適用於: Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
Azure CLI ml 延伸模組 v2 (目前)Python SDK azure-ai-ml v2 (目前)
了解如何在 Azure Machine Learning 工作區中建立計算執行個體。
請在雲端中使用計算執行個體來作為已完整設定和完全受控的開發環境。 如果是開發或測試,您也可以使用執行個體作為定型計算目標。 計算執行個體可以平行執行多個作業,並具有作業佇列。 在開發環境中,無法與您工作區中的其他使用者共用計算執行個體。
在本文中,您將了解如何建立計算執行個體。 如需啟動、停止、重新啟動和刪除計算執行個體的步驟,請參閱管理 Azure Machine Learning 計算執行個體。
您也可以使用設定指令碼,以您自己的自訂環境建立計算執行個體。
運算執行處理可以在 虛擬網路環境中安全地執行工作,而不需要企業開啟 SSH 連接埠。 作業會在容器化環境中執行,並在 Docker 容器中封裝模型的相依性。
附註
本文在某些範例中使用 CLI v2。 如果您仍在使用 CLI v1,請參閱 建立 Azure Machine Learning 計算叢集 CLI v1。
先決條件
- Azure Machine Learning 工作區。 如需詳細資訊,請參閱建立 Azure Machine Learning 工作區。 在儲存體帳戶中,必須啟用 [允許儲存體帳戶金鑰存取] 選項,計算執行個體建立才能成功。
選擇您用於其他必要條件的環境的索引標籤。
- 若要使用 Python SDK,請使用工作區設定開發環境。 設定環境之後,連結至您的 Python 指令碼中的工作區:
執行此程式碼以連線至您的 Azure Machine Learning 工作區。
在下方的程式碼中替換您的訂用帳戶識別碼、資源群組名稱和工作區名稱。 若要尋找這些值:
- 登入 Azure Machine Learning Studio。
- 開啟您要使用的工作區。
- 在右上方的 Azure Machine Learning 工作室工具列中,選取您的工作區名稱。
- 將工作區、資源群組和訂用帳戶識別碼的值複製到程式碼。
適用於:Python SDK azure-ai-ml v2 (目前)
# Enter details of your AML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"# get a handle to the workspace
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
ml_client 是工作區的處理常式,用來管理其他資源和工作。
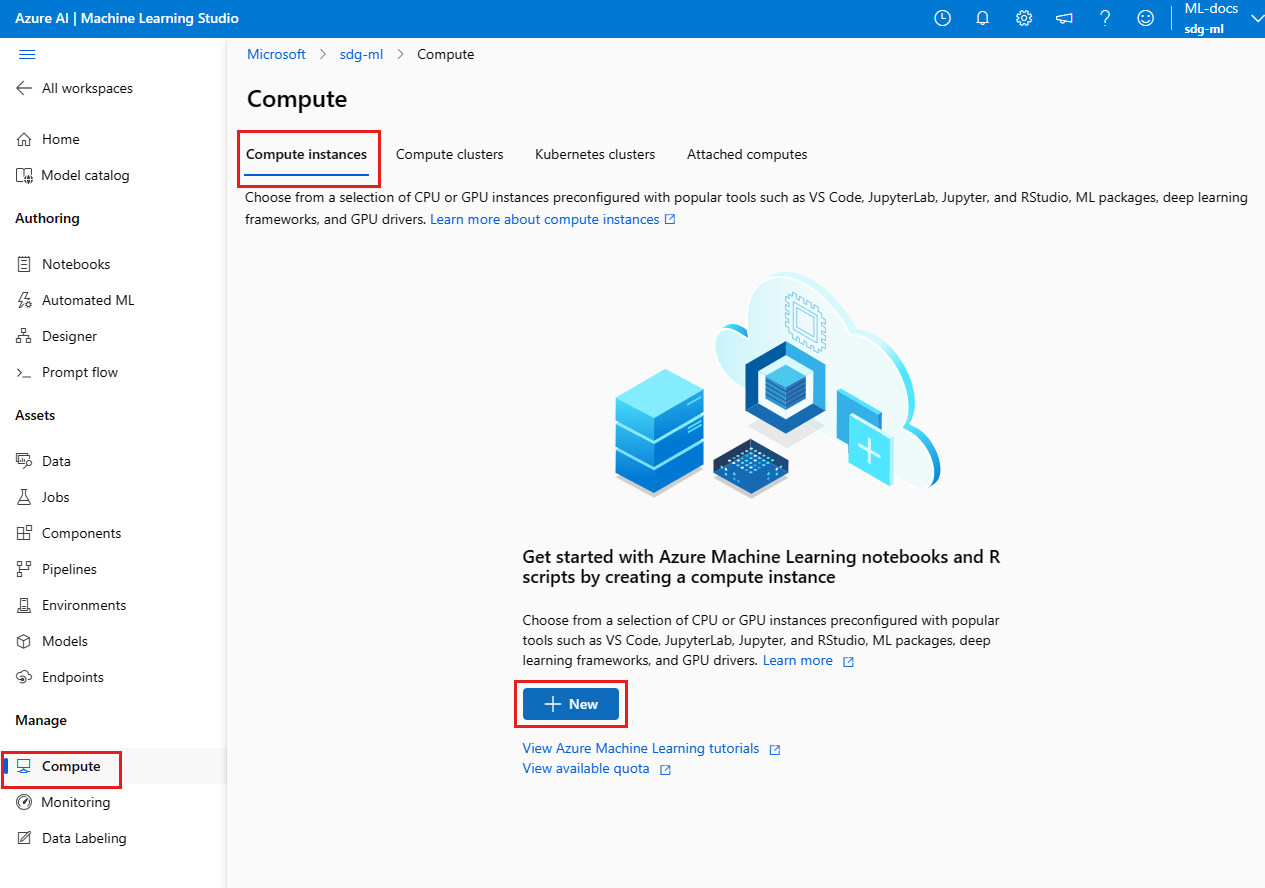
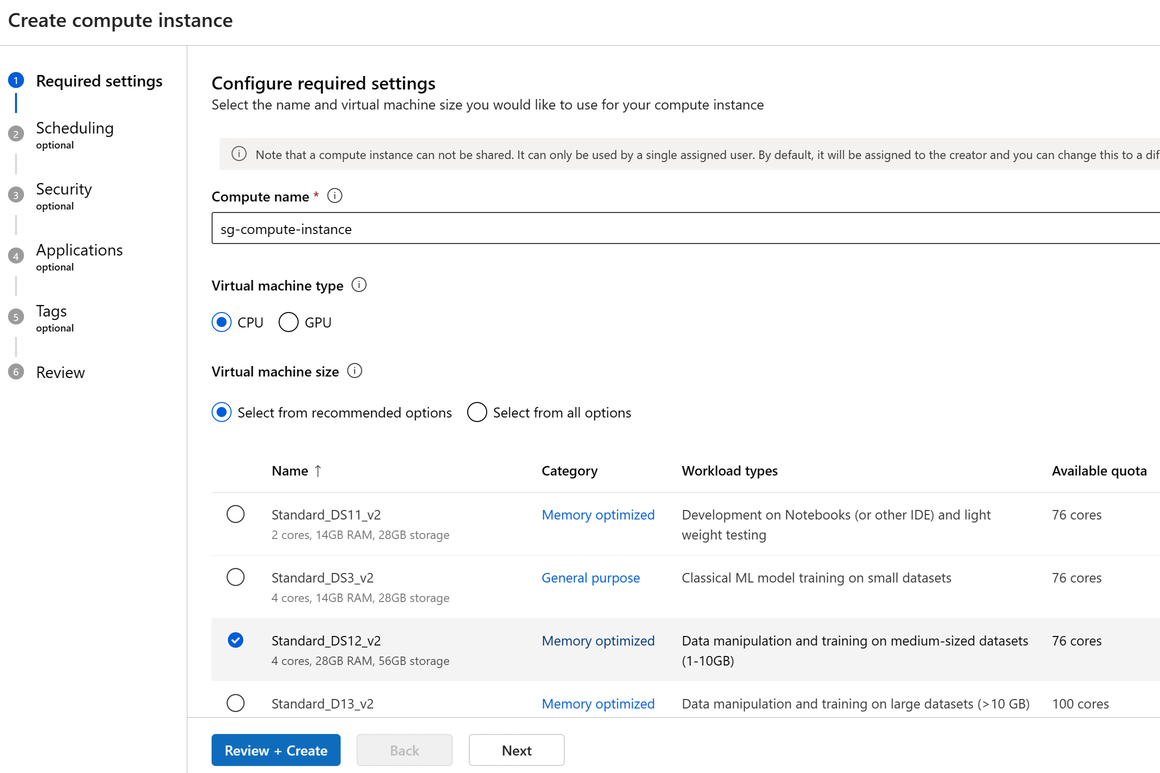
建立
估計時間:約 5 分鐘。
在工作區中建立計算實例是一個一次性過程。 您可以將計算重複使用於開發工作站,或作為訓練用的計算目標。 您可以將多個計算執行個體附加至工作區。
適用於計算執行個體建立的專用核心每個區域、VM 系列配額與總計區域配額會統一,並與 Azure Machine Learning 定型計算叢集配額共用。 停止運算執行處理不會釋放配額,以確保您可以重新啟動運算執行處理。 配額是 Azure 資源的信用額度限制,而不是容量保證。 重新啟動計算實例仍然取決於區域的可用容量。 如果 SKU 的區域中發生容量緊縮,您可能無法重新啟動計算執行個體。 一旦建立計算實例後,就無法變更其虛擬機器的大小。
建立計算執行個體的最快方式是遵循建立開始使用所需的資源。
或使用下列範例,建立具有更多選項的計算執行個體:
適用於:Python SDK azure-ai-ml v2 (目前)
# Compute Instances need to have a unique name across the region.
# Here we create a unique name with current datetime
from azure.ai.ml.entities import ComputeInstance, AmlCompute
import datetime
ci_basic_name = "basic-ci" + datetime.datetime.now().strftime("%Y%m%d%H%M")
ci_basic = ComputeInstance(name=ci_basic_name, size="STANDARD_DS3_v2")
ml_client.begin_create_or_update(ci_basic).result()如需有關建立計算執行個體之類別、方法和參數的詳細資訊,請參閱下列參考文件:

您也可以使用 Azure Resource Manager 範本來建立計算執行個體。
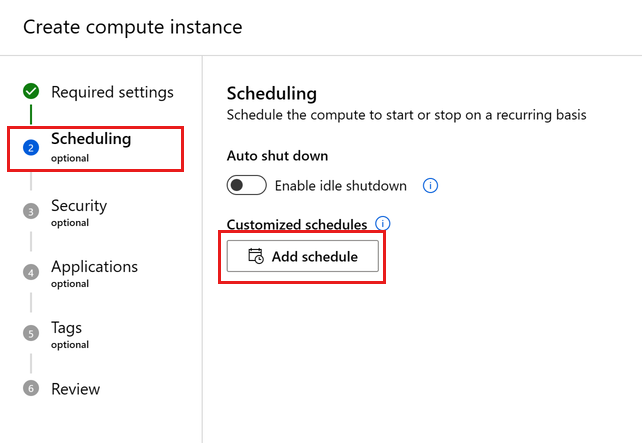
設定閒置關機
若要避免已開啟但處於非使用中的計算執行個體產生費用,您可以設定計算執行個體因為閒置而關機的時間。
如果符合下列條件,運算執行處理會被視為非作用中:
- 無作用中的 Jupyter 核心工作階段 (這表示並未透過 Jupyter、JupyterLab 或 Interactive Notebooks 使用筆記本)
- 沒有作用中的 Jupyter 終端機工作階段
- 沒有作用中的 Azure Machine Learning 執行或實驗
- 沒有 VS Code 連線;您必須關閉 VS Code 連線,計算執行個體才會被視為非作用中。 如果 VS Code 偵測到 3 小時內無活動,則會自動終止工作階段。
- 計算上沒有執行任何自訂應用程式
如果有任何自訂應用程式正在執行,計算執行個體就不會視為閒置。 若要自動關閉具有自訂應用程式的計算,必須設定排程,或移除自訂應用程式。 不活動時間段也有一些基本界限;運算執行處理必須處於非作用中狀態,最少 15 分鐘,最多 3 天。 我們也不會追蹤 VS Code SSH 連線以判斷活動。
此外,如果運算執行處理已閒置一段時間,且閒置關機設定已更新為短於目前閒置持續時間的時間量,則閒置時鐘會重設為 0。 例如,如果運算執行處理已閒置 20 分鐘,且關機設定已更新為 15 分鐘,則閒置時鐘會重設為 0。
重要事項
如果 Azure Machine Learning 工作區資源也設定為受控識別,除非受控識別具有 Azure Machine Learning 工作區的參與者存取權,否則計算執行個體不會因為非使用狀態而關閉。 如需指派權限的詳細資訊,請參閱管理 Azure Machine Learning 工作區的存取權。
此設定可以在計算執行個體建立期間設定,或透過下列介面為現有的計算執行個體進行設定:
適用於:Python SDK azure-ai-ml v2 (目前)
建立新的計算執行個體時,請新增 idle_time_before_shutdown_minutes 參數。
# Note that idle_time_before_shutdown has been deprecated.
ComputeInstance(name=ci_basic_name, size="STANDARD_DS3_v2", idle_time_before_shutdown_minutes="30")
您無法使用 Python SDK 變更現有計算執行個體的閒置時間。


您也可以使用下列項目來變更閒置時間:
REST API
端點:
POST https://management.azure.com/subscriptions/{SUB_ID}/resourceGroups/{RG_NAME}/providers/Microsoft.MachineLearningServices/workspaces/{WS_NAME}/computes/{CI_NAME}/updateIdleShutdownSetting?api-version=2021-07-01主體:
{ "idleTimeBeforeShutdown": "PT30M" // this must be a string in ISO 8601 format }ARM 範本:只能在建立新的計算執行個體期間進行設定
// Note that this is just a snippet for the idle shutdown property in an ARM template { "idleTimeBeforeShutdown":"PT30M" // this must be a string in ISO 8601 format }
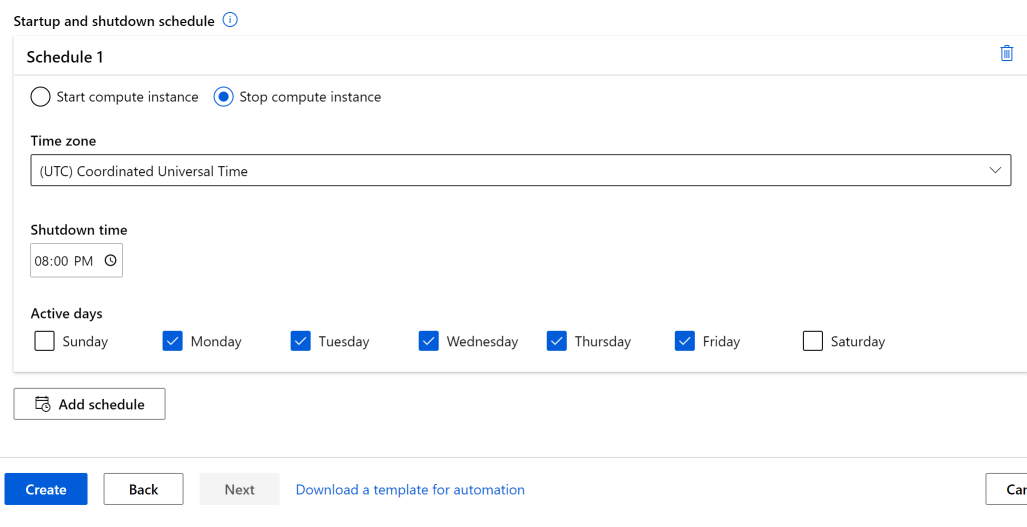
排程自動啟動和停止
定義自動關機和自動啟動的多個排程。 例如,建立在星期一至星期四上午 9 點開始,並在下午 6 點停止的排程,然後建立在星期五上午 9 點開始,並在下午 4 點停止的第二個排程。 您可以針對每個計算執行個體建立總共四個排程。
也可以針對代表其他人建立計算執行個體定義排程。 您可以建立排程來建立處於停止狀態的計算執行個體。 當您代表其他使用者建立計算執行個體時,能停止計算執行個體會很有用。
在排定的關閉之前,使用者會看到一則通知,提醒他們計算執行個體即將關閉。 此時,使用者可以選擇關閉即將發生的關機事件。 例如,如果他們在使用計算執行個體中。
建立排程
適用於:Python SDK azure-ai-ml v2 (目前)
from azure.ai.ml.entities import ComputeInstance, ComputeSchedules, ComputeStartStopSchedule, RecurrenceTrigger, RecurrencePattern
from azure.ai.ml.constants import TimeZone
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ci_minimal_name = "ci-name"
ci_start_time = "2023-06-21T11:47:00" #specify your start time in the format yyyy-mm-ddThh:mm:ss
rec_trigger = RecurrenceTrigger(start_time=ci_start_time, time_zone=TimeZone.INDIA_STANDARD_TIME, frequency="week", interval=1, schedule=RecurrencePattern(week_days=["Friday"], hours=15, minutes=[30]))
myschedule = ComputeStartStopSchedule(trigger=rec_trigger, action="start")
com_sch = ComputeSchedules(compute_start_stop=[myschedule])
my_compute = ComputeInstance(name=ci_minimal_name, schedules=com_sch)
ml_client.compute.begin_create_or_update(my_compute)
使用 Resource Manager 範本建立排程
您可以使用 Resource Manager 範本以排程計算執行個體的自動啟動與停止。
在 Resource Manager 範本中新增:
"schedules": "[parameters('schedules')]"
然後使用 cron 或 LogicApps 運算式來定義在您參數檔中啟動或停止執行個體的排程:
"schedules": {
"value": {
"computeStartStop": [
{
"triggerType": "Cron",
"cron": {
"timeZone": "UTC",
"expression": "0 18 * * *"
},
"action": "Stop",
"status": "Enabled"
},
{
"triggerType": "Cron",
"cron": {
"timeZone": "UTC",
"expression": "0 8 * * *"
},
"action": "Start",
"status": "Enabled"
},
{
"triggerType": "Recurrence",
"recurrence": {
"frequency": "Day",
"interval": 1,
"timeZone": "UTC",
"schedule": {
"hours": [17],
"minutes": [0]
}
},
"action": "Stop",
"status": "Enabled"
}
]
}
}
動作的值
Start可以為 或Stop。針對觸發類型的
Recurrence,請使用與 Logic Apps 相同的語法,搭配此 重現性架構。針對
cron的觸發程式類型,請使用標準 cron 語法:// Crontab expression format: // // * * * * * // - - - - - // | | | | | // | | | | +----- day of week (0 - 6) (Sunday=0) // | | | +------- month (1 - 12) // | | +--------- day of month (1 - 31) // | +----------- hour (0 - 23) // +------------- min (0 - 59) // // Star (*) in the value field above means all legal values as in // braces for that column. The value column can have a * or a list // of elements separated by commas. An element is either a number in // the ranges shown above or two numbers in the range separated by a // hyphen (meaning an inclusive range).
Azure 原則支援預設為排程
使用 Azure 原則來強制執行訂用帳戶中每個計算執行個體的關機排程,或如果沒有任何專案存在,則預設為排程。 以下是預設 PST 晚上 10 點的關機排程範例原則:
{
"mode": "All",
"policyRule": {
"if": {
"allOf": [
{
"field": "Microsoft.MachineLearningServices/workspaces/computes/computeType",
"equals": "ComputeInstance"
},
{
"field": "Microsoft.MachineLearningServices/workspaces/computes/schedules",
"exists": "false"
}
]
},
"then": {
"effect": "append",
"details": [
{
"field": "Microsoft.MachineLearningServices/workspaces/computes/schedules",
"value": {
"computeStartStop": [
{
"triggerType": "Cron",
"cron": {
"startTime": "2021-03-10T21:21:07",
"timeZone": "Pacific Standard Time",
"expression": "0 22 * * *"
},
"action": "Stop",
"status": "Enabled"
}
]
}
}
]
}
}
}
代表其他人建立
身為管理員,您可以代表資料科學家建立計算執行個體,並將使用以下方式將執行個體指派給他們:
工作室,使用本文中的安全性設定。
Azure Resource Manager 範本。 如需有關如何尋找此範本所需 TenantID 和 ObjectID 的詳細資訊,請參閱尋找驗證設定的識別物件識別碼。 您也可以在 Microsoft Entra 系統管理中心找到這些值。
為了進一步增強安全性,當您代表資料科學家建立計算執行個體,並將執行個體指派給他們時,如果計算執行個有設定指令碼或自訂應用程式,則將會在建立期間停用單一登入 (SSO)。
指派的使用者在被指派計算實例後,必須自行在計算實例上更新 SSO 設定以啟用 SSO。 指派的使用者必須在其角色中具有下列許可權/動作: MachineLearningServices/workspaces/computes/enableSso/action。 指派的使用者不需要計算寫入 (建立) 權限即可啟用 SSO。
以下是指派的使用者需要採取的步驟。 請注意,基於安全理由,不允許運算執行處理的建立者在該運算執行處理上啟用 SSO。
選擇 Azure Machine Learning Studio 左窗格中的 計算。
選取您需要啟用 SSO 的運算執行處理名稱。
編輯 [單一登錄詳細資料] 區段。

啟用單一登入切換。
儲存。 更新會需要一些時間。
指派受控識別
您可以為計算執行個體指派系統或使用者指派的受控識別,並驗證儲存體等其他 Azure 資源。 使用受控識別進行驗證,有助改善工作區安全性和管理。 例如,您可以讓使用者只有在登入計算執行個體後,才能存取定型資料。 或使用一個共同的使用者指派受控識別,來允許存取特定的儲存體帳戶。
重要事項
如果計算執行個體也設定為 [閒置關機],除非受控識別有 Azure Machine Learning 工作區的 [參與者] 存取權,否則計算執行個體不會因為閒置而關機。 如需指派權限的詳細資訊,請參閱管理 Azure Machine Learning 工作區的存取權。
使用 SDK V2 來建立具有系統指派受控識別的計算執行個體:
from azure.ai.ml import MLClient
from azure.identity import ManagedIdentityCredential
client_id = os.environ.get("DEFAULT_IDENTITY_CLIENT_ID", None)
credential = ManagedIdentityCredential(client_id=client_id)
ml_client = MLClient(credential, subscription_id, resource_group, workspace)
您也可以使用 SDK V1:
from azureml.core.authentication import MsiAuthentication
from azureml.core import Workspace
client_id = os.environ.get("DEFAULT_IDENTITY_CLIENT_ID", None)
auth = MsiAuthentication(identity_config={"client_id": client_id})
workspace = Workspace.get("chrjia-eastus", auth=auth, subscription_id=subscription_id, resource_group=resource_group, location="East US")
建立受控識別之後,請在資料存放區的儲存體帳戶上至少將儲存體 Blob 資料讀取者角色授予受控識別。 請參閱 存取儲存體服務。 之後,您處理計算執行個體時,系統會自動使用受控識別驗證資料存放區。
附註
所建立系統受控識別的名稱會採用 Microsoft Entra ID 中的 /workspace-name/computes/compute-instance-name 格式。
您也可以手動使用受控識別來驗證其他的 Azure 資源。 下列範例示範如何使用受控識別,取得 Azure Resource Manager 存取權杖:
import requests
def get_access_token_msi(resource):
client_id = os.environ.get("DEFAULT_IDENTITY_CLIENT_ID", None)
resp = requests.get(f"{os.environ['MSI_ENDPOINT']}?resource={resource}&clientid={client_id}&api-version=2017-09-01", headers={'Secret': os.environ["MSI_SECRET"]})
resp.raise_for_status()
return resp.json()["access_token"]
arm_access_token = get_access_token_msi("https://management.azure.com")
若要搭配受控識別使用 Azure CLI 驗證,請在登入時指定身分識別用戶端識別碼作為使用者名稱:
az login --identity --username $DEFAULT_IDENTITY_CLIENT_ID
附註
嘗試使用受控識別時,您無法使用 azcopy。
azcopy login --identity 無效。
啟用 SSH 存取
SSH 存取預設為停用狀態。 建立之後,無法啟用或停用 SSH 存取。 若您規劃以互動方式使用 VS Code 遠端執行偵錯,請務必啟用存取。
選取 [下一步: 進階設定] 之後:
- 開啟 [啟用 SSH 存取]。
- 在 [SSH 公開金鑰來源] 中,從下拉式清單選取其中一個選項:
- 若您產生新的金鑰組:
- 在 [金鑰組名稱] 中輸入金鑰的名稱。
- 選取 [建立]。
- 選取 [下載私密金鑰並建立計算]。 金鑰通常會下載至 [下載] 資料夾。
- 若您選取 [使用儲存於 Azure 的現有公開金鑰],請搜尋並選取 [已儲存金鑰] 中的金鑰。
- 若您選取 [使用現有的公開金鑰],請以單行格式或多行 PEM 格式提供 RSA 公開金鑰 (開頭為 "ssh-rsa")。 您可以使用 Linux 和 OS X 上的 ssh-keygen,或是 Windows 上的 PuTTYGen 來產生 SSH 金鑰。
- 若您產生新的金鑰組:
稍後設定 SSH 金鑰
儘管建立後無法啟用或停用 SSH,但您可以選擇稍後在啟用 SSH 的計算執行個體上設定 SSH 金鑰。 這可讓您在建立後設定 SSH 金鑰。 若要這樣做,請選取以在計算執行個體上啟用 SSH,然後選取 [稍後設定 SSH 金鑰] 作為 SSH 公開金鑰來源。 建立計算執行個體之後,您可以瀏覽計算執行個體的 [詳細資料] 頁面,然後選取以編輯 SSH 金鑰。 從那裡,您可以新增 SSH 金鑰。
常見使用案例之一是代表其他使用者建立計算執行個體時(請參閱代表他人建立)。 代表其他使用者佈建運算執行處理時,您可以選取 稍後設定 SSH 金鑰,為新的運算執行處理擁有者啟用 SSH。 這可讓運算執行處理的新擁有者在建立運算執行處理並依照上述步驟指派給他們之後,為其新擁有的運算執行處理設定其 SSH 金鑰。
使用 SSH 連線
建立已啟用 SSH 存取的計算之後,請使用下列步驟進行存取。
在您的工作區資源中尋找計算:
- 選取左側的 [計算]。
- 使用頂端的索引標籤來選取 [計算執行個體] 或 [計算叢集],以尋找您的電腦。
在資源清單中選取計算名稱。
尋找連接字串:
針對計算執行個體,選取 [詳細資訊] 區段頂端的 [連線]。
![顯示 [詳細資料] 頁面頂端的連線工具的螢幕擷取畫面。](media/how-to-create-attach-studio/details.png?view=azureml-api-2)
針對計算叢集,選取頂端的 [節點],然後在資料表中為您的節點選取 [連接字串]。
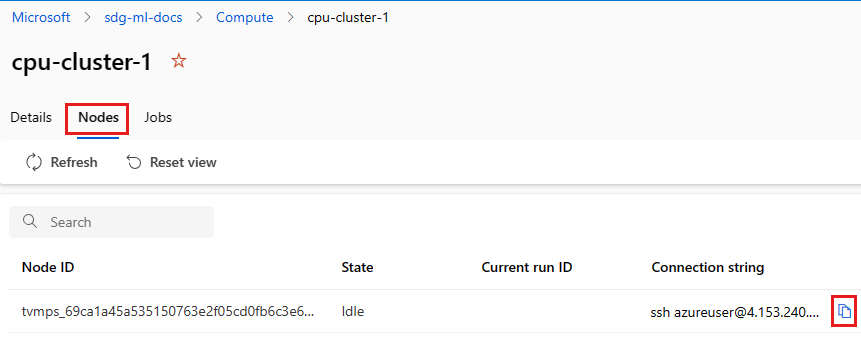
複製連接字串。
針對 Windows,開啟 PowerShell 或命令提示字元:
移至金鑰儲存所在的目錄或資料夾
將 -i 旗標新增至連接字串,以找出私密金鑰並指向其儲存位置:
ssh -i <keyname.pem> azureuser@... (rest of connection string)
針對 Linux 使用者,請遵循在 Azure 中建立和使用 Linux vm 的 SSH 金鑰組中的步驟
若為 SCP,請使用:
scp -i key.pem -P {port} {fileToCopyFromLocal } azureuser@yourComputeInstancePublicIP:~/{destination}
您為其建立計算執行個體的資料科學家需要下列 Azure 角色型存取控制 (Azure RBAC) 權限:
- Microsoft.MachineLearningServices/workspaces/computes/start/action
- Microsoft.MachineLearningServices/workspaces/computes/stop/action
- Microsoft.MachineLearningServices/workspaces/computes/restart/action
- Microsoft.MachineLearningServices/workspaces/computes/applicationaccess/action
- Microsoft.MachineLearningServices/workspaces/computes/updateSchedules/action
資料科學家可以啟動、停止和重新啟動計算執行個體。 他們可將計算執行個體用於:
- Jupyter
- JupyterLab
- RStudio
- Posit Workbench (先前稱為 RStudio Workbench)
- 整合式筆記本
新增自訂應用程式,例如 RStudio 或 Posit Workbench
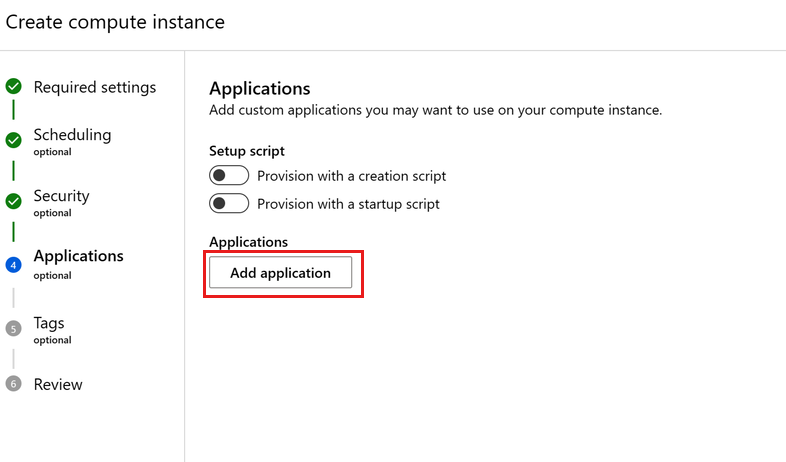
您可以在建立計算執行個體時設定其他應用程式,例如 RStudio 或 Posit Workbench (先前稱為 RStudio Workbench)。 請在 Studio 中遵循下列步驟,在運算執行處理上設定自訂應用程式:
- 填寫表單以建立新的計算執行個體
- 選取 [應用程式]
- 選取 [新增應用程式]
設定 Posit Workbench (先前稱為 RStudio Workbench)
RStudio 是 R 開發人員最愛用來處理 ML 和資料科學專案的 IDE。 您可以使用您自己的 Posit 授權,輕鬆設定 Posit Workbench (提供對 RStudio 和其他開發工具的存取權),以在您的運算執行處理上執行,並存取 Posit Workbench 提供的豐富功能集。
- 請遵循上述步驟,在建立計算執行個體時新增應用程式。
- 在 [應用程式] 下拉式清單中選取 [Posit Workbench (自備授權)],然後在 [授權金鑰] 欄位中輸入 Posit Workbench 授權金鑰。 您可以 從 Posit 取得 Posit Workbench 授權或試用授權。
- 選取 [建立] 將 Posit Workbench 應用程式新增至計算執行個體。

重要事項
如果使用私人連結工作區,請確定您可以存取 Docker 映像、pkg-containers.githubusercontent.com 和 ghcr.io。 此外,請使用範圍 8704-8993 中已發佈的連接埠。 如果是 Posit Workbench (前稱為 RStudio Workbench),請提供 https://www.wyday.com 的網路存取權,以確保授權可供存取。
附註
- 尚未提供從 Posit Workbench 存取工作區檔案存放區的支援。
- 存取 Posit Workbench 的多個執行個體時,如果您看到「400 不正確的要求」。 要求標頭或 Cookie 太大] 錯誤,則請使用新的瀏覽器,或以 incognito 模式從瀏覽器進行存取。
設定 RStudio (開放原始碼)
若要使用 RStudio,請設定自訂應用程式,如下所示:
請遵循先前的步驟,在建立計算執行個體時新增應用程式。
在 [應用程式] 下拉式清單上選取 [自訂應用程式]。
設定您想要使用的 [應用程式名稱]。
將應用程式設定為在 目標埠
8787上執行 - 下列 RStudio 開放原始碼的 Docker 映像必須在此目標埠上執行。設定要在已發佈的連接埠
8787上存取的應用程式 - 您可以視需要將應用程式設定為要在不同的已發佈連接埠上存取。將 Docker 映像指向
ghcr.io/azure/rocker-rstudio-ml-verse:latest。選取 [建立] 以將 RStudio 設定為計算執行個體上的自訂應用程式。

重要事項
如果使用私人連結工作區,請確定您可以存取 Docker 映像、pkg-containers.githubusercontent.com 和 ghcr.io。 此外,請使用範圍 8704-8993 中已發佈的連接埠。 如果是 Posit Workbench (前稱為 RStudio Workbench),請提供 https://www.wyday.com 的網路存取權,以確保授權可供存取。
設定其他自訂應用程式
藉由在 Docker 映像上提供應用程式,在計算執行個體上設定其他自訂應用程式。
- 請遵循先前的步驟,在建立計算執行個體時新增應用程式。
- 在 [應用程式] 下拉式清單中選取 [自訂應用程式]。
- 設定 應用程式名稱、您要執行應用程式的目標 連接埠 、您要存取應用程式的 已發佈連接埠 ,以及包含應用程式的 Docker 映像 。 如果自訂映像儲存在 Azure Container Registry 中,請為應用程式的使用者指派 [參與者] 角色。 如需關於指派角色的詳細資訊,請參閱管理 Azure Machine Learning 工作區存取權。
- 或者,新增您要用於應用程式的 環境變數 。
- 使用 [繫結掛接] 新增預設儲存體帳戶中檔案的存取權:
- 針對 [主機路徑] 指定 /home/azureuser/cloudfiles。
- 針對 [容器路徑] 指定 /home/azureuser/cloudfiles。
- 選取 [新增] 以新增此掛接。 由於檔案已掛接,因此可取得您在其他計算執行個體和應用程式中進行的變更。
- 選取 [建立] 以在計算執行個體上設定自訂應用程式。

重要事項
如果使用私人連結工作區,請確定您可以存取 Docker 映像、pkg-containers.githubusercontent.com 和 ghcr.io。 此外,請使用範圍 8704-8993 中已發佈的連接埠。 如果是 Posit Workbench (前稱為 RStudio Workbench),請提供 https://www.wyday.com 的網路存取權,以確保授權可供存取。
在工作室中存取自訂應用程式
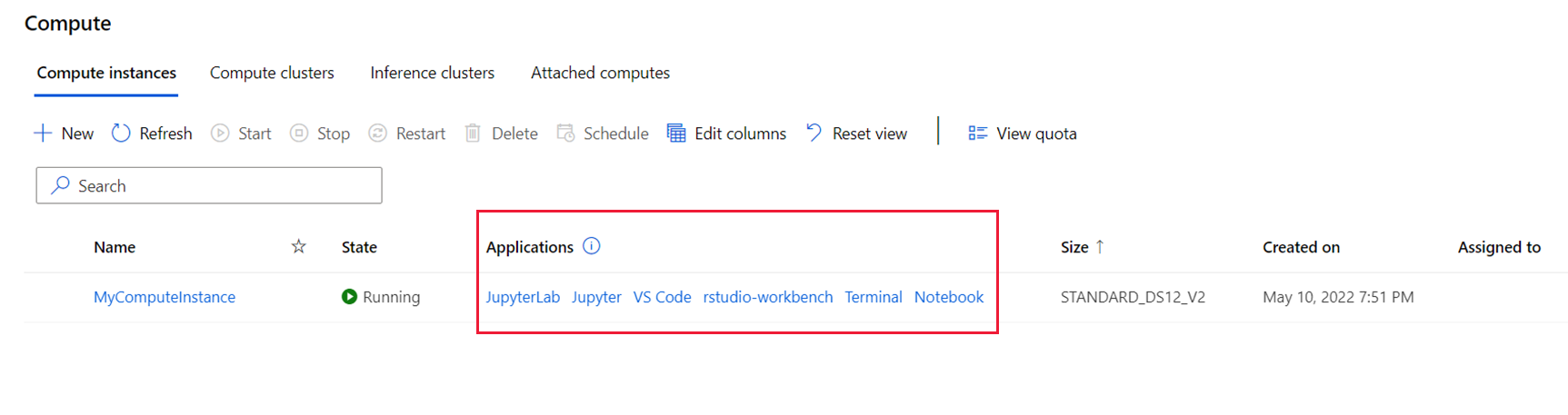
在工作室中存取您所設定的自訂應用程式:
- 選取左側的 [計算]。
- 在 [計算執行個體] 索引標籤上,於 [應用程式] 資料行底下查看您的應用程式。
附註
設定自訂應用程式之後,您可能需要幾分鐘的時間才能透過連結進行存取。 所花費的時間量將取決於用於自訂應用程式的映像大小。 如果您在嘗試存取應用程式時看到 502 錯誤訊息,則請等候一些時間來設定應用程式,然後再試一次。 如果自訂映像是從 Azure Container Registry 提取,您需要工作區的 [參與者] 角色。 如需關於指派角色的詳細資訊,請參閱管理 Azure Machine Learning 工作區存取權。