評估機器學習模型中的錯誤
目前模型偵錯實務的其中一個最大挑戰,是使用彙總計量對基準測試資料集的模型進行評分。 模型精確度可能無法在資料子群組之間統一,而且可能有些輸入世代的模型更頻繁地失敗。 這些失敗的直接結果就是完全缺乏可靠性和安全性、衍生公平性問題,以及完全失去人們對機器學習的信任。

錯誤分析會從彙總精確度計量移出, 以透明方式向開發人員公開錯誤分佈,並讓他們有效率地識別和診斷錯誤。
負責任 AI 儀表板的錯誤分析元件可讓機器學習從業人員更深入了解模型失敗分佈,並協助他們快速識別錯誤的資料世代。 此元件會識別具有較高錯誤率的資料世代 (相較於整體基準測試錯誤率), 並透過下列方式參與模型生命週期工作流程的識別階段:
- 決策樹,其中顯示具有高錯誤率的世代。
- 熱度圖,可視覺化呈現輸入特徵如何影響跨世代的錯誤率。
若系統因特定人口統計群組或定型資料中不常觀察到的輸入世代而導致效能不佳時,可能會發生錯誤差異。
此元件的功能來自錯誤分析套件,其會產生模型錯誤設定檔。
當您需要進行下列作業時,請使用錯誤分析:
- 深入了解模型失敗在某個資料集、數個輸入和特徵維度間的分佈情況。
- 細分彙總效能計量,以自動探索錯誤的世代,進而取得鎖定目標的風險降低步驟。
錯誤樹狀結構
錯誤模式通常十分複雜,而且牽涉到一或兩個以上的特徵。 開發人員可能難以探索所有可能的特徵組合,因此無法發現具有重大失敗的隱藏資料。
為了減輕負擔,二進位樹狀結構視覺效果會自動將基準測試資料分割成含有過高或過低預期錯誤率且可解譯的子群組。 換句話說,樹狀結構會使用輸入特徵,最大程度將模型錯誤與成功分開。 針對定義資料子群組的每個節點,使用者可以調查下列資訊:
- 錯誤率:節點中具不正確模型的執行個體部分。 這會透過紅色的濃度來顯示。
- 錯誤涵蓋範圍:屬於節點的所有錯誤部分。 這會透過節點的填滿率來顯示。
- 資料表示:錯誤樹狀結構中每個節點的執行個體數目。 這會透過節點傳入邊緣的粗細,以及節點中執行個體總數來顯示。

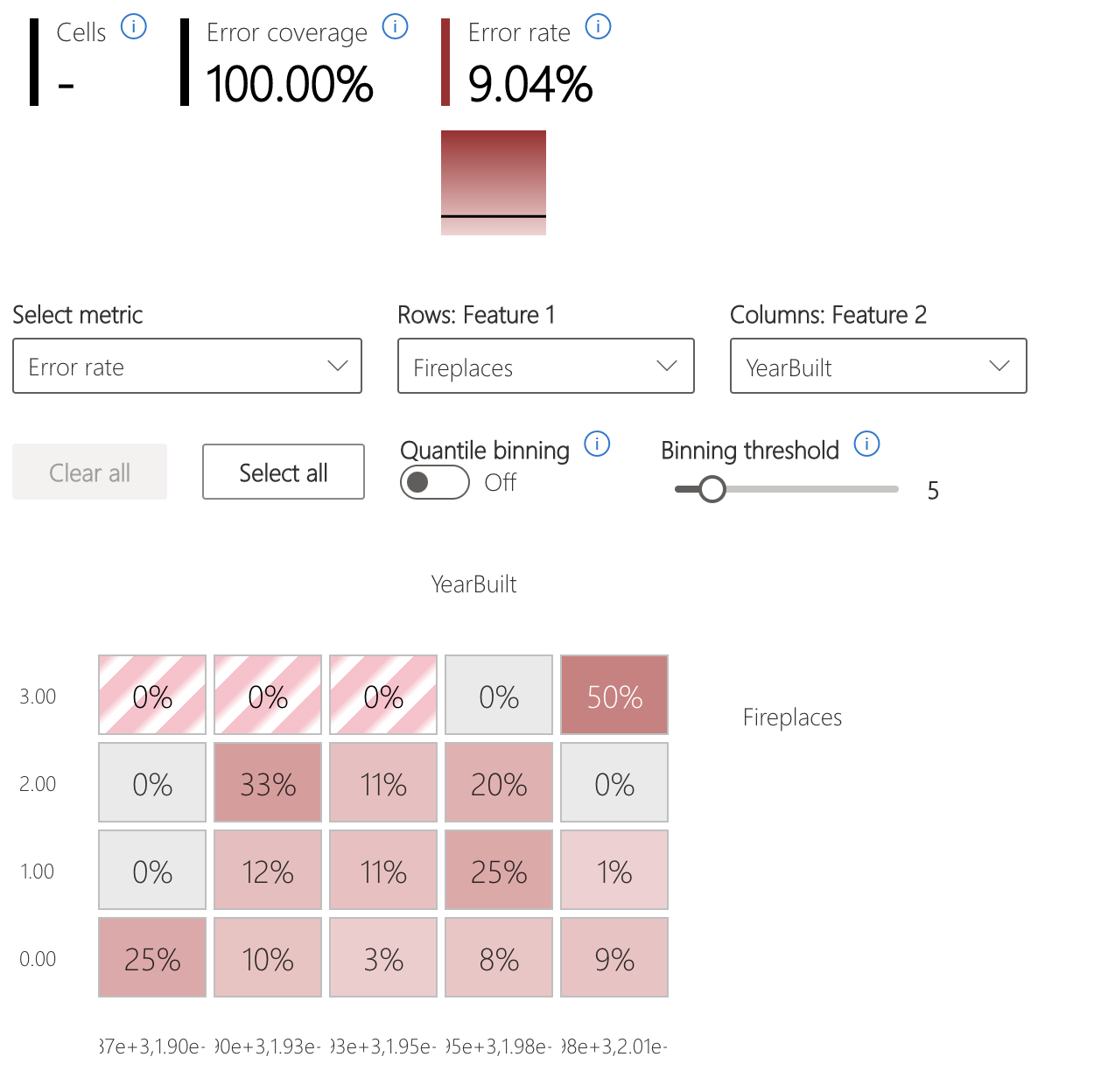
錯誤熱度圖
此檢視會根據輸入特徵的一維或二維格線來進行資料配量。 使用者可以選擇感興趣的輸入特徵進行分析。
熱度圖會以較深的紅色視覺化呈現錯誤率高的儲存格,讓使用者注意到這些區域。 此功能很有用,特別是各分割區中的錯誤主題不同時,這在實務上經常發生。 在此錯誤識別檢視中,分析受到使用者的高度引導,包括他們認為及假設哪些特徵對於了解失敗而言最為重要。
下一步
- 了解如何透過 CLI 和 SDK 或 Azure Machine Learning 工作室 UI 產生負責任 AI 儀表板。
- 探索支援的錯誤分析視覺效果。
- 了解如何根據負責任 AI 儀表板中觀察到的見解來產生負責任 AI 計分卡。