當您在 Azure 機器學習 中使用批次端點時,您可以對大量輸入資料執行長時間的批次作業。 數據可以位於不同位置,例如跨不同區域。 某些類型的批次端點也可以接收常值參數作為輸入。
本文說明如何為批次端點指定參數輸入,以及如何建立部署作業。 此程式支援使用來自各種來源的數據,例如數據資產、數據存放區、記憶體帳戶和本機檔案。
必要條件
批次端點和部署。 若要建立這些資源,請參閱在 Azure 機器學習 中的批次部署中部署 MLflow 模型。
執行批次端點部署的權限。 您可以使用 AzureML 資料科學家、參與者和擁有者角色來執行部署。 若要檢閱自定義角色定義所需的特定許可權,請參閱 批次端點上的授權。
要叫用端點的認證。 如需詳細資訊,請參閱 建立驗證。
從部署端點的計算叢集讀取輸入數據的存取權。
提示
某些情況需要使用無認證數據存放區或外部 Azure 儲存體 帳戶作為數據輸入。 在這些案例中,請確定您已 設定計算叢集以進行數據存取,因為計算叢集的受控識別用於掛接記憶體帳戶。 您仍然具有細微的訪問控制,因為作業 (invoker) 的身分識別是用來讀取基礎數據的。
建立驗證
若要叫用端點,您需要有效的Microsoft Entra 令牌。 當您叫用端點時,Azure 機器學習 會在與令牌相關聯的身分識別下建立批次部署作業。
- 如果您使用 Azure 機器學習 CLI (v2) 或 Azure 機器學習 SDK for Python (v2) 來叫用端點,則不需要手動取得 Microsoft Entra 令牌。 登入期間,系統會驗證您的使用者身分識別。 它也會為您擷取並傳遞令牌。
- 如果您使用 REST API 叫用端點,則必須手動取得令牌。
您可以使用自己的認證進行叫用,如下列程序所述。
使用 Azure CLI,以互動式或裝置代碼驗證來進行登入:
az login
如需各種認證類型的詳細資訊,請參閱 如何使用不同類型的認證來執行作業。
建立基本作業
若要從批次端點建立作業,請叫用端點。 您可以使用 Azure 機器學習 CLI、適用於 Python 的 Azure 機器學習 SDK 或 REST API 呼叫來完成調用。
下列範例顯示批次端點的調用基本概念,這些端點會接收單一輸入數據資料夾進行處理。 如需涉及各種輸入和輸出的範例,請參閱 瞭解輸入和輸出。
使用批次端點底下的 invoke 作業:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
叫用特定部署
批次端點可在相同端點下裝載多個部署。 除非使用者另有指定,否則會使用預設端點。 您可以使用下列程式來變更您使用的部署。
使用引數 --deployment-name 或 -d 指定部署名稱:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
設定作業屬性
您可以在叫用時設定一些作業屬性。
注意
目前,您只能在具有管線元件部署的批次端點中設定作業屬性。
設定實驗名稱
使用下列程式來設定您的實驗名稱。
使用引數 --experiment-name 來指定實驗的名稱:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
了解輸入和輸出
批次端點提供持久的 API,供取用者用於建立批次工作。 相同的介面可用於指定部署預期的輸入和輸出。 使用輸入傳遞端點執行作業所需的任何資訊。
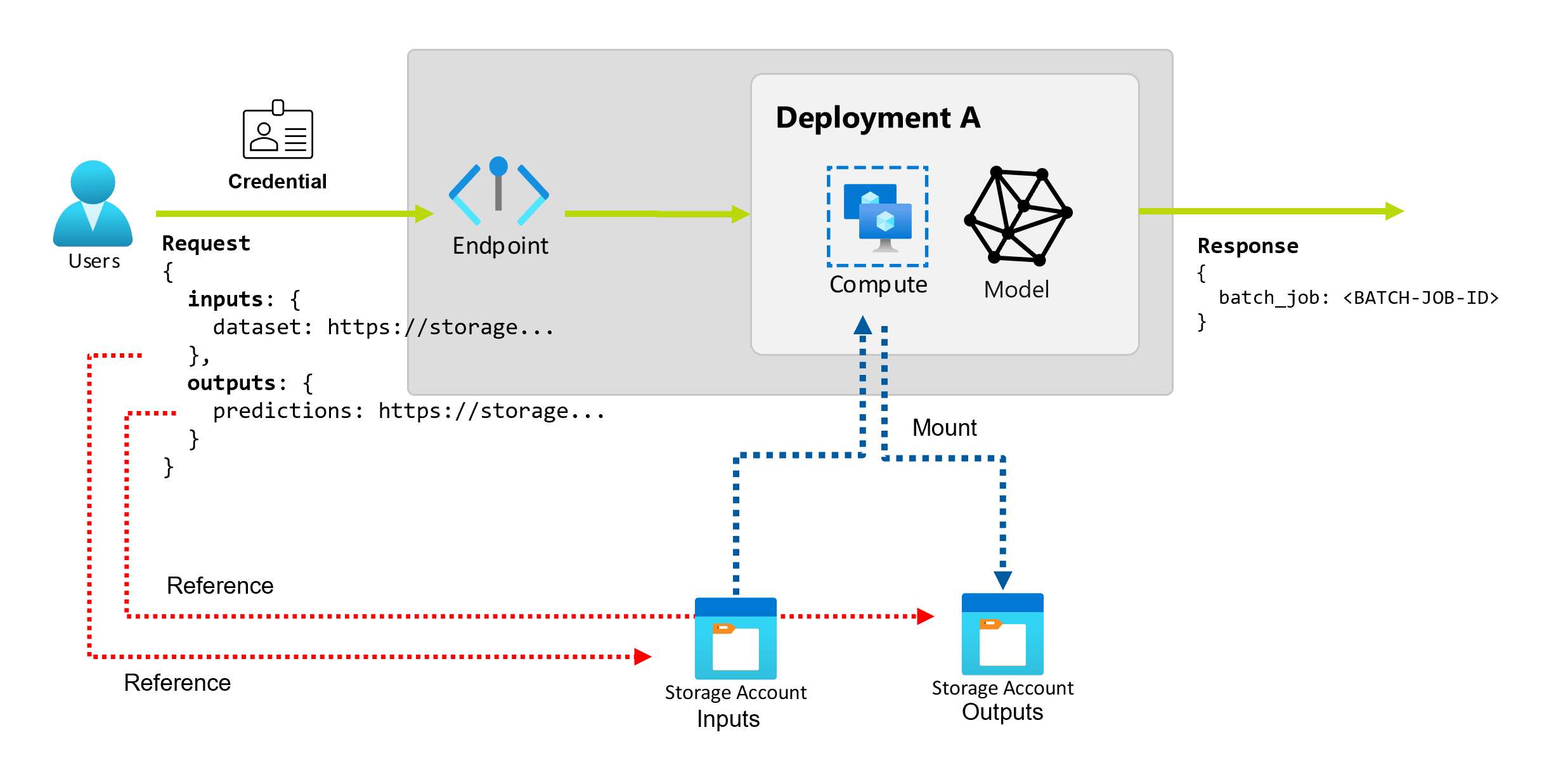
批次端點支援兩種類型的輸入:
- 特定記憶體位置或 Azure 機器學習 資產的數據輸入或指標
- 常值輸入,或常值,例如要傳遞至作業的數位或字串
輸入和輸出的數目與類型取決於批次部署類型。 模型部署一律需要一個資料輸入,並產生一個資料輸出。 模型部署不支援常值輸入。 相反地,管線元件部署提供更一般建置端點的建構。 在管線元件部署中,您可以指定任意數目的數據輸入、常值輸入和輸出。
下表概述批次部署的輸入和輸出:
| 部署類型 | 輸入數目 | 支援的輸入類型 | 輸出數目 | 支援的輸出類型 |
|---|---|---|---|---|
| 模型部署 | 1 | 資料輸入 | 1 | 資料輸出 |
| 管線元件部署 | 0-N | 資料輸入和常值輸入 | 0-N | 資料輸出 |
提示
輸入和輸出一律會命名。 每個名稱都是用來識別數據的索引鍵,並在調用期間傳遞值。 因為模型部署一律需要一個輸入和輸出,因此在模型部署的調用期間會忽略名稱。 您可以指定最能描述使用案例的名稱,例如 sales_estimation。
探索資料輸入
資料輸入亦即指向資料存放位置的輸入。 由於批次端點通常會耗用大量資料,因此您無法在叫用要求中傳遞輸入資料。 相反地,您可以指定批次端點應前往尋找資料的位置。 輸入數據會在目標計算實例上掛接並串流,以改善效能。
Batch 端點可以讀取位於下列記憶體類型的檔案:
-
Azure 機器學習 數據資產,包括資料夾 (
uri_folder) 和檔案 (uri_file) 類型。 - Azure Machine Learning 資料存放區,包括 Azure Blob 儲存體、Azure Data Lake Storage Gen1 和 Azure Data Lake Storage Gen2。
- Azure 儲存體 帳戶,包括 Blob 記憶體、Data Lake Storage Gen1 和 Data Lake Storage Gen2。
- 當您使用 Azure 機器學習 CLI 或適用於 Python 的 Azure 機器學習 SDK 來叫用端點時,本機數據資料資料夾和檔案。 但本機數據會上傳至 Azure 機器學習 工作區的預設數據存放區。
重要
淘汰通知:類型 FileDataset (V1) 的數據資產已被取代,未來將會淘汰。 依賴這項功能的現有批次端點可繼續運作。 但在批次端點中不支援使用下列專案建立的 V1 資料集:
- 正式運作的 Azure 機器學習 CLI v2 版本(2.4.0 和更新版本)。
- 正式發行的 REST API 版本 (2022-05-01 和更新版本)。
探索常值輸入
常值輸入亦即可在叫用期間表示及解析的輸入,例如字串、數字和布林值。 您通常會使用常值輸入將參數傳遞至端點,作為管線元件部署的一部分。 批次端點支援下列常值類型:
stringbooleanfloatinteger
僅限於管線元件部署中支援常值輸入。 若要查看如何指定常值端點,請參閱 使用常值輸入建立作業。
探索資料輸出
數據輸出是指放置批次作業結果的位置。 每個輸出都有識別名稱,而且 Azure Machine Learning 會自動為每個具名輸出指派唯一的路徑。 如果需要,您可以指定另一個路徑。
重要
Batch 端點僅支援在 Blob 記憶體資料存放區中寫入輸出。 如果您需要寫入已啟用階層命名空間的記憶體帳戶,例如 Data Lake Storage Gen2,您可以將記憶體服務註冊為 Blob 記憶體數據存放區,因為服務完全相容。 如此一來,您就可以將批次端點的輸出寫入 Data Lake Storage Gen2。
使用資料輸入建立作業
下列範例示範如何在從數據資產、數據存放區和 Azure 儲存體 帳戶取得數據輸入時建立作業。
使用來自數據資產的輸入數據
Azure Machine Learning 資料資產 (先前稱為資料集) 支援做為作業的輸入。 請遵循下列步驟來執行批次端點作業,該作業會使用 Azure 機器學習 中已註冊數據資產中儲存的輸入數據。
警告
目前不支援數據表 (MLTable) 類型的數據資產。
建立資料資產。 在此範例中,它是由包含多個 CSV 檔案的資料夾所組成。 您可以使用批次端點平行處理檔案。 若您的資料已註冊為資料資產,則可略過此步驟。
在名為 heart-data.yml 的 YAML 檔案中建立資料資產定義:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: data建立資料資產:
az ml data create -f heart-data.yml
設定輸入:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)資料資產識別碼格式
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>為 。執行端點:
--set使用 自變數來指定輸入。 首先,以底線字元取代數據資產名稱中的任何連字元。 索引鍵只能包含英數位元和底線字元。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_ID針對提供模型部署的端點,您可以使用
--input自變數來指定數據輸入,因為模型部署一律只需要一個數據輸入。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_ID當您指定多個輸入時,自變數
--set通常會產生長命令。 在這種情況下,您可以列出檔案中的輸入,然後在您叫用端點時參考檔案。 例如,您可以建立名為 inputs.yml 的 YAML 檔案,其中包含下列幾行:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1然後,您可以執行下列命令,此命令會使用
--file自變數來指定輸入:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
使用來自資料存放區的輸入數據
批次部署作業可以直接參考 Azure 機器學習 已註冊數據存放區中的數據。 在此範例中,您會先將某些數據上傳至 Azure 機器學習 工作區中的數據存放區。 接著,您會在該數據上執行批次部署。
此範例使用預設數據存放區,但您可以使用不同的數據存放區。 在任何 Azure 機器學習 工作區中,預設 Blob 資料存放區的名稱是 workspaceblobstore。 如果您想要在下列步驟中使用不同的資料存放區,請將 取代 workspaceblobstore 為您慣用的數據存放區名稱。
將範例數據上傳至數據存放區。 範例數據可在 azureml-examples 存放庫中取得。 您可以在該存放庫的 sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data 資料夾中找到數據 。
- 在 Azure Machine Learning 工作室 中,開啟預設 Blob 數據存放區的數據資產頁面,然後查閱其 Blob 容器的名稱。
- 使用 Azure 儲存體 Explorer 或 AzCopy 之類的工具,將範例數據上傳至該容器中名為 heart-disease-uci-unlabel 的資料夾。
設定輸入資訊:
將檔案路徑放在
INPUT_PATH變數中:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"請注意資料夾
paths是輸入路徑的一部分。 這個格式表示後接的值是路徑。執行端點:
請使用
--set引數指定輸入:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATH針對提供模型部署的端點,您可以使用
--input自變數來指定數據輸入,因為模型部署一律只需要一個數據輸入。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folder當您指定多個輸入時,自變數
--set通常會產生長命令。 在這種情況下,您可以列出檔案中的輸入,然後在您叫用端點時參考檔案。 例如,您可以建立名為 inputs.yml 的 YAML 檔案,其中包含下列幾行:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>如果您的數據位於檔案中,請改用
uri_file輸入的類型。然後,您可以執行下列命令,此命令會使用
--file自變數來指定輸入:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
使用來自 Azure 儲存體 帳戶的輸入數據
Azure 機器學習 批次端點可以從 Azure 儲存體 帳戶中的雲端位置讀取數據,無論是公用帳戶還是私人帳戶。 使用下列步驟,以記憶體帳戶中的數據執行批次端點作業。
如需從記憶體帳戶讀取數據的額外必要組態詳細資訊,請參閱 設定計算叢集以進行數據存取。
設定輸入:
設定
INPUT_DATA變數:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"如果您的資料位於檔案中,請使用類似下列格式來定義輸入路徑:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"執行端點:
請使用
--set引數指定輸入:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATA針對提供模型部署的端點,您可以使用
--input自變數來指定數據輸入,因為模型部署一律只需要一個數據輸入。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folder當您指定多個輸入時,自
--set變數通常會產生長命令。 在這種情況下,您可以列出檔案中的輸入,然後在您叫用端點時參考檔案。 例如,您可以建立名為 inputs.yml 的 YAML 檔案,其中包含下列幾行:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data然後,您可以執行下列命令,此命令會使用
--file自變數來指定輸入:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml如果您的資料位於檔案中,請使用
uri_fileinputs.yml 檔案中的類型作為數據輸入。
使用常值輸入建立作業
管線元件部署可接受常值輸入。 如需包含基本管線的批次部署範例,請參閱 如何使用批次端點部署管線。
下列範例展示如何指定名為 score_mode、類型為 string 且值為 append 的輸入:
將您的輸入放在 YAML 檔案中,例如一個名為 inputs.yml:
inputs:
score_mode:
type: string
default: append
執行下列命令,其會使用 --file 自變數來指定輸入。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
您也可以使用 --set 自變數來指定類型和預設值。 但是,當您指定多個輸入時,此方法通常會產生長命令:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
使用資料輸出建立作業
下列範例示範如何變更名為 score的輸出位置。 為了完整性,此範例也會設定名為 heart_data的輸入。
此範例使用預設數據存放區 workspaceblobstore。 但只要它是 Blob 記憶體帳戶,您就可以在工作區中使用任何其他數據存放區。 如果您想要使用不同的資料存放區,請將下列步驟中的取代 workspaceblobstore 為您慣用的數據存放區名稱。
取得數據存放區的標識碼。
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')資料存放區識別碼的格式
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore為 。建立資料輸出:
在名為 inputs-and-outputs.yml 的檔案中定義輸入和輸出值。 在輸出路徑中使用資料存放區標識碼。 為了完整性,也定義數據輸入。
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-path注意
請注意資料夾
paths是輸出路徑的一部分。 這個格式表示後接的值是路徑。執行部署:
--file使用 自變數來指定輸入與輸出值:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml