評估模型元件
本文說明 Azure 機器學習 設計工具中的元件。
使用此元件來測量定型模型的精確度。 您提供的數據集包含從模型產生的分數,而 評估模型 元件會計算一組業界標準評估計量。
評估模型所傳回的計量取決於您正在評估的模型類型:
- 分類模型
- 回歸模型
- 叢集模型
提示
如果您不熟悉模型評估,建議您使用 Stephen Elston 博士的影片系列,作為 EdX 機器學習課程的一部分。
如何使用評估模型
連線評分模型的評分數據集輸出,或將數據指派給叢集的結果數據集輸出到評估模型的左側輸入埠。
注意
如果使用「選取數據集中的數據行」等元件來選取輸入數據集的一部分,請確定實際標籤數據行(用於定型)、「評分機率」數據行和「評分標籤」數據行存在,以計算 AUC、二元分類/異常偵測的精確度等計量。 實際標籤數據列「評分標籤」數據行存在,可計算多類別分類/回歸的計量。 'Assignments' 數據行,數據行 'DistancesToClusterCenter no.X' (X 是心心索引,範圍從 0,...,心心數-1)存在,以計算群集的計量。
重要
- 若要評估結果,輸出數據集應該包含符合評估模型元件需求的特定分數數據行名稱。
- 數據
Labels行會被視為實際標籤。 - 針對回歸工作,要評估的數據集必須有一個數據行,名為
Regression Scored Labels,代表評分的標籤。 - 針對二元分類工作,要評估的數據集必須有兩個數據行,名為
Binary Class Scored Labels,Binary Class Scored Probabilities分別代表評分標籤和機率。 - 針對多重分類工作,要評估的數據集必須有一個數據行,名為
Multi Class Scored Labels,代表評分的標籤。 如果上游元件的輸出沒有這些數據行,您需要根據上述需求進行修改。
[選擇性]連線將第二個模型指派給叢集之評分模型或結果數據集輸出的評分數據集輸出,以將第二個模型指派給評估模型的正確輸入埠。 您可以輕鬆地比較相同數據上兩個不同模型的結果。 這兩個輸入演算法應該相同演算法類型。 或者,您可以將兩個不同回合的分數與不同的參數比較在相同數據上。
注意
演算法類型是指 '機器學習 Algorithms' 底下的 'Two-class Classification'、'Multi-class Classification'、'Regression'、'Clustering'。
提交管線以產生評估分數。
結果
執行 評估模型之後,選取元件以開啟右側的 [評估模型 ] 瀏覽面板。 然後,選擇 [ 輸出 + 記錄] 索引標籤,然後在該 索引標籤上,[資料輸出 ] 區段有數個圖示。 可視化圖示具有條形圖圖示,是查看結果的第一種方式。
針對二元分類,按兩下 [可視化 ] 圖示之後,即可將二進位混淆矩陣可視化。 針對多重分類,您可以在 [輸出 + 記錄] 索引標籤底下找到混淆矩陣繪圖檔案,如下所示:
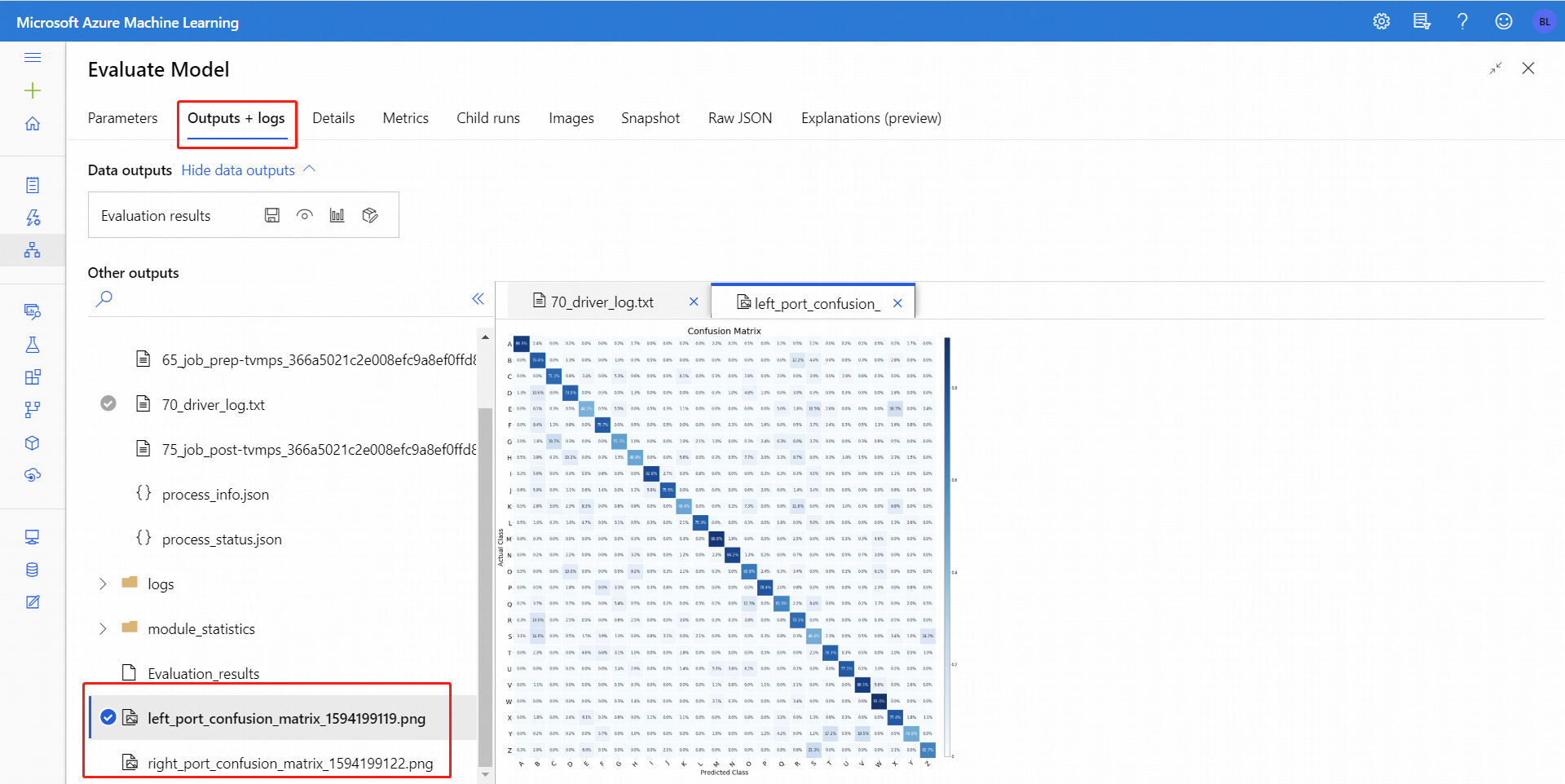
如果您將數據集連接到評估模型的兩個輸入,結果會包含這兩組數據或兩個模型的計量。 附加至左埠的模型或數據會先出現在報表中,後面接著數據集的計量,或附加在右側埠上的模型。
例如,下圖代表兩個叢集模型的結果比較,這些模型建置在相同數據上,但具有不同的參數。
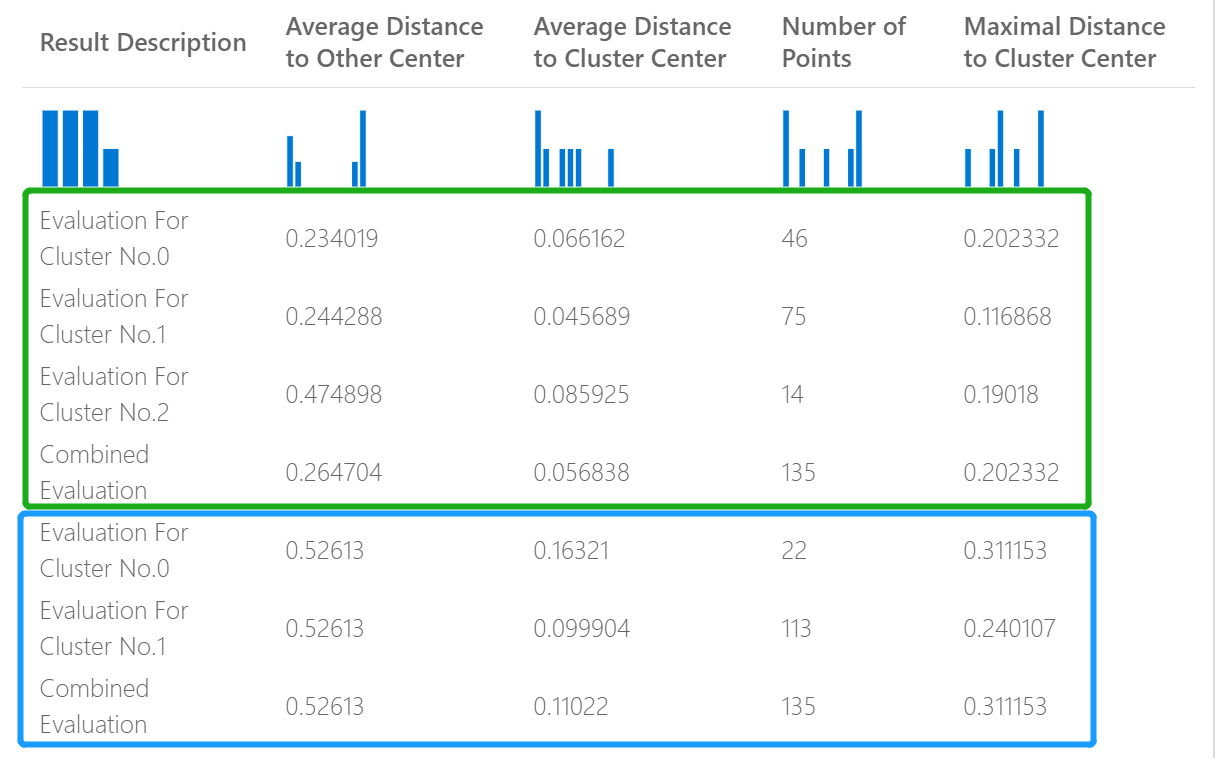
因為這是群集模型,因此評估結果會不同於您比較兩個回歸模型的分數,或比較兩個分類模型。 不過,整體呈現方式相同。
計量
本節說明針對支持與評估模型搭配使用的特定模型類型所傳回的計量:
分類模型的計量
評估二元分類模型時會報告下列計量。
精確度 會將分類模型的良好性測量為真實結果與總案例的比例。
精確度 是所有正結果的真結果比例。 Precision = TP/(TP+FP)
召回 率是實際擷取之相關實例總數的分數。 召回 = TP/(TP+FN)
F1 分數 會計算為 0 到 1 之間的有效位數和召回率加權平均值,其中理想的 F1 分數值為 1。
AUC 會測量以y軸上以真判繪製的曲線下的區域,並在 x 軸上測量誤判。 此計量很有用,因為它提供單一數位,可讓您比較不同類型的模型。 AUC 是分類臨界值不變。 它會測量模型預測的品質,而不論選擇何種分類閾值。
回歸模型的計量
針對回歸模型傳回的計量是設計來估計錯誤的數量。 如果觀察到的值與預測值之間的差異很小,模型就會被視為符合數據。 不過,查看殘差的模式(任何一個預測點與其對應的實際值之間的差異),可以告訴您模型中的潛在偏差。
下列計量報告用於評估線性回歸模型。 其他回歸輸入模型,例如 快速樹系分位數回歸 可能會有不同的計量。
平均絕對誤差 (MAE) 測量預測對實際結果有多接近;因此,較低的分數比較好。
根平均平方誤差 (RMSE) 會建立單一值,以摘要模型中的錯誤。 藉由將差異相等化,計量會忽略過度預測與預測不足之間的差異。
相對絕對誤差 (RAE) 是預期與實際值之間的相對絕對差異;相對因為平均差除以算術平均數。
相對平方誤差 (RSE) 同樣地將預測值的總平方誤差除以實際值的總平方誤差來正規化。
判斷係數,通常稱為 R2,以 0 到 1 之間的值表示模型的預測能力。 零表示模型是隨機的(不解釋任何內容):1 表示有一個完美的適合。 不過,在解譯 R2 值時應該謹慎,因為低值可能完全正常,而且高值可能可疑。
叢集模型的計量
因為群集模型在許多方面與分類和回歸模型有很大的不同, 因此評估模型 也會針對群集模型傳回一組不同的統計數據。
叢集模型傳回的統計數據會描述指派給每個叢集的數據點數目、叢集之間的分隔量,以及每個叢集內數據點的分組程度。
叢集模型的統計數據會透過整個數據集來平均,而其他數據列則包含每個叢集的統計數據。
下列計量報告用於評估叢集模型。
數據行中的分數[ 平均距離至其他中心],代表叢集中每個點的平均距離是所有其他群集的心心。
數據行中分數「 叢集中心的平均距離」,代表叢集中所有點與該叢集距心的接近度。
[ 點 數] 數據行會顯示指派給每個叢集的數據點數目,以及任何叢集中的數據點總數。
如果指派給叢集的數據點數目小於可用的數據點總數,表示數據點無法指派給叢集。
數據行中的分數「 叢集中心最大距離」,代表每個點與該點群集中距心之間的最大距離。
如果這個數位很高,這可能表示叢集廣泛分散。 您應該檢閱此統計數據與 叢集中心 的平均距離,以判斷叢集的分佈。
結果 每個區段底部的 [合併評估 分數] 會列出在該特定模型中建立之叢集的平均分數。