適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
將機器學習模型或管線定型,或是您從模型目錄找到符合需求的模型之後,您必須將其部署到生產環境,以便其他人將其用於「推斷」。 推斷是一種程序,可將新的輸入資料套用至機器學習模型或管線以產生輸出。 雖然這些輸出通常稱為「預測」,但推斷可用來產生其他機器學習工作的輸出,例如分類和叢集。 在 Azure Machine Learning 中,您會使用端點來執行推斷。
端點和部署
端點是一個穩定且持久的URL,可用來要求或叫用模型。 您將必要的輸入提供給端點,並取回輸出。 Azure Machine Learning 可讓您實作標準部署、在線端點和批次端點。 端點可提供:
- 穩定且持久的 URL (例如 endpoint-name.region.inference.ml.azure.com),
- 驗證機制,以及
- 授權機制。
部署是託管執行實際推斷之模型或元件所需的一組資源和電腦。 端點會包含部署,而針對線上和批次端點,一個端點可以包含數個部署。 部署可以裝載獨立的資產,並根據資產的需求取用不同的資源。 此外,端點具有路由機制,可將要求導向至其任何部署。
另一方面,Azure Machine Learning 中的某些端點類型會在其部署上取用專用資源。 若要執行這些端點,您必須在 Azure 訂用帳戶上擁有計算配額。 另一方面,某些模型支援無伺服器部署,使其不需要取用您訂用帳戶的配額。 針對無伺服器部署,您需要根據使用量付費。
直覺
假設您正在開發一個應用程式,該應用程式根據汽車的照片來預測汽車的類型和顏色。 針對此應用程式,具有特定認證的使用者會對 URL 提出 HTTP 要求,並提供汽車圖片作為要求的一部分。 在傳回中,使用者會取得回應,其中包含汽車的類型和顏色作為字串值。 在此案例中,URL 會作為端點。
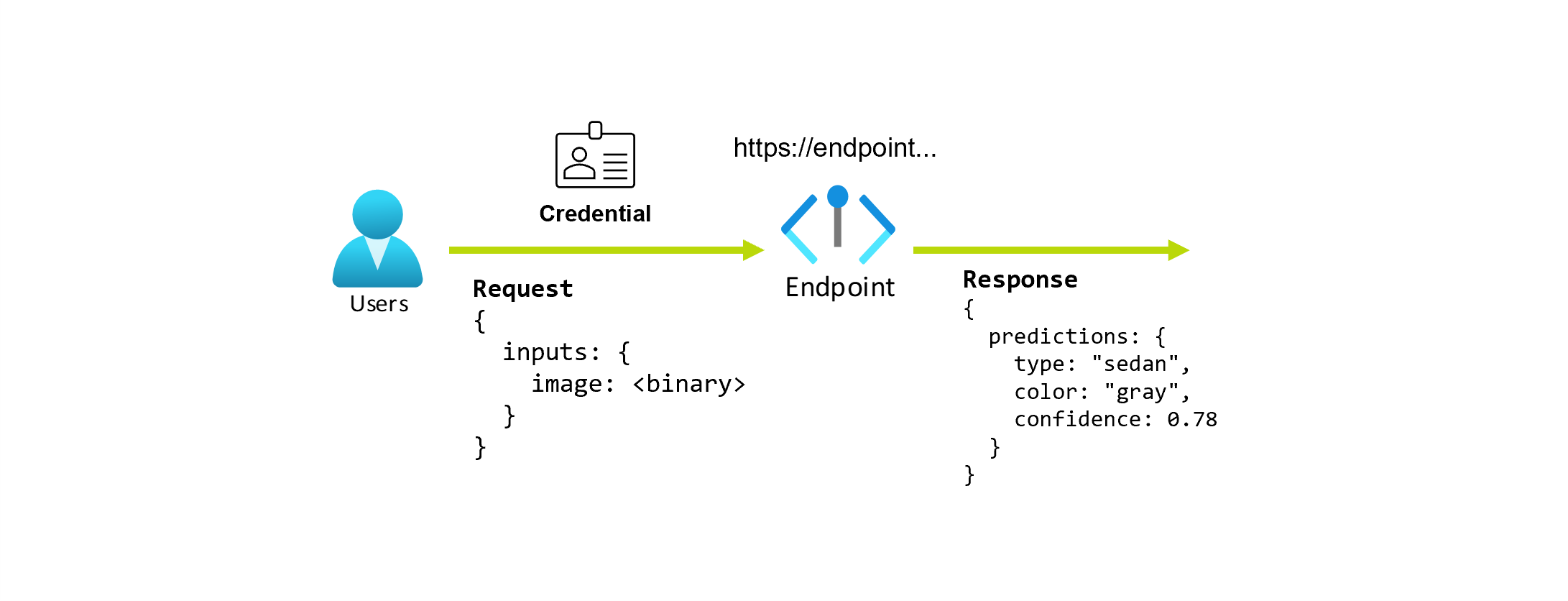
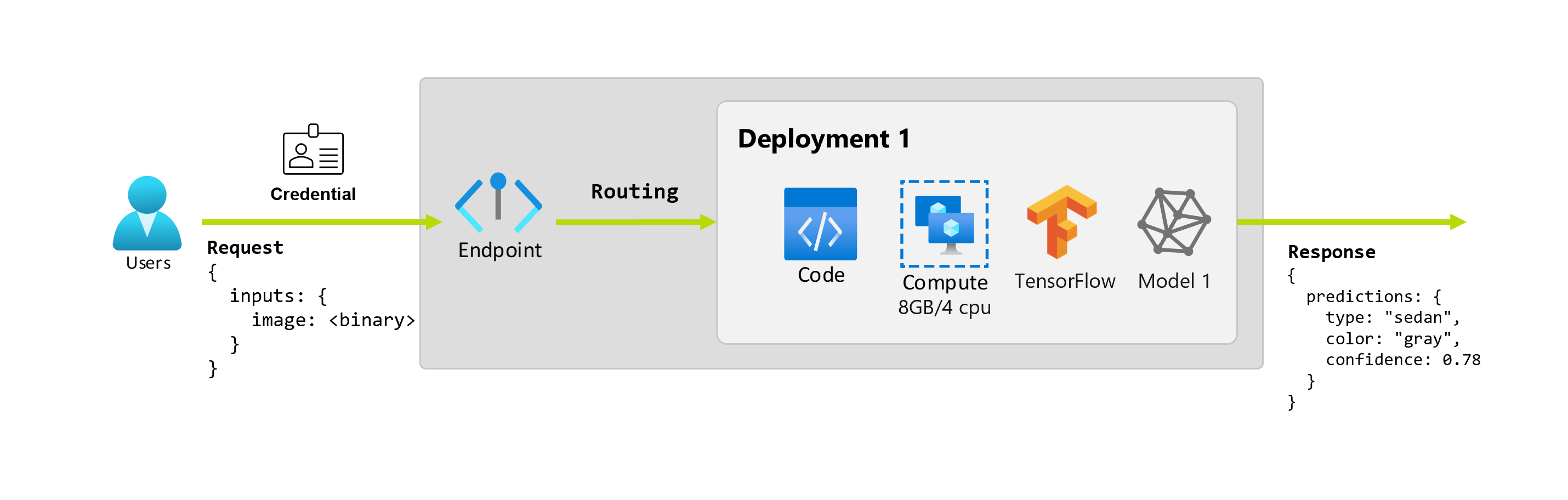
此外,假設資料科學家 Alice 正在著手實作此應用程式。 Alice 非常了解 TensorFlow,並決定使用 Keras 循序分類器搭配 TensorFlow 中樞的 RestNet 架構來實作模型。 測試模型之後,Alice 很滿意其結果並決定使用模型來解決汽車預測問題。 此模型的大小很大,需要 8 GB 的記憶體和 4 個核心才能執行。 在此案例中,Alice 的模型和執行模型所需的資源 (例如程式碼和計算) 構成端點之下的部署。
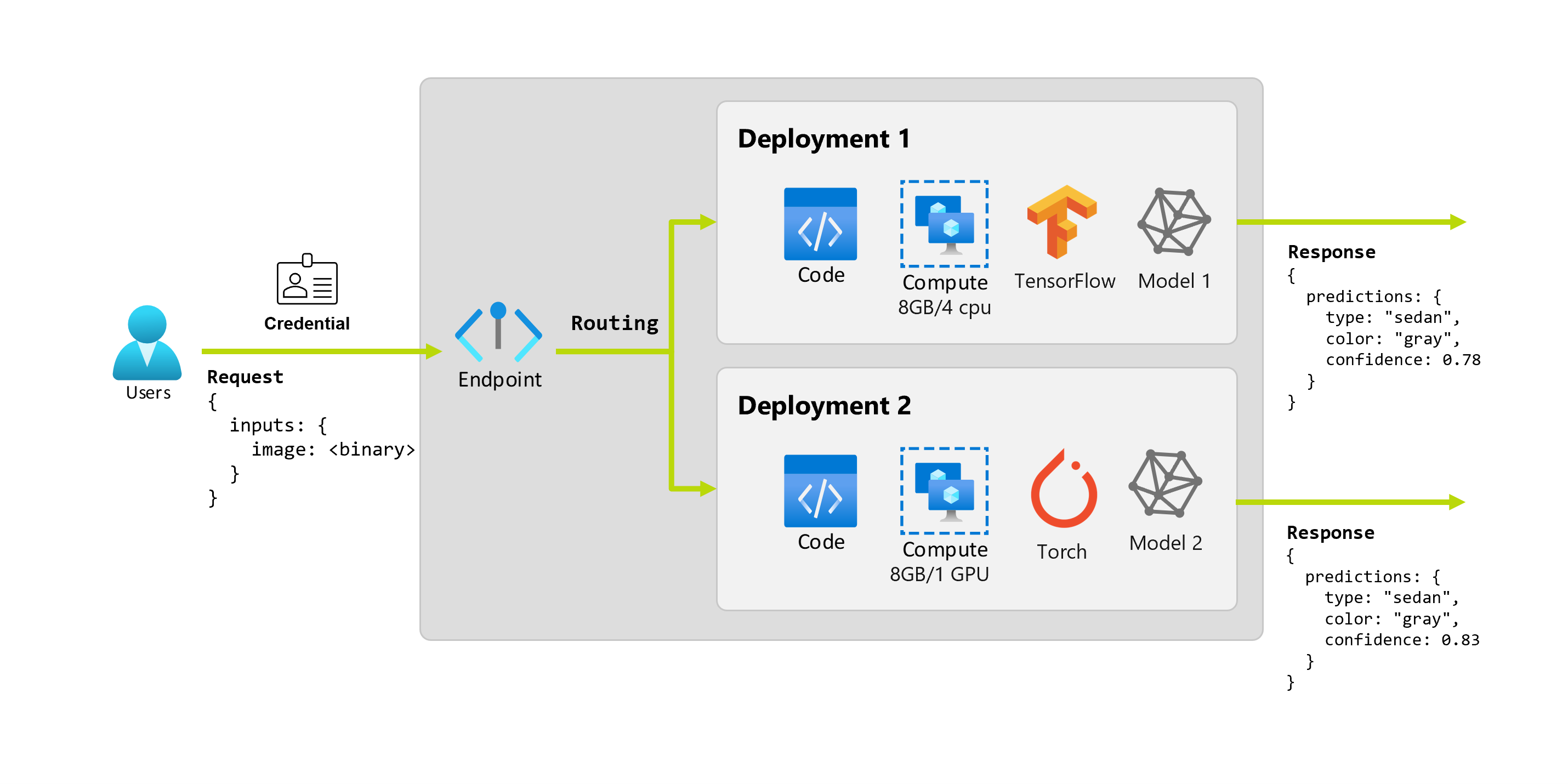
讓我們想像在幾個月後,組織發現應用程式在影像上的執行效能不佳,且照明條件低於理想。 另一位資料科學家 Bob 非常了解資料增強技術,這些技術可協助模型讓穩健性建立於該因素之上。 不過,Bob 覺得使用 Torch 來實作模型更加舒服,而且使用 Torch 定型新模型。 Bob 想要逐漸在生產環境中試用此模型,直到組織準備好淘汰舊模型為止。 新模型也會在部署到 GPU 時顯示較佳的效能,因此部署需要包含 GPU。 在此案例中,Bob 的模型和執行模型所需的資源 (例如程式碼和計算) 構成相同端點之下的另一項部署。
端點:標準部署、在線和批次
Azure Machine Learning 可讓您實作 標準部署、 在線端點和 批次端點。
標準部署 和 在線端點 是專為即時推斷所設計。 每當您叫用端點時,端點的回應中就會傳回結果。 標準部署不會取用您訂閱服務的配額;而是會以標準的計費方式計費。
「批次端點」是專為長時間執行的批次推斷所設計。 每當您叫用批次端點時,都會產生執行實際工作的批次作業。
使用標準部署、在線和批次端點的時機
標準部署:
使用 標準部署 來取用大型基礎模型,以即時推斷現成或微調這類模型。 並非所有模型都可以用於部署到標準化部署。 建議您在下列情況下使用此部署模式:
- 您的模型是基礎模型或適用於標準部署的基礎模型微調版本。
- 您可以從無配額部署中獲益。
- 您不需要自定義用來執行模型的推斷堆疊。
線上端點:
使用線上端點,讓模型針對同步低延遲要求中的即時推斷運作。 建議您在下列情況下使用它們:
- 您的模型是基礎模型或基礎模型的微調版本,但在標準部署中不受支援。
- 您沒有低延遲需求。
- 您的模型可以在相對短時間內回應要求。
- 您模型的輸入符合要求的 HTTP 承載。
- 您必須根據要求數目相應擴大。
批次端點:
使用批次端點,讓模型或管線針對長時間執行的非同步推斷運作。 建議您在下列情況下使用它們:
- 您有昂貴的模型或管線,其需要較長的執行時間。
- 您想要讓機器學習管線運作並重複使用元件。
- 您必須對分散於多個檔案的大量資料執行推斷。
- 您沒有低延遲需求。
- 您的模型輸入會儲存在記憶體帳戶或 Azure Machine Learning 資料資產中。
- 您可以利用平行處理。
標準部署、在線和批次端點的比較
所有標準部署、在線和批次端點都是以端點的概念為基礎,因此,您可以輕鬆地從一個端點轉換到另一個端點。 線上和批次端點也支援管理相同端點的多個部署。
端點
下表顯示端點層級的標準部署、在線和批次端點可用的不同功能摘要。
| 功能 | 標準部署 | 線上端點 | 批次端點 |
|---|---|---|---|
| 穩定的引動 URL | 是的 | 是的 | 是的 |
| 支援多重部署 | 否 | 是的 | 是的 |
| 部署的路由 | 無 | 流量分割 | 切換為預設值 |
| 安全推出的鏡像流量 | 否 | 是的 | 否 |
| Swagger 支援 | 是的 | 是的 | 否 |
| 驗證 | 鑰匙 | Key 和 Microsoft Entra ID (預覽) | Microsoft Entra 識別碼 |
| 私人網路支援 (舊版) | 否 | 是的 | 是的 |
| 受管理的網路隔離 | 是的 | 是的 | 是 (請參閱必要的額外設定) |
| 客戶管理的金鑰 | 無 | 是的 | 是的 |
| 成本基礎 | 每個端點每分鐘 1 | 無 | 無 |
1標準部署需按每分鐘收取少量費用。 如需與取用相關的費用,請參閱部署一節,這些費用是針對每個權杖計費。
部署
下表顯示部署層級的標準部署、在線和批次端點可用的不同功能摘要。 這些概念適用於端點下的每個部署(適用於在線和批次端點),並套用至標準部署(其中部署概念內建於端點中)。
| 功能 | 標準部署 | 線上端點 | 批次端點 |
|---|---|---|---|
| 部署類型 | 模型 | 模型 | 模型和管線元件 |
| MLflow 模型部署 | 否,只有目錄中的特定模型 | 是的 | 是的 |
| 自訂模型部署 | 否,只有目錄中的特定模型 | 是,具有評分指令碼 | 是,具有評分指令碼 |
| 模型套件部署 2 | 內建 | 是 (預覽) | 否 |
| 推斷伺服器 3 | Azure AI 模型推斷 API | - Azure Machine Learning 推斷伺服器 - 海卫一号 - 自訂 (使用 BYOC) |
批次推斷 |
| 已取用的計算資源 | 無 (無伺服器) | 執行個體或細微的資源 | 叢集執行個體 |
| 計算類型 | 無 (無伺服器) | 受控計算和 Kubernetes | 受控計算和 Kubernetes |
| 低優先順序的計算 | 無 | 否 | 是的 |
| 將計算調整為零 | 內建 | 否 | 是的 |
| 自動調整計算4 | 內建 | 是,根據資源使用 | 是,根據作業計數 |
| 超額容量管理 | 節流 | 節流 | 佇列 |
| 成本基礎5 | 每個權杖 | 每項部署:執行中的計算執行個體 | 每項作業:在作業中取用的計算執行個體 (上限為叢集執行個體數目上限) |
| 部署的本機測試 | 否 | 是的 | 否 |
2 將 MLflow 模型部署到沒有輸出網際網路連線或私人網路的端點,必須先封裝模型。
3「推斷伺服器」是指採用要求、處理要求及建立回應的服務技術。 推斷伺服器也會指定輸入的格式和預期的輸出。
4「自動調整」能夠根據負載動態相應擴大或縮小部署的配置資源。 線上和批次部署會使用不同的自動調整策略。 雖然線上部署會根據資源使用率 (例如 CPU、記憶體、要求等) 相應擴大和縮小,但批次端點則根據所建立的作業數目相應擴大或縮小。
5 取用的資源會收取線上部署和批次部署費用。 在線上部署中,資源會在部署階段佈建。 在批次部署中,資源會在作業執行時耗用,而不是部署時間。 因此,批量部署本身沒有任何相關成本。 同樣地,佇列作業也不會取用資源。
開發人員介面
端點的設計訴求在於協助組織在 Azure Machine Learning 中運作生產層級的工作負載。 端點是穩健且可調整的資源,而且可提供實作 MLOps 工作流程的最佳功能。
您可以使用多個開發人員工具來建立和管理批次與線上端點:
- Azure CLI 和 Python SDK
- Azure Resource Manager/REST API
- Azure Machine Learning 工作室入口網站
- Azure 入口網站 (IT/系統管理員)
- 使用 Azure CLI 介面和 REST/ARM 介面支援 CI/CD MLOps 管線