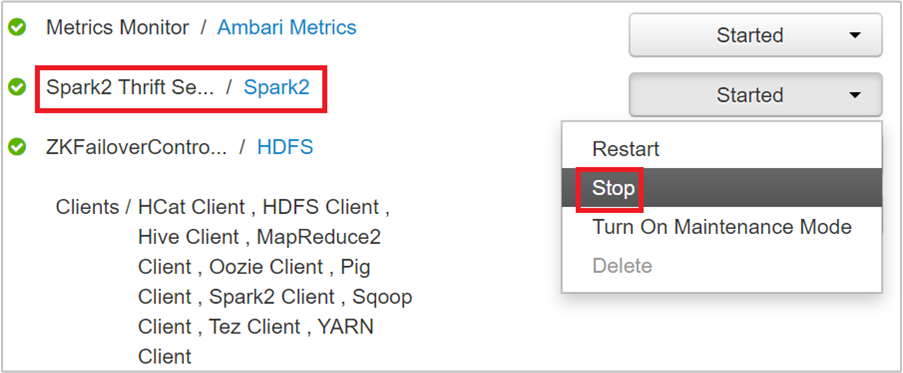
對其他前端節點重複這些步驟。
重新啟動 Jupyter 服務
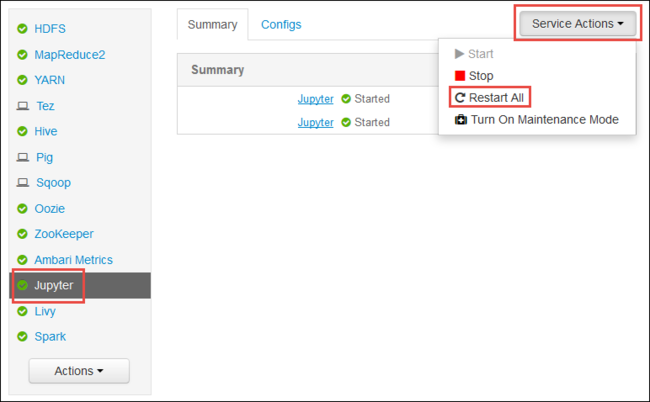
啟動 Ambari Web UI,如本文開頭所示。 從左側導覽窗格,依序選取 [Jupyter]、[服務動作] 和 [全部重新啟動]。 這會在所有前端節點上啟動 Jupyter 服務。
監視資源
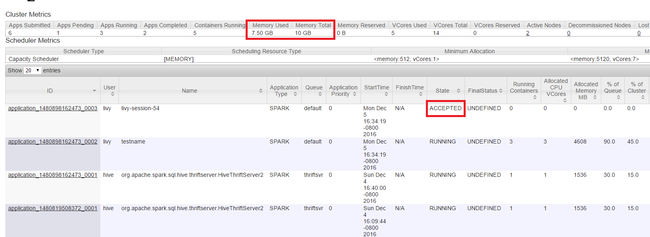
啟動 Yarn UI,如本文開頭所示。 在螢幕頂端的叢集計量資料表中,檢查[使用的記憶體] 的值和 [記憶體總計] 資料行。 如果這兩個值相當接近,可能會沒有足夠的資源來啟動下一個應用程式。 這同樣適用於 [使用的 VCores] 和 [VCores 總計] 資料行。 此外,在主要檢視中,如果應用程式一直維持在 [已接受] 狀態並未轉換成 [執行中] 或 [失敗] 狀態時,這也可能是表示其未取得足夠的資源來啟動。
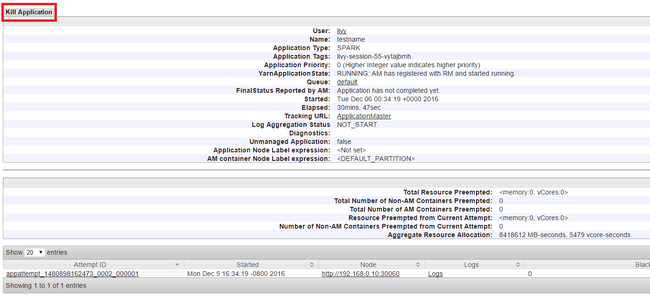
終止執行中的應用程式
在 Yarn UI 中,從左窗格中,選取 [執行中]。 從執行中應用程式的清單,決定要終止的應用程式,然後選取 [識別碼]。
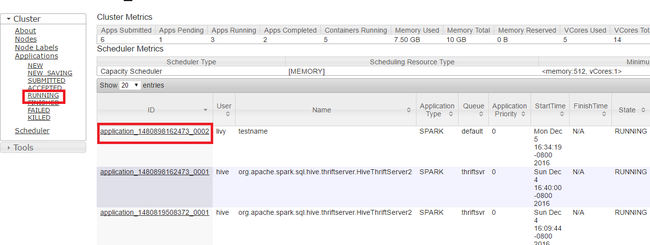
選取右上角的 [終止應用程式],然後選取 [確定]。
另請參閱
針對資料分析師
- Apache Spark 和機器學習服務:使用 HDInsight 中的 Spark,使用 HVAC 資料來分析建築物溫度
- Apache Spark 和機器學習服務:在 HDInsight 中使用 Spark 預測食品檢查結果
- 在 HDInsight 中使用 Apache Spark 進行網站記錄分析
- 在 HDInsight 中使用 Apache Spark 的 Application Insight 遙測資料分析
針對 Apache Spark 開發人員
- 使用 Scala 建立獨立應用程式
- 利用 Apache Livy 在 Apache Spark 叢集上遠端執行作業
- 使用 IntelliJ IDEA 的 HDInsight Tools 外掛程式來建立和提交 Spark Scala 應用程式
- 使用適用於 IntelliJ IDEA 的 HDInsight 工具外掛程式遠端偵錯 Apache Spark 應用程式
- 在 HDInsight 上搭配使用 Apache Zeppelin Notebook 和 Apache Spark 叢集
- 在適用於 HDInsight 的 Apache Spark 叢集中可供 Jupyter Notebook 使用的核心
- 搭配 Jupyter Notebook 使用外部套件
- 在電腦上安裝 Jupyter 並連接到 HDInsight Spark 叢集