使用 Azure Machine Learning SDK 建立及執行機器學習管線

在本文中,您將了解如何使用 Azure Machine Learning SDK 來建立及執行機器學習管線。 使用 ML 管線來建立將各種 ML 階段拼接在一起的工作流程。 然後發佈該管線以供稍後存取,或與其他人共用。 追蹤 ML 管線,以查看模型在真實世界中的執行情況,以及偵測資料漂移。 ML 管線適用於 Batch 評分案例,使用各種計算,重複使用步驟,而不是重新執行步驟,以及與其他人共用 ML 工作流程。
本文不是教學課程。 如需有關建立您的第一個管線的指引,請參閱教學課程:建置用於 Batch 評分的 Azure Machine Learning 管線或在 Python 的 Azure Machine Learning 管線中使用自動化 ML。
雖然您可以對 ML 工作的 CI/CD 自動化使用不同類型的管線 (稱為 Azure 管線),但該類型的管線不會儲存在您的工作區中。 比較這些不同的管線。
您建立的 ML 管線將可供您 Azure Machine Learning 工作區的成員檢視。
ML 管線會在計算目標上執行 (請參閱 Azure Machine Learning 中的計算目標是什麼)。 管線可以對支援的 Azure 儲存體位置讀取和寫入資料。
如尚未擁有 Azure 訂用帳戶,請在開始之前先建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
必要條件
Azure Machine Learning 工作區。 建立工作區資源。
設定開發環境以安裝 Azure Machine Learning SDK,或使用已安裝 SDK 的 Azure Machine Learning Compute 執行個體。
從連結您的工作區開始:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
設定機器學習資源
建立執行 ML 管線所需的資源:
設定用來存取管線步驟中所需資料的資料存放區。
設定
Dataset物件,以指向位於資料存放區中或可在資料存放區中存取的持續性資料。 針對在管線步驟之間傳遞的暫存資料設定OutputFileDatasetConfig物件。設定將作為您管線步驟執行位置的計算目標。
設定資料存放區
資料存放區會儲存可供管線存取的資料。 每個工作區都有一個預設的資料存放區。 您可以註冊更多資料存放區。
建立工作區時,依預設會將 Azure 檔案儲存體和 Azure Blob 儲存體連結至該工作區。 已註冊預設資料存放區,以連線到 Azure Blob 儲存體。 若要深入了解,請參閱決定何時使用 Azure 檔案、Azure Blob 或 Azure 磁碟。
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
步驟通常會取用資料並產生輸出資料。 步驟可以建立資料 (例如模型)、含有模型和相依檔案的目錄,或是暫存資料。 此資料接著便可供管線中稍後的其他步驟使用。 若要深入了解如何將管線連接到您的資料,請參閱文章如何存取資料和如何註冊資料集。
使用 Dataset 和 OutputFileDatasetConfig 物件設定資料
將資料提供給管線的偏好方式是 Dataset 物件。 Dataset 物件會指向位於資料存放區中或可從資料存放區存取或位於 Web URL 的資料。 Dataset 類別是抽象的,因此您將會建立一個 FileDataset 執行個體 (參考多個檔案),或一個 TabularDataset 執行個體 (透過具有分隔資料行資料的一或多個檔案建立)。
您可以使用 from_files 或 from_delimited_files 之類的方法來建立 Dataset。
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
中繼資料 (或步驟的輸出) 會由 OutputFileDatasetConfig 物件代表。 output_data1 會隨著步驟的輸出產生。 您可以選擇性地藉由呼叫 register_on_complete,將此資料註冊為資料集。 如果您在一個步驟中建立 OutputFileDatasetConfig,並將它做為另一個步驟的輸入,則步驟之間的該資料相依性會在管線中建立隱含的執行順序。
OutputFileDatasetConfig 物件會傳回目錄,並依預設將輸出寫入工作區的預設資料存放區。
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
重要
使用 OutputFileDatasetConfig 儲存的中繼資料,不會由 Azure 自動刪除。
您應該使用具有短期資料保留原則的資料存放區,以程式設計的方式在管線執行結束時刪除中繼資料,或定期執行手動清理。
提示
只上傳與手邊作業相關的檔案。 在下一次執行管線時,如果資料目錄內的檔案有任何變更,則會視為要重新執行步驟的理由 (即使已指定要重複使用)。
設定計算目標
在 Azure Machine Learning 中,計算一詞 (或計算目標) 係指會在您機器學習管線中執行計算步驟的機器或叢集。 如需完整的計算目標清單,以及了解如何建立這些目標並將其連結至您的工作區,請參閱用於模型定型的計算目標和建立計算目標。 不論您是要將模型定型還是執行管線步驟,建立和/或連結計算目標的程序都相同。 在您建立並連結計算目標之後,請在您的管線步驟中使用 ComputeTarget 物件。
重要
不支援從遠端作業內部對計算目標執行管理作業。 由於機器學習管線會作為遠端作業提交,因此請勿從管線內對計算目標使用管理作業。
Azure Machine Learning Compute
您可以建立用來執行步驟的 Azure Machine Learning Compute。 其他計算目標的程式碼都是類似的,視類型而定,其參數稍有不同。
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
設定定型執行的環境
下一步是確定遠端定型執行具有定型步驟所需的所有相依性。 您可以藉由建立和設定 RunConfiguration 物件來設定相依性和執行階段內容。
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
上述程式碼顯示用於處理相依性的兩個選項。 如所示,使用 USE_CURATED_ENV = True,設定是以策展環境為基礎。 策展環境是「預先製作」,具有常見的相互相依程式庫,而且可以更快速地上線。 策展環境已在 Microsoft Container Registry 中預建 Docker 映像。 如需詳細資訊,請參閱 Azure Machine Learning 策展環境。
將 USE_CURATED_ENV 變更為 False 以顯示明確設定相依性的模式時所採用的路徑。 在該案例中,將會在資源群組內的 Azure Container Registry 中建立並註冊新的自訂 Docker 映像 (請參閱 Azure 中的私人 Docker 容器登錄簡介)。 建立和註冊此映像可能需要幾分鐘的時間。
建構您的管線步驟
建立計算資源和環境之後,就可以開始定義管線的步驟。 您可以透過 Azure Machine Learning SDK 取得許多內建步驟,如您在 azureml.pipeline.steps 套件的參考文件中所見。 最具彈性的類別是 PythonScriptStep,它會執行 Python 指令碼。
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
上述程式碼會顯示典型的初始管線步驟。 您的資料準備程式碼位於子目錄中 (在此範例中為目錄 "./dataprep.src" 中的 "prepare.py")。 在管線建立程序中,此目錄會經過壓縮並上傳至 compute_target,且步驟會執行指定為 script_name 值的指令碼。
arguments 值會指定步驟的輸入和輸出。 在上述範例中,基準資料是 my_dataset 資料集。 對應的資料將會下載至計算資源,因為程式碼會將它指定為 as_download()。 指令碼 prepare.py 會執行任何適用於手邊工作的資料轉換工作,並將資料以類型 OutputFileDatasetConfig 輸出至 output_data1。 如需詳細資訊,請參閱將資料匯入 ML 管線步驟並在其中來回移動 (Python)。
此步驟將使用設定 aml_run_config 在 compute_target 定義的電腦上執行。
在共同作業環境中使用管線時,重複使用先前的結果 (allow_reuse) 是關鍵,因為這可消除不必要的重複執行,進而提供靈活性。 當步驟的 script_name、輸入和參數保持不變時,重複使用是預設行為。 允許重複使用時,會立即將先前執行的結果傳送至下一個步驟。 如果 allow_reuse 設為 False,則在管線執行期間,一律會為此步驟產生新的執行。
您可以使用單一步驟來建立管線,但幾乎一律會選擇將整體程序分成數個步驟。 例如,您可能會有資料準備、定型、模型比較和部署的步驟。 例如,使用者可能會認為在上述指定的 data_prep_step 之後,下一個步驟可能是定型:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
上述程式碼類似於資料準備步驟中的程式碼。 定型程式碼位於與資料準備程式碼不同的目錄中。 資料準備步驟的 OutputFileDatasetConfig 輸出 output_data1 會用來做為定型步驟的輸入。 系統會建立新的 OutputFileDatasetConfig 物件 training_results,以保存結果供稍後比較或部署步驟使用。
如需其他程式碼範例,請參閱如何建置兩個步驟 ML 管線,以及如何在執行完成時將資料寫回資料存放區。
定義步驟之後,您必須使用這些步驟中的部分或全部步驟來建置管線。
注意
當您定義步驟或建置管線時,並不會將任何檔案或資料上傳到 Azure Machine Learning。 呼叫 Experiment.submit() 時會上傳檔案。
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
使用資料集
從 Azure Blob 儲存體、Azure 檔案儲存體、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure SQL Database 和適用於 PostgreSQL 的 Azure 資料庫建立的資料集,可用來作為任何管線步驟的輸入。 您可以將輸出寫入至 DataTransferStep、DatabricksStep,或者,如果您想要將資料寫入至特定資料存放區,請使用 OutputFileDatasetConfig。
重要
只有 Azure Blob、Azure 檔案共用、ADLS Gen 1 和 Gen 2 資料存放區支援使用 OutputFileDatasetConfig 將輸出資料寫回資料存放區。
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
然後,您可以使用 Run.input_datasets 字典來擷取管線中的資料集。
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
行 Run.get_context() 值得注意。 此函式會擷取 Run,表示目前的實驗性執行。 在上述範例中,我們使用它來擷取已註冊的資料集。 Run 物件的另一個常見用法是同時擷取實驗本身和實驗所在的工作區:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
如需詳細資料,包括傳遞和存取資料的替代方式,請參閱將資料匯入 ML 管線步驟並在其中來回移動 (Python)。
快取和重複使用
若要最佳化和自訂管線的行為,您可以在快取和重複使用方面進行一些動作。 例如,您可以選擇:
- 藉由在步驟定義期間設定
allow_reuse=False,關閉步驟執行輸出的預設重複使用。 在共同作業環境中使用管線時,重複使用是關鍵,因為這可消除不必要的執行,進而提供靈活性。 不過,您可以選擇不重複使用。 - 使用
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)對執行中所有步驟強制輸出重新產生
依預設,會啟用 allow_reuse,並且會將步驟定義中指定的 source_directory 雜湊處理。 因此,如果指定步驟的指令碼維持相同 (script_name、輸入和參數),而 source_directory 中沒有任何其他項目變更,則會重複使用先前步驟執行的輸出,作業不會提交至計算,且來自先前執行的結果則會立即改為提供給下一個步驟。
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
注意
如果資料輸入的名稱變更,則該步驟會重新執行,即使基礎資料沒有變更也一樣。 您必須明確地設定輸入資料的 name 欄位 (data.as_input(name=...))。 如果您未明確設定此值,name 欄位將會設定為隨機 GUID,且不會重複使用步驟的結果。
提交管線
提交管線時,Azure Machine Learning 會檢查每個步驟的相依性,並上傳您所指定來源目錄的快照集。 如果未指定來源目錄,則會上傳目前的本機目錄。 快照集也會儲存為工作區中實驗的一部分。
重要
若要避免在快照中包含不必要的檔案,請在目錄中建立忽略檔案 (.gitignore 或 .amlignore)。 將要排除的檔案和目錄新增到這個檔案中。 如需此檔案中可用語法的詳細資訊,請參閱 .gitignore 的語法和模式。 .amlignore 檔案會使用相同的語法。 如果兩個檔案都存在,則會使用 .amlignore 檔案,不會使用 .gitignore 檔案。
如需詳細資訊,請參閱快照集。
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
當您第一次執行管線時,Azure Machine Learning 會:
從與工作區相關的 Blob 儲存體,將專案快照集下載到計算目標。
建置與管線中的每個步驟相對應的 Docker 映像。
從容器登錄將每個步驟的 Docker 映像下載到計算目標。
設定
Dataset和OutputFileDatasetConfig物件的存取權。 針對as_mount()存取模式,會使用 FUSE 來提供虛擬存取。 如果不支援裝載,或使用者將存取指定為as_upload(),則會改為將資料複製到計算目標。在步驟定義中指定的計算目標內執行步驟。
建立步驟所指定的成品,例如記錄、stdout 和 stderr、計量及輸出。 這些成品會接著上傳到使用者的預設資料存放區,並保存在該處。
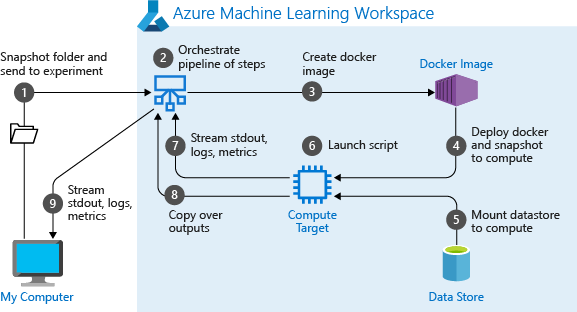
如需詳細資訊,請參閱實驗類別參考。
針對在推斷時變更的引數使用管線參數
有時,管線內個別步驟的引數與開發和定型期間有關:像是定型速率和動量,或是資料或設定檔的路徑。 但是在部署模型時,您會想要動態傳遞您要推斷 (也就是您建置模型要回答的查詢!) 的引數。 您應該讓這些類型的引數成為管線參數。 若要在 Python 中執行此作業,請使用 azureml.pipeline.core.PipelineParameter 類別,如下列程式碼片段所示:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Python 環境如何搭配管線參數使用
如先前在設定定型執行的環境中所述,環境狀態和 Python 程式庫相依性是使用 Environment 物件來指定。 一般而言,您可以透過參考其名稱,並選擇性地指定版本,以指定現有的 Environment:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
但是,如果您選擇在執行階段針對管線步驟使用 PipelineParameter 物件來動態設定變數,您就無法使用參考現有 Environment 的此技術。 相反地,如果您想要使用 PipelineParameter 物件,則必須將 RunConfiguration 的 environment 欄位設定為 Environment 物件。 您必須負責確保這類 Environment 對外部 Python 套件的相依性已正確設定。
檢視管線的結果
在工作室中查看您所有管線的清單及其執行詳細資料:
在左側選取 [管線],以查看您所有的管線執行。
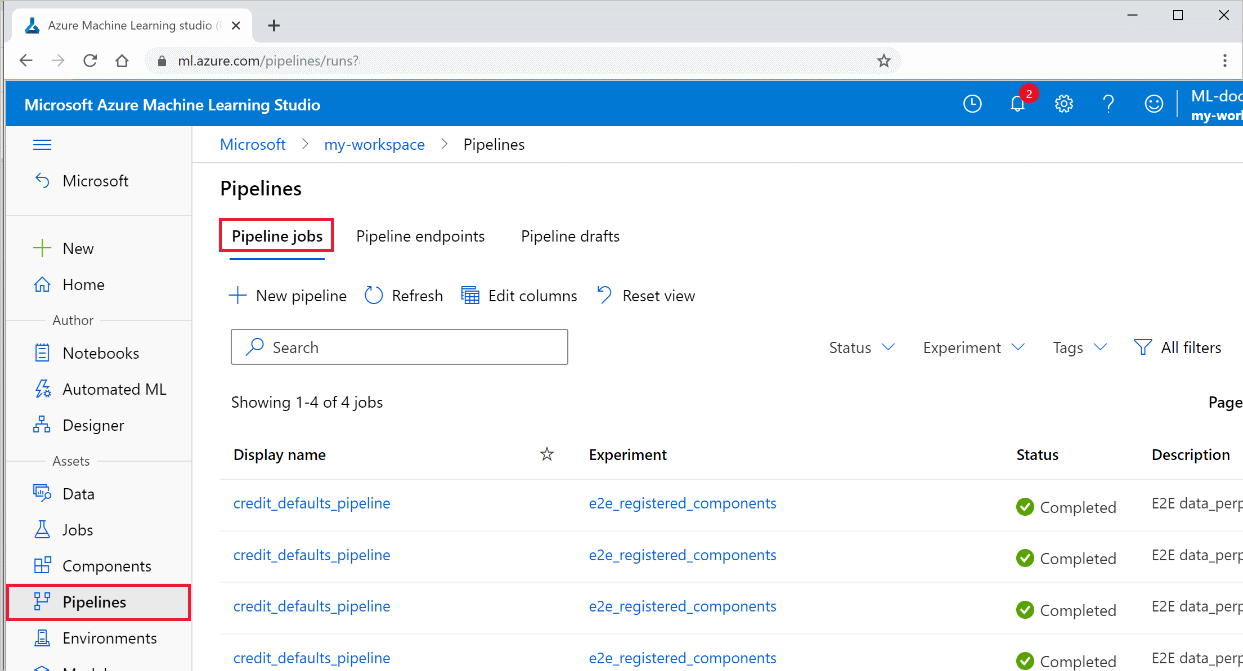
選取特定管線以查看執行結果。
Git 追蹤與整合
當您啟動來源目錄是本機 Git 存放庫的定型回合時,該存放庫的相關資訊會儲存在回合歷程記錄中。 如需詳細資訊,請參閱 Azure Machine Learning 的 Git 整合。
下一步
- 若要與同事或客戶共用您的管線,請參閱發佈機器學習管線
- 使用 GitHub 上的這些 Jupyter Notebook 來進一步探索機器學習管線
- 請參閱 azureml-pipelines-core 套件和 azureml-pipelines-steps 套件的 SDK 參考說明
- 請參閱操作說明,以取得有關偵錯和疑難排解管線的秘訣=
- 了解如何依照使用 Jupyter 筆記本來探索這項服務一文來執行筆記本。