適用於: Machine Learning Studio (傳統版)
Machine Learning Studio (傳統版)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您依該日期轉換至 Azure Machine Learning 。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
在本教學課程中,您會深入瞭解開發預測性分析解決方案的程式。 您在 機器學習 Studio 中開發簡單的模型(傳統版)。 接著,您將模型部署為 機器學習 Web 服務。 此已部署的模型可以使用新的數據進行預測。 本教學課程是 三部分教學課程系列的第一部分。
假設您需要根據他們在信用申請上提供的資訊來預測個人的信用風險。
信用風險評估是一個複雜的問題,但本教學課程會簡化它一點。 您將使用它作為如何使用 機器學習 Studio 建立預測性分析解決方案的範例(傳統版)。 您將使用此解決方案的 機器學習 Studio(傳統版)和 機器學習 Web 服務。
在本三部分教學課程中,您會從公開可用的信用風險數據開始。 您接著會開發並定型預測模型。 最後,您會將模型部署為 Web 服務。
在本教學課程的這個部分中,您會:
- 建立 機器學習 Studio (傳統) 工作區
- 上傳現有的數據
- 建立實驗
接著,您可以使用此實驗來 定型第 2 部分中的模型 ,然後在 第 3 部分中部署模型。
必要條件
本教學課程假設您之前至少使用了一次 機器學習 Studio(傳統版),而且您已對機器學習概念有一些瞭解。 但它不會認為你在這兩方面都是專家。
如果您之前從未使用過 Machine Learning Studio(傳統版),您可能想要從快速入門開始,在 Machine Learning Studio 中建立您的第一個數據科學實驗(傳統版)。 快速入門將帶您初次使用傳統版機器學習 Studio。 它說明如何將模組拖放至實驗、將它們連接在一起、執行實驗,以及查看結果的基本概念。
提示
您可以在 Azure AI 資源庫中找到您在本教學課程中開發的實驗工作複本。 移至 教學課程 - 預測信用風險 ,然後按兩下 [在 Studio 中開啟 ],將實驗的復本下載到Machine Learning Studio (傳統) 工作區。
建立 機器學習 Studio (傳統) 工作區
若要使用 機器學習 Studio (傳統版),您需要有 機器學習 Studio (傳統) 工作區。 此工作區包含您建立、管理及發佈實驗所需的工具。
若要建立工作區,請參閱 建立和共用Machine Learning Studio (傳統) 工作區。
建立工作區之後,請開啟 機器學習 Studio (傳統版) (https://studio.azureml.net/Home)。 如果您有多個工作區,您可以在視窗右上角的工具列中選取工作區。
提示
如果您是工作區的擁有者,您可以邀請其他人前往工作區來共用您正在處理的實驗。 您可以在 [ 設定 ] 頁面上的 Machine Learning Studio(傳統版)中執行此動作。 您只需要每個使用者Microsoft帳戶或組織帳戶。
在 [ 設定] 頁面上,按兩下 [ 使用者],然後按下視窗底部的 [ 邀請更多使用者 ]。
上傳現有的數據
若要開發信用風險的預測模型,您需要可用來定型然後測試模型的數據。 在本教學課程中,您將使用UC Irvine 機器學習存放庫中的“UCI Statlog(德文信用數據)數據集”。 您可以在這裡找到:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
您將使用名為 german.data 的檔案。 將此檔案下載到本機硬碟。
german.data 數據集包含 1000 個過去申請點數的 20 個變數數據列。 這 20 個變數代表數據集的特徵集( 特徵向量),可提供每個信用申請人的識別特性。 每個數據列中的另一個數據行代表申請人的計算信用風險,700名申請人被識別為低信用風險,300人視為高風險。
UCI 網站提供此數據特徵向量屬性的描述。 此數據報括財務資訊、信用記錄、就業狀態和個人資訊。 對於每個申請人,已給予二進位評分,指出他們是低或高信用風險。
您將使用此資料來定型預測性分析模型。 完成時,您的模型應該能夠接受新個人的特徵向量,並預測它們是否為低或高信用風險。
這裡有一個有趣的轉折。
UCI 網站上的數據集描述提到,如果您錯誤分類個人的信用風險,會產生何種成本。 如果模型針對實際為低信用風險的人預測高信用風險,則模型已進行誤分類。
對金融機構來說,相反的誤分類會帶來五倍的成本:即當模型預測某個實際上是高信用風險的人為低信用風險時。
因此,您想要將模型定型,如此一來,這種誤判類型的成本會高於另一種方式誤判的五倍。
在實驗中訓練模型時,其中一個簡單的方法是將代表高信用風險的資料複製五次。
然後,如果模型在實際為高風險時將某人誤判為低信用風險,則模型會針對每個重複項目執行相同的錯誤分類五次。 這會增加訓練結果中此錯誤的成本。
轉換數據集格式
原始資料集使用空白分隔格式。 機器學習 Studio(傳統版)較適合使用逗號分隔值 (CSV) 檔案,因此您將以逗號取代空格來轉換數據集。
有許多方式可以轉換此數據。 其中一種方式是使用下列 Windows PowerShell 命令:
cat german.data | %{$_ -replace " ",","} | sc german.csv
另一種方式是使用 Unix sed 命令:
sed 's/ /,/g' german.data > german.csv
在這兩種情況下,您已在名為 german.csv 的檔案中建立逗號分隔版本的數據,您可以在實驗中使用。
將資料集上傳至 機器學習 Studio(傳統版)
將數據轉換成 CSV 格式之後,您必須將其上傳至 機器學習 Studio (傳統版)。
開啟 機器學習 Studio (傳統) 首頁 (https://studio.azureml.net)。
單擊功能表
 。在視窗左上角,單擊 [Azure Machine Learning],選取 [Studio],然後登入。
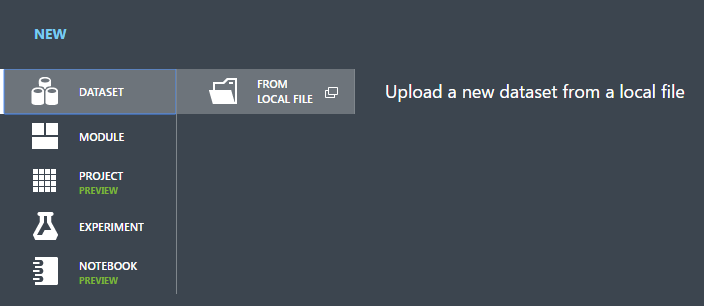
。在視窗左上角,單擊 [Azure Machine Learning],選取 [Studio],然後登入。按兩下視窗底部的 [+新增 ]。
選取 數據集。
選取 從本機檔案。
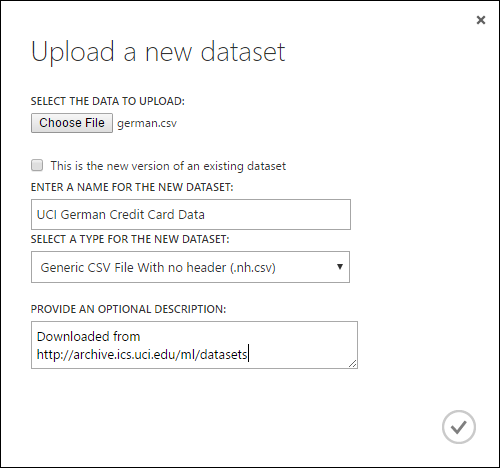
在 [ 上傳新的數據集] 對話框中,按兩下 [瀏覽],然後尋找您所建立 german.csv 檔案。
輸入數據集的名稱。 在本教學課程中,請將其稱為「UCI 德文信用卡數據」。
針對數據類型,選取 [沒有標頭的一般 CSV 檔案] (.nh.csv)。
如果您想要的話,請新增描述。
按一下[確定]勾選標記。
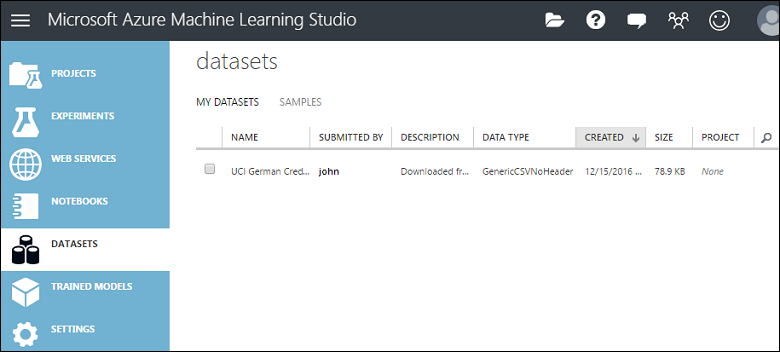
這會將數據上傳至數據集模組,您可以在實驗中使用。
您可以按兩下 Studio (傳統) 視窗左側的 [ 資料集 ] 索引標籤,來管理已上傳至 Studio (傳統版) 的資料集。
如需將其他類型的數據匯入實驗的詳細資訊,請參閱將定型數據匯入 Machine Learning Studio(傳統版)。
建立實驗
本教學課程的下一步驟是在 Machine Learning Studio(經典版)中建立使用您所上傳的資料集的實驗。
在 Studio(傳統版)中,按兩下視窗底部的 [+新增 ]。
選取 [實驗],然後選取 [空白實驗]。
選取畫布頂端的默認實驗名稱,並將它重新命名為有意義的專案。

提示
最好在 [屬性] 窗格中填入實驗的 [摘要] 和 [描述]。 這些屬性可讓您記錄實驗,讓稍後查看實驗的任何人都可以瞭解您的目標和方法。

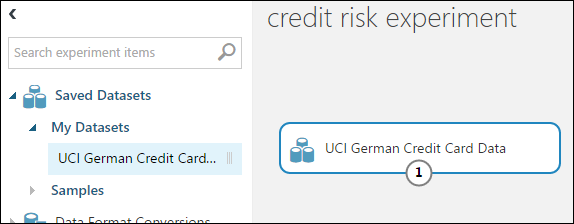
在實驗畫布左側的模組調色盤中,展開 [ 已儲存的數據集]。
尋找您在 [我的數據集 ] 底下建立的數據集,並將其拖曳到畫布上。 您也可以在調色盤上方的 [ 搜尋 ] 方塊中輸入名稱來尋找資料集。
準備資料
您可以檢視整個數據集的前 100 個數據列和一些統計數據:按兩下數據集的輸出埠(底部的小圓圈),然後選取 [ 可視化]。
因為數據文件沒有包含數據行標題,Studio(傳統版)已提供泛型標題(Col1、Col2 等)。 建立模型並不需要好標題,但它們可讓您更輕鬆地在實驗中使用數據。 此外,當您最終在 Web 服務中發佈此模型時,欄位名稱有助於服務用戶識別欄。
您可以使用 編輯元資料 模組來新增資料列標題。
您可以使用 編輯元數據 模組來變更與數據集相關聯的元數據。 在此情況下,您可以使用它為數據行標題提供更易記的名稱。
若要使用 [編輯元數據],您必須先指定要修改的數據行(在此案例中為全部數據行。接下來,您可以指定要對這些資料行執行的動作(在此案例中,變更數據行標題。)
在模組選擇區中,於 [ 搜尋 ] 方塊中輸入 「metadata」。。 編輯元數據會出現在模組清單中。
按兩下 [ 編輯元數據] 模組並將其拖曳到畫布上,並將它放在您稍早新增的數據集下方。
將數據集連接到 編輯元數據:按兩下數據集的輸出埠(資料集底部的小圓圈),拖曳至 編輯元數據 的輸入埠(模組頂端的小圓圈),然後放開滑鼠按鈕。 即使您在畫布上四處移動,數據集和模組仍保持連線。
實驗現在看起來應該像這樣:
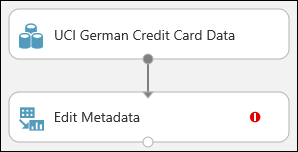
紅色驚嘆號表示您尚未設定此課程模組的屬性。 您接下來會去做。
提示
您可以按兩下模組,輸入文字,將批註新增至模組中。 這可協助您一目了然地查看模組在實驗中執行的動作。 在此情況下,按兩下 [編輯元資料] 模組,然後輸入批註 「新增數據行標題」。 按兩下畫布上的任意位置以關閉文字框。 若要顯示批注,請按兩下模組上的向下箭號。
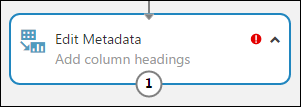
選取 [編輯元數據],然後在畫布右側的 [ 屬性 ] 窗格中,按兩下 [ 啟動數據行選取器]。
在 [ 選取數據行 ] 對話框中,選取 [可用的 數據行] 中的所有數據列,然後按兩下 > 以將它們移至 [選取的數據行]。 對話框看起來應該像這樣:
按兩下 [確定 ] 複選標記。
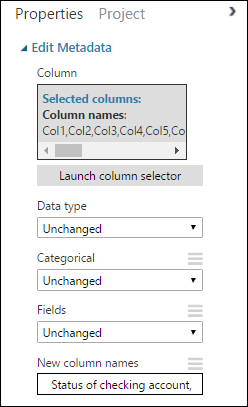
回到 [ 屬性] 窗格中,尋找 [新增數據行名稱 ] 參數。 在此欄位中,輸入資料集中 21 個資料行的名稱清單,並以逗號和數據行順序分隔。 您可以從 UCI 網站上的數據集檔取得資料行名稱,或為了方便起見,您可以複製並貼上下列清單:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit risk[屬性] 窗格看起來像這樣:
建立訓練和測試數據集
您需要一些數據來定型模型,有些則用來測試模型。 因此,在實驗的下一個步驟中,您會將數據集分割成兩個不同的數據集:一個用於定型模型,另一個用於測試模型。
若要這樣做,您可以使用 分割數據 模組。
根據預設,分割比例為 0.5,而且會設定 隨機分割 參數。 這表示隨機的一半數據是透過 分割數據 模組的一個埠輸出,而另一半數據則透過另一個埠輸出。 您可以調整這些參數以及 隨機種子 參數,以變更訓練和測試數據集之間的劃分。 在此範例中,您可以保持原樣。
提示
屬性第一個輸出數據集中的行比例決定了通過左輸出埠輸出的數據量。 例如,如果您將比率設定為 0.7,則 70% 的數據會透過左埠輸出,而 30% 則透過右側埠輸出。
按兩下 分割資料 模組並輸入批注:「訓練/測試資料分割50%」。
您可以視需要使用 分割數據 模組的輸出,但讓我們選擇使用左側輸出作為定型數據,並將右側輸出當做測試數據。
如前一步所述,將高信用風險錯誤分類為低的成本是將低信用風險錯誤分類為高的五倍。 若要考慮這一點,您會產生反映此成本函式的新數據集。 在新數據集中,每個高風險範例都會復寫五次,而不會復寫每個低風險範例。
您可以使用 R 程式代碼來執行此複寫:
尋找 [執行 R 腳本] 模組,並將其拖曳到實驗畫布上。
按兩下 [ 執行 R 文稿] 模組,然後輸入批注「設定成本調整」。
在 [ 屬性] 窗格中,刪除 R 文稿 參數中的預設文字,然後輸入下列腳本:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")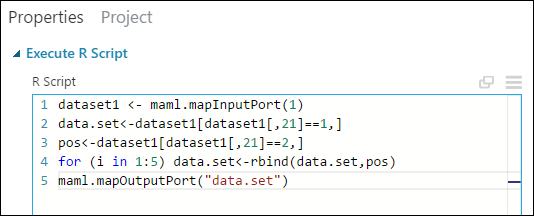
您必須針對 分割數據 模組的每個輸出執行相同的複寫作業,讓定型和測試數據具有相同的成本調整。 若要這樣做,最簡單的方式是複製您剛才建立的執行 R 腳本 模組,並將其連線到 分割數據 模組的其他輸出埠。
以滑鼠右鍵按兩下 [ 執行 R 腳稿] 模組,然後選取 [ 複製]。
以滑鼠右鍵按兩下實驗畫布,然後選取 [ 貼上]。
在畫布底部,按一下 執行。
提示
執行 R 文稿模組的複本包含與原始模組相同的腳本。 當您在畫布上複製並貼上模組時,複本會保留原始的所有屬性。
我們的實驗現在看起來像這樣:
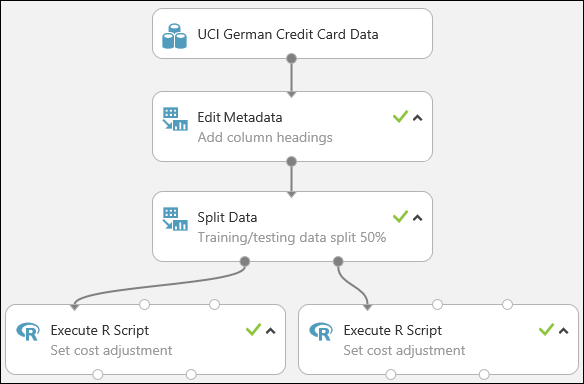
如需在實驗中使用 R 腳本的詳細資訊,請參閱 使用 R 擴充實驗。
清除資源
如果您不再需要使用本文建立的資源,請將其刪除,以避免產生任何費用。 瞭解如何在文章中 匯出和刪除產品內用戶數據。
下一步
在本教學課程中,您已完成下列步驟:
- 建立 機器學習 Studio (傳統) 工作區
- 將現有數據上傳至工作區
- 建立實驗
您現在已準備好為此數據定型和評估模型。