適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
批次端點可讓您方便地部署用來對大量資料執行推斷的模型。 這些端點可簡化針對 Batch 評分裝載模型的流程,讓您可以專注於機器學習,而非基礎結構。
請在此時機針對模型部署使用批次端點:
- 您有需要較長時間才能執行推斷的昂貴模型。
- 您必須對分散於多個檔案的大量資料執行推斷。
- 您沒有低延遲需求。
- 您可以利用平行處理。
在本文中,您會使用批次端點來部署機器學習模型,以解決傳統 MNIST (Modified National Institute of Standards and Technology,修改後的國家標準暨技術研究院) 數位辨識問題。 接著,您的已部署模型會針對大量資料執行批次推斷,在此案例中為影像檔案。 您會先從透過 Torch 建立的模型開始建立批次部署。 此部署會成為端點中的預設部署。 稍後,您將建立第二個部署,這會使用 TensorFlow (Keras) 所建立的模式,然後測試第二個部署並將其設定為端點的預設部署。
若要遵循在本機執行本文中命令所需的程式碼範例和檔案,請參閱複製範例存放庫一節。 程式碼範例和檔案均已包含在 azureml-examples 存放庫中。
必要條件
遵循本文中的步驟之前,請確保您已滿足下列必要條件:
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
Azure Machine Learning 工作區。 如果您沒有工作區,請使用如何管理工作區一文中的步驟來建立。
為了執行下列工作,請確保您在工作區中具有下列權限:
建立/管理批次端點和部署:使用擁有者角色、參與者角色,或是允許
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*的自訂角色。在工作區資源群組中建立 ARM 部署:在部署工作區的資源群組中使用擁有者角色、參與者角色,或是允許
Microsoft.Resources/deployments/write的自訂角色。
您必須安裝下列軟體,才能使用 Azure Machine Learning:
Azure CLI 和適用於 Azure Machine Learning 的
ml延伸模組。az extension add -n ml
複製範例存放庫
本文中的範例是以 azureml-examples (英文) 存放庫內含的程式碼範例為基礎。 若要在本機執行命令,而不需要複製/貼上 YAML 和其他檔案,請複製存放庫,然後將目錄變更為該資料夾:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
準備您的系統
連線到您的工作區
首先,連線到您將在其中工作的 Azure Machine Learning 工作區。
如果您尚未設定 Azure CLI 的預設值,請儲存您的預設設定。 若要避免多次傳遞訂閱、工作區、資源群組和位置的值,請執行下列程式碼:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
建立計算
批次端點會在計算叢集上執行,並同時支援 Azure Machine Learning 計算叢集 (AmlCompute) 和 Kubernetes 叢集。 叢集是共用資源,因此一個叢集可以裝載一個或多個批次部署 (可視需求裝載其他工作負載)。
建立名稱為 batch-cluster 的計算,如下列程式碼所示。 您可視需求調整,並使用 azureml:<your-compute-name> 來參考您的計算。
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
注意
此時您不需支付計算費用,因為在叫用批次端點並提交批次評分作業之前,叢集將維持在 0 個節點。 如需計算成本的詳細資訊,請參閱管理及最佳化 AmlCompute 的成本。
建立批次端點
「批次端點」是用戶端可以呼叫以觸發「批次評分作業」的 HTTPS 端點。 「批次評分作業」是評分多個輸入的工作。 「批次部署」是一組計算資源,其裝載可執行實際批次評分 (或批次推斷) 的模型。 一個 Batch 端點可以有多個 Batch 部署。 如需批次端點的詳細資訊,請參閱什麼是批次端點?。
提示
其中一個批次部署將作為端點的預設部署。 叫用端點時,預設部署會進行實際批次評分。 如需批次端點和部署的詳細資訊,請參閱批次端點和批次部署。
命名端點。 端點的名稱在 Azure 區域中必須是唯一的,因為該名稱會包含在端點的 URI 中。 例如,
mybatchendpoint中只能有一個名稱為westus2的批次端點。將端點的名稱放在變數中,以便稍後輕鬆進行參考。
ENDPOINT_NAME="mnist-batch"設定批次端點
下列 YAML 檔案會定義批次端點。 您可以透過 CLI 命令中使用此檔案,以便建立批次端點。
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learning下表描述端點的重要屬性。 如需完整的 Batch 端點 YAML 結構描述,請參閱 CLI (v2) Batch 端點 YAML 結構描述。
關鍵 描述 nameBatch 端點的名稱。 在 Azure 區域層級必須是唯一的。 description批次端點的描述。 這個屬性為選擇性。 tags要包含在端點中的標籤。 這個屬性為選擇性。 建立端點:
執行下列程式碼以建立批次端點。
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
建立 Batch 部署
模型部署是一組用於裝載實際執行推斷的模型所需的資源。 若要建立批次模型部署,您需要下列項目:
- 工作區中的已註冊模型
- 用來評分模型的程式碼
- 已安裝模型相依性的環境
- 預先建立的計算和資源設定
註冊要部署的模型,這是針對熱門數字辨識問題的 Torch 模型 (MNIST)。 批次部署只能部署已在工作區中註冊的模型。 如果您已註冊想要部署的模型,則可以略過此步驟。
提示
模型會與部署相關聯,而不是與端點相關聯。 這表示只要不同的模型 (或模型版本) 部署在不同的部署中,單一端點就可以在相同的端點下提供不同的模型 (或模型版本)。
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"現在可以建立評分指令碼了。 批次部署需要評分指令碼,以指出應該如何執行指定的模型,以及必須如何處理輸入資料。 批次端點支援在 Python 中所建立的指令碼。 在此案例中,您會部署模型來讀取代表數字的影像檔,並輸出對應的數字。 評分指令碼如下所示:
注意
針對 MLflow 模型,Azure Machine Learning 會自動產生評分指令碼,因此您不需要提供評分指令碼。 如果您的模型是 MLflow 模型,您可以略過此步驟。 如需批次端點如何使用 MLflow 模型的詳細資訊,請參閱在批次部署中使用 MLflow 模型文章。
警告
若您要在批次端點下部署自動化機器學習 (AutoML) 模型,請注意 AutoML 提供的評分指令碼僅適用於線上端點,而並非針對批次執行所設計。 如需如何針對批次部署建立評分指令碼的資訊,請參閱撰寫批次部署的評分指令碼。
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)建立您執行批次部署所在的環境。 該環境應包含批次端點所需的套件
azureml-core和azureml-dataset-runtime[fuse],以及程式碼為了執行所需的任何相依性。 在此案例中,已在conda.yaml檔案中擷取相依性:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]重要
azureml-core和azureml-dataset-runtime[fuse]是批次部署所需的套件,應該包含在環境相依性中。指定環境,如下所示:
環境定義會以匿名環境的形式包含在部署定義本身。 您將在部署的下列幾行中看到:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml警告
批次部署不支援策展環境。 您需要指定自己的環境。 您一律可以使用策展環境的基礎映像作為自己的映像以簡化程序。
建立部署定義
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: info下表描述批次部署的重要屬性。 如需完整 Batch 部署 YAML 結構描述,請參閱 CLI (v2) Batch 部署 YAML 結構描述。
關鍵 描述 name部署的名稱。 endpoint_name要在其下建立部署的端點名稱。 model用於 Batch 評分的模型。 此範例會使用 path定義內嵌模型。 此定義允許自動上傳模型檔案,並使用自動產生的名稱和版本註冊。 請參閱模型結構描述以取得更多選項。 作為生產案例的最佳做法,您應該個別建立模型並在這裡參考該模型。 若要參考現有的模型,請使用azureml:<model-name>:<model-version>語法。code_configuration.code用於模型評分的所有 Python 原始程式碼目錄。 code_configuration.scoring_script上述 code_configuration.code目錄中的 Python 檔案。 這個檔案必須有一個init()函式和個run()函式。 將init()函式用於任何昂貴或一般的準備 (例如,將模型載入記憶體)。init()將僅會在流程開始時呼叫一次。 使用run(mini_batch)來為每個項目評分;mini_batch的值為檔案路徑的清單。run()函式應該傳回 Pandas 資料框架或陣列。 每個傳回的元素表示mini_batch中輸入元素的一個成功執行。 若需了解撰寫評分指令碼的詳細資訊,請參閱了解評分指令碼。environment用來評分模型的環境。 範例會使用 conda_file和image定義內嵌環境。conda_file相依性將安裝在image上。 系統會以自動產生的名稱和版本註冊環境。 請參閱環境結構描述以取得更多選項。 作為生產案例的最佳做法,您應該個別建立環境並在這裡參考該環境。 若要參考現有的環境,請使用azureml:<environment-name>:<environment-version>語法。compute要執行 Batch 評分的計算。 範例會使用在開頭時建立的 batch-cluster,並使用azureml:<compute-name>語法來參考。resources.instance_count每個 Batch 評分作業要使用的執行個體數目。 settings.max_concurrency_per_instance每個執行個體的平行 scoring_script執行數目上限。settings.mini_batch_sizescoring_script可以在一個run()呼叫中處理的檔案數目。settings.output_action輸出應在輸出檔案中的組織方式。 append_row會將所有run()傳回的輸出結果合併成一個名為output_file_name的單一檔案。summary_only不會合併輸出結果,且只會計算error_threshold。settings.output_file_nameappend_rowoutput_action的 Batch 評分輸出檔案名稱。settings.retry_settings.max_retries失敗的 scoring_scriptrun()嘗試次數。settings.retry_settings.timeout用於評分迷你 Batch 的 scoring_scriptrun()逾時 (以秒為單位)。settings.error_threshold應忽略的輸入檔案評分失敗數目。 如果整個輸入的錯誤計數超過此值,Batch 評分作業便會終止。 此範例會使用 -1,這表示會允許任何數目的失敗,而不需要終止 Batch 評分作業。settings.logging_level記錄詳細程度。 增加詳細程度中的值為:WARNING、INFO 和 DEBUG。 settings.environment_variables要針對每個 Batch 評分作業設定的環境變數名稱-值組的字典。 建立部署:
執行下列程式碼,在批次端點下建立批次部署,並將其設定為預設部署。
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-default提示
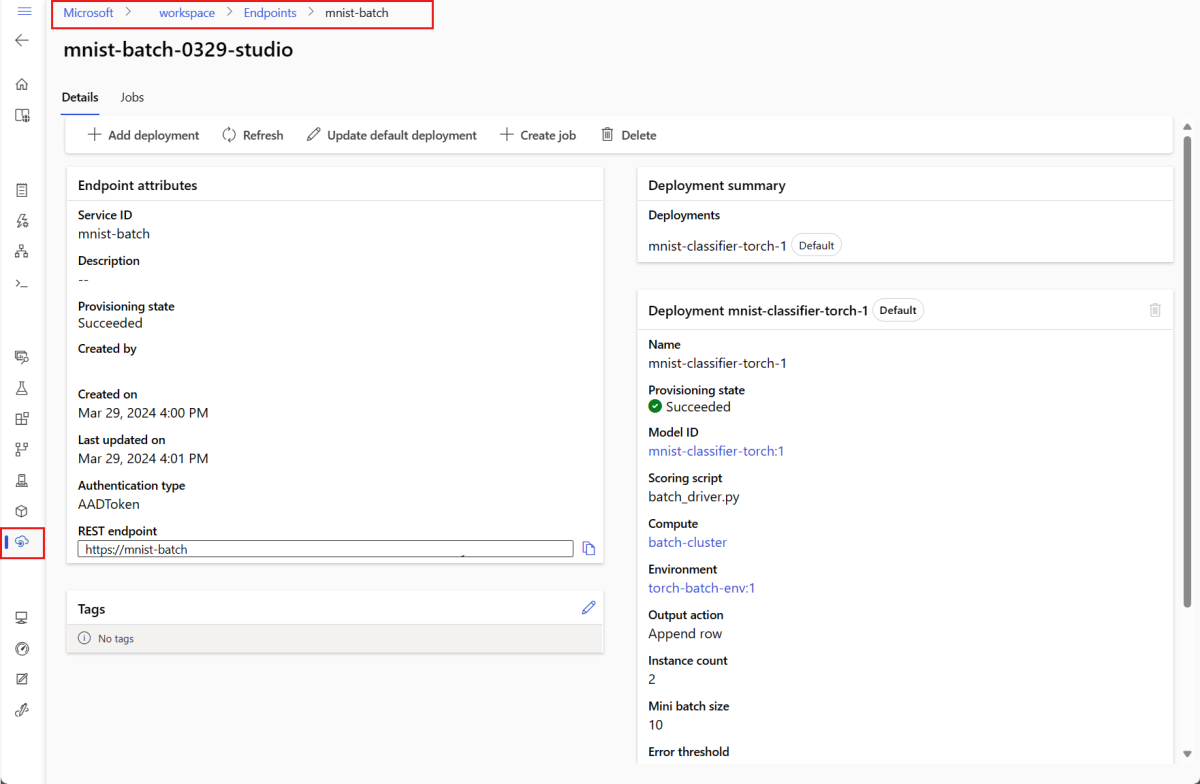
--set-default參數會將新建立的部署設定為端點的預設部署。 這是建立新端點預設部署的便利方式,特別是在第一次建立部署時。 作為生產案例的最佳做法,您可能會想要建立新的部署,而不是將其設定為預設值。 確認部署如預期般運作,之後再更新預設部署。 如需實作此流程的詳細資訊,請參閱部署新模型一節。檢查批次端點和部署詳細資料。
使用
show來檢查端點和部署詳細資料。 若要檢查 Batch 部署,請執行下列程式碼:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAME

執行批次端點和存取結果
叫用批次端點會觸發批次評分作業。 作業 name 會從叫用回應中傳回,並且可用於追蹤批次評分進度。 在批次端點中執行評分模型時,您必須指定輸入資料的路徑,以讓端點能找到您想要評分的資料。 下列範例示範如何針對儲存在 Azure 儲存體帳戶中的 MNIST 資料集範例資料,啟動新的作業。
您可以使用 Azure CLI、Azure Machine Learning SDK 或 REST 端點來執行和叫用批次端點。 如需這些選項的詳細資訊,請參閱建立批次端點的作業和輸入資料。
注意
平行處理如何運作?
批次部署會在檔案層級散發工作,這表示包含 100 個檔案、迷你批次為 10 個檔案的資料夾,會產生 10 個批次,每個批次各有 10 個檔案。 請注意,不論涉及的檔案大小為何,都會發生這種情況。 若檔案太大而無法在大型迷你批次中處理,我們建議您將檔案分割成較小的檔案,以達到較高層級的平行處理原則,或減少每個迷你批次的檔案數目。 目前,批次部署無法將檔案大小散發中的扭曲納入考量。
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



批次端點支援讀取位於不同位置的檔案或資料夾。 若要深入了解支援的類型及如何加以指定,請參閱從批次端點作業存取資料。
監視批次作業執行進度
Batch 評分作業通常需要一些時間來處理整個輸入集。
下列程式碼會檢查作業狀態,並輸出 Azure Machine Learning 工作室的連結以取得進一步的詳細資料。
az ml job show -n $JOB_NAME --web

檢查批次評分結果
作業輸出會儲存在雲端儲存空間中,可以是工作區的預設 Blob 儲存體中,或是您所指定的儲存空間。 若要了解如何變更預設值,請參閱設定輸出位置。 作業完成時,下列步驟將可讓您檢視 Azure 儲存體總管中的評分結果:
執行下列程式碼,以在 Azure Machine Learning 工作室中開啟批次評分作業。
invoke的回應中也包含了作業的工作室連結,做為interactionEndpoints.Studio.endpoint的值。az ml job show -n $JOB_NAME --web在執行的圖表中,選取
batchscoring步驟。選取 [輸出 + 記錄] 索引標籤,然後選取 [顯示資料輸出]。
從 [資料輸出] 中,選取圖示以開啟儲存體總管。

儲存體總管中的評分結果類似下列範例頁面:



設定輸出位置
依預設,批次評分結果會儲存在工作區的預設 Blob 存放區,位於依作業命名 (系統產生的 GUID) 的資料夾內。 您可以設定在叫用 Batch 端點時,儲存評分輸出的位置。
使用 output-path 可在 Azure Machine Learning 已註冊的資料存放區中設定任何資料夾。 當您指定資料夾時,--output-path 的語法與 --input 相同,也就是 azureml://datastores/<datastore-name>/paths/<path-on-datastore>/。 使用 --set output_file_name=<your-file-name> 來設定新的輸出檔案名稱。
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

警告
您必須使用唯一的輸出位置。 如果輸出檔案存在,Batch 評分作業將會失敗。
重要
與輸入不同,輸出只能儲存在 Blob 儲存體帳戶上執行的 Azure Machine Learning 資料存放區中。
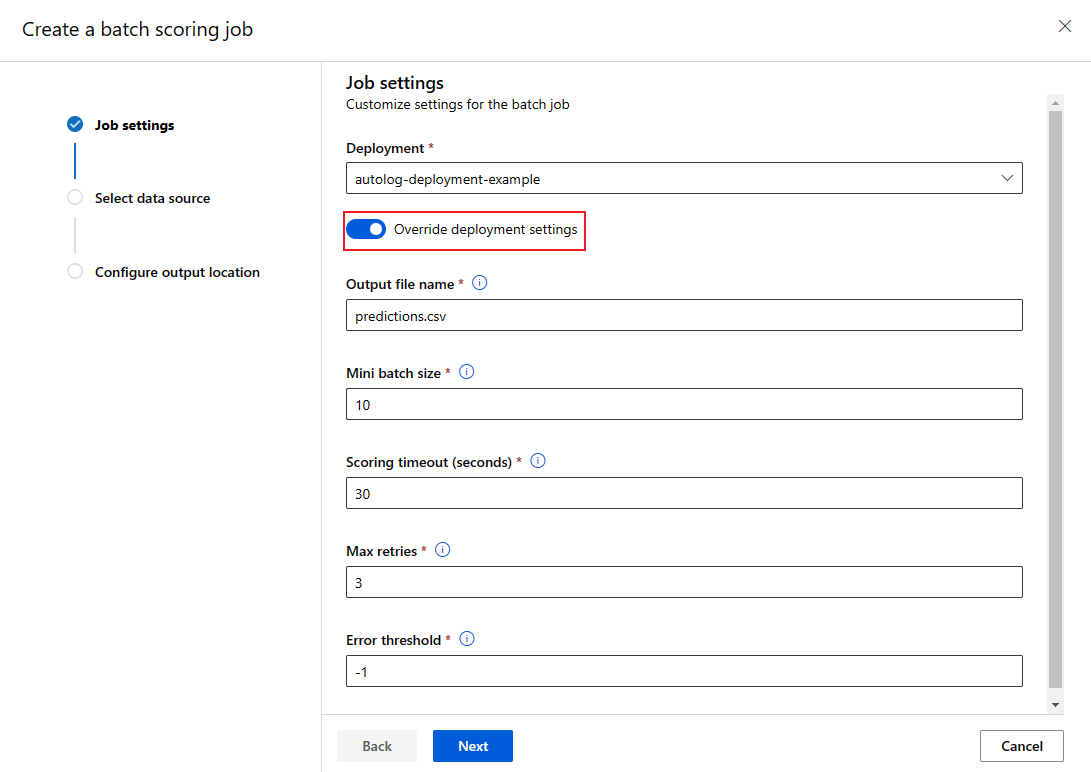
覆寫每個作業的部署組態
您在叫用批次端點時,可以覆寫部分設定以充分利用計算資源並改善效能。 下列設定可以在個別作業中設定:
- 執行個體計數:使用此設定以覆寫從計算叢集要求的執行個體數目。 例如,對於較大的數據輸入量,您可能想要使用更多實例來加速端對端批次評分。
- 迷你批次大小:使用此設定以覆寫要包含在每個迷你批次中的檔案數目。 迷你批次的數目取決於總輸入檔案計數和迷你批次大小。 較小的迷你批次大小會產生更多的迷你批次。 迷你 Batch 可以平行執行,但可能會有額外的排程和叫用負荷。
- 其他設定如 [重試次數上限]、[逾時] 和 [錯誤閾值] 均可覆寫。 這些設定可能會影響不同工作負載的端對端批次評分時間。
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
將部署新增至端點
擁有具備部署的批次端點之後,您可以繼續調整您的模型,並新增部署。 當您在相同端點下開發及部署新模型時,批次端點會繼續提供預設部署。 部署不會影響彼此。
在此範例中,您會新增使用透過 Keras 和 TensorFlow 所建置模型的第二個部署,以解決相同的 MNIST 問題。
新增第二個部署
建立您執行批次部署所在的環境。 在環境中包含您的程式碼執行所需的任何相依性。 您也需要新增程式庫
azureml-core,因為批次部署需要該程式庫才能運作。 下列環境定義具有使用 TensorFlow 執行模型所需的程式庫。環境定義會以匿名環境的形式包含在部署定義本身。
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml所使用的 conda 檔案如下所示:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]為模型建立評分指令碼:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)建立部署定義
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv建立部署:
執行下列程式碼,在批次端點下建立批次部署,並將其設定為預設部署。
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAME提示
在此情況下,遺漏
--set-default參數。 作為生產案例的最佳做法,請建立新的部署,而不是將其設定為預設值。 然後加以驗證,並在之後更新預設部署。
測試非預設 Batch 部署
若要測試新的非預設部署,您會需要知道想要執行的部署名稱。
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
請注意,--deployment-name 是用來指定要執行的部署。 此參數可讓您 invoke 非預設部署,而不會更新批次端點的預設部署。
更新預設 Batch 部署
雖然您可以在端點內叫用特定部署,但是您通常會想要叫用端點本身,並讓端點決定要使用的部署:預設部署。 您可以變更預設部署 (進而變更提供部署的模型),而不需變更與叫用端點使用者之間的合約。 使用下列程式碼來更新預設部署:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
刪除 Batch 端點和部署
若您不打算使用舊的批次部署,請執行下列程式碼加以刪除。
--yes 用來確認刪除。
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
執行下列程式碼以刪除批次端點和所有基礎部署。 將不會刪除批次評分作業。
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes