Apache Spark 串流概觀
Apache Spark 串流可在 HDInsight Spark 叢集上處理資料流。 此功能保證任何輸入資訊都會經過一次處理,即使發生節點失敗情形也一樣。 Spark 串流是一種長時間執行的作業,會從各種來源接收輸入資料,包括 Azure 事件中樞在內。 此外還有:Azure IoT 中樞、Apache Kafka、Apache Flume、Twitter、ZeroMQ、原始 TCP 通訊端,或藉由監視 Apache Hadoop YARN 檔案系統。 與單純事件導向程序不同,Spark 串流會以時段將輸入資料分為不同批次。 例如 2 秒配量,然後使用對應、縮減、聯結和擷取作業轉換每個資料批次。 Spark 串流會接著將已轉換的資料寫出至檔案系統、資料庫、儀表板及主控台。
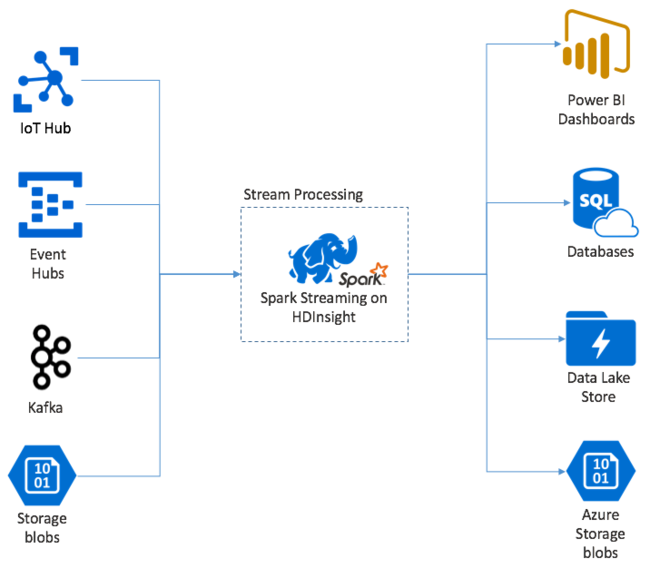
Spark 串流應用程式必須等待幾毫秒,才可收集事件的每個 micro-batch,然後才能傳送該批次以進行處理。 相較之下,事件驅動的應用程式會立即處理每個事件。 而 Spark 串流通常會延遲幾秒鐘。 微批次方法的優點是可更有效率的處理資料和更簡易的彙總運算。
DStream 簡介
Spark 串流會使用名為 DStream 的離散化資料流表示傳入資料的連續資料流。 DStream 可從輸入來源建立,例如事件中樞或 Kafka。 或者在另一個 DStream 上套用轉換。
DStream 會在原始事件資料的頂端提供抽象層。
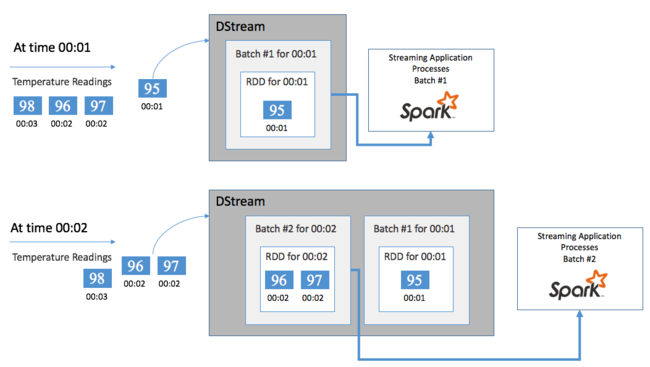
先以單一事件為例,例如從連接的控溫器讀取溫度。 當此事件抵達 Spark 串流應用程式時,系統會以可靠的方式儲存此事件,也就是在多個節點上複寫此事件。 此容錯方式可確保任何單一節點的錯誤不會導致事件遺失。 Spark 核心使用的資料結構會將資料分散在叢集中的多個節點之間。 而每個節點通常會維護自己的記憶體內部資料以確保最佳效能。 此資料結構稱為彈性分散式資料集 (resilient distributed dataset, RDD)。
每個 RDD 皆代表在使用者定義的時間範圍 (稱為「批次間隔」) 內收集的事件。 當每個批次間隔過去後,新的 RDD 就會產生,並包含該間隔中的所有資料。 系統會將這組連續的 RDD 收集到 DStream。 例如,如果批次間隔長度為一秒,您的 DStream 就會每秒發出包含一個 RDD 的批次,該 RDD 會包含在這一秒期間內嵌的所有資料。 處理 DStream 時,溫度事件就會出現在這些批次的其中一個。 Spark 串流應用程式會處理包含事件的批次,並在最後處理儲存在每個 RDD 中的資料。
Spark 串流應用程式的結構
Spark 串流應用程式是長時間執行的應用程式,其會接收來自內嵌來源的資料, 接著套用轉換以處理資料,然後將資料推送至一個或多個目的地。 Spark 串流應用程式的結構包含一個靜態部分和一個動態部分。 靜態部分定義了資料的來源、要在資料上進行的處理, 以及結果的目的地。 動態部分會無限期執行應用程式,等候停止訊號。
例如,以下簡單應用程式會透過 TCP 通訊端接收一行文字,並計算每個字彙出現的次數。
定義應用程式
應用程式邏輯定義包含四個步驟:
- 建立 StreamingContext。
- 從 StreamingContext 建立 DStream。
- 將轉換套用至 DStream。
- 輸出結果。
此定義是靜態的,而且在您執行應用程式之前不會處理任何資料。
建立 StreamingContext
從指向您叢集的 SparkContext 建立 StreamingContext。 建立 StreamingContext 時,您可以指定批次大小 (以秒為單位),例如:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
建立 DStream
請使用 StreamingContext 執行個體來為您的輸入來源建立輸入 DStream。 在此案例中,應用程式會監看新檔案在預設連結儲存體中的出現次數。
val lines = ssc.textFileStream("/uploads/Test/")
套用轉換
在 DStream 上套用轉換後,您就可以實作處理作業。 此應用程式一次會收到來自檔案的一行文字,並將每行分割為字組。 然後使用 map-reduce 模式來計算每個字組出現的次數。
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
輸出結果
藉由套用輸出作業,將轉換結果推送至目的地系統。 在此案例中,會將透過計算產生的每個執行結果顯示在主控台輸出中。
wordCounts.print()
執行應用程式
啟動串流應用程式並執行,直到收到終止訊號。
ssc.start()
ssc.awaitTermination()
如需 Spark 串流 API 的詳細資訊,請參閱 Apache Spark 串流程式設計指南。
下列的範例應用程式皆各自獨立,因此您可以在 Jupyter Notebook 中加以執行。 此範例會在 DummySource 類別中建立模擬資料來源,此類別會輸出計數器的值,以及每五秒輸出一次目前的時間 (以毫秒為單位)。 新 StreamingContext 物件的批次間隔為 30 秒。 每個批次建立時,串流應用程式都會檢查產生的 RDD。 然後將 RDD 轉換為 Spark DataFrame,透過 DataFrame 並建立一個暫存資料表。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
上述應用程式啟動之後,請等候大約 30 秒。 接著您便可以定期查詢 DataFrame,以查看目前在批次中的一組值,例如使用下列 SQL 查詢:
%%sql
SELECT * FROM demo_numbers
產生的輸出看起來會類似以下輸出:
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
一共有六個值,因為 DummySource 每隔 5 秒就會建立一個值,而應用程式是每隔 30 秒便發出一個批次。
滑轉時間範圍
若要在 DStream 上彙總某一段時間的計算 (例如取得過去 2 秒的平均溫度),您可以使用 Spark 串流隨附的 sliding window 作業。 滑動時間範圍具有持續時間 (時間範圍長度) 及間隔,系統會在該期間內對該時間範圍的內容進行評估 (滑動間隔)。
滑動時間範圍可以重疊,例如,您可以定義一個長度為 2 秒且每秒滑動一次的時間範圍。 此操作表示每次您執行彙總計算時,該時間範圍都會包含前一個時間範圍最後一秒的資料, 以及下一秒的任何新資料。
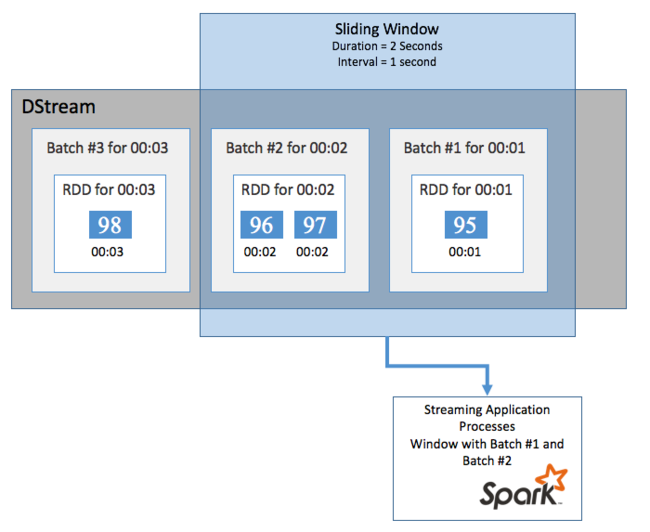
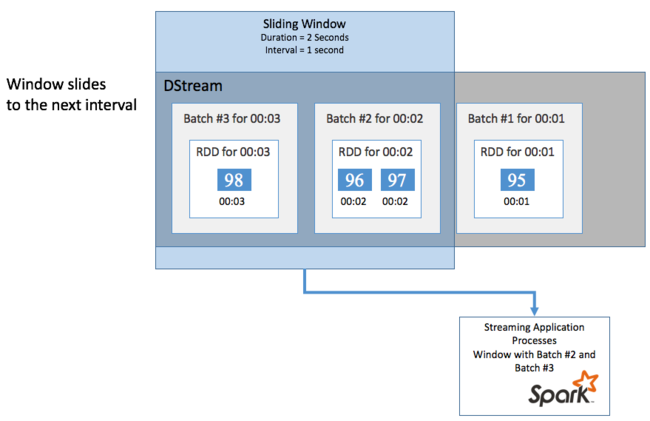
下列範例會更新使用 DummySource 的程式碼,以將批次收集至持續時間為一分鐘,且滑動為一分鐘的時間範圍內。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
在第一分鐘之後,會有 12 個項目 - 在該時間範圍內收集的兩個批次中,每一個批次各有 6 個項目。
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
可在 Spark 串流 API 中使用的滑動時間範圍函式包括 window、countByWindow、reduceByWindow 和 countByValueAndWindow。 如需有關這些函式的詳細資料,請參閱 DStream 上的轉換 \(英文\)。
檢查點檢查
為了提供備援和容錯,Spark 串流會藉由檢查點來確保串流處理即使在發生節點錯誤時,也能夠持續而不中斷。 Spark 會在耐久型儲存體 (Azure 儲存體或 Data Lake Storage) 上建立檢查點。 這些檢查點會儲存有關串流應用程式的中繼資料 (例如設定)、由應用程式定義的作業, 另外還有任何已排入佇列但尚未處理的批次。 有時檢查點也會包括儲存 RDD 中的資料,以便更快速從 Spark 所管理的 RDD 中現有內容重建資料狀態。
部署 Spark 串流處理應用程式
您通常會在本機將 Spark 串流應用程式建置到 JAR 檔案中。 然後將 JAR 檔案複製到預設的連結儲存體,以將它部署到 HDInsight 上的 Spark。 您可以使用 POST 作業,藉由叢集提供的 LIVY REST API 來啟動應用程式。 POST 的主體包含 JSON 文件,此文件會提供 JAR 路徑, 以及類別名稱 (此類別的主要方法會定義和執行串流應用程式) 和選擇性的作業資源要求 (例如執行程式、記憶體及核心的數量), 另外還有您應用程式程式碼所需的任何組態設定。
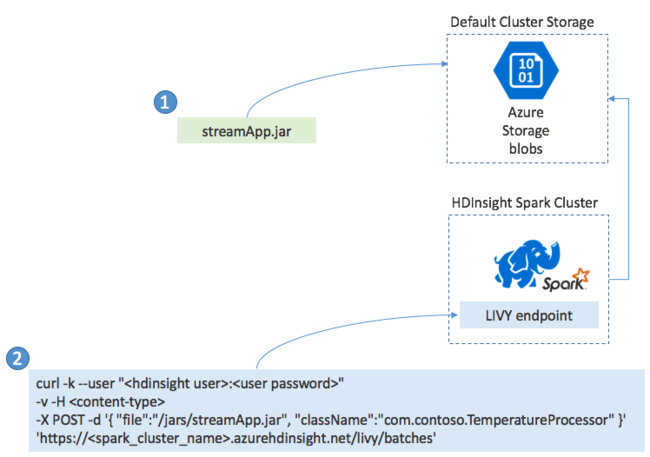
您也可以藉由 LIVY 端點,使用 GET 要求來檢查所有應用程式的狀態。 最後,您可以對 LIVY 端點發出 DELETE 要求,來終止執行中的應用程式。 如需 LIVY API 的詳細資料,請參閱使用 Apache LIVY 執行遠端作業
下一步
- 在 HDInsight 中建立 Apache Spark 叢集
- Apache Spark Streaming Programming Guide (Apache Spark 串流程式設計指南)
- Apache Spark 結構化串流的概觀
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應