
在本文中,您可了解如何將 MLflow 模型部署至線上端點以進行即時推斷。 當您將 MLflow 模型部署到線上端點時,您不需要指定評分指令碼或環境,此功能稱為無程式碼部署。
針對無程式碼部署,Azure Machine Learning 會:
- 動態安裝您在 conda.yaml 檔案中所列的 Python 套件。 因此,系統會在容器執行階段期間安裝相依性。
- 提供包含下列項目的 MLflow 基底映像或精心挑選的環境:
-
azureml-inference-server-http套件 -
mlflow-skinny套件 - 用於推斷的評分指令碼
-
Prerequisites
Azure 訂用帳戶。 如尚未擁有 Azure 訂用帳戶,請在開始之前先建立免費帳戶。
至少具有下列其中一個 Azure 角色型存取控制 (Azure RBAC) 角色的用戶帳戶:
- Azure Machine Learning 工作區的擁有者角色
- Azure Machine Learning 工作區的參與者角色
- 具有
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*許可權的自定義角色
如需詳細資訊,請參閱 管理 Azure Machine Learning 工作區。
存取 Azure Machine Learning 服務:
安裝 Azure CLI 和 Azure CLI 的
ml延伸模組。 如需安裝步驟,請參閱 安裝和設定 CLI (v2) 。
關於範例
本文中的範例示範如何將 MLflow 模型部署到在線端點,以執行預測。 此範例會使用以糖尿病資料集為基礎的 MLflow 模型。 此數據集包含10個基準變數:年齡、性別、身體質量指數、平均血壓和6個從442名糖尿病患者獲得的血液血清測量。 其也包含感興趣的反應,即一項在基準資料日期後一年所測量的疾病進展量化量值。
模型是使用 scikit-learn 回歸分析器來訓練。 所有必要的前置處理都會封裝為管線,因此此模型是從原始數據到預測的端對端管線。
本文中的資訊是以 azureml-examples 存放庫中的程式碼範例為基礎。 如果您複製存放庫,您可以在本機執行本文中的命令,而不需要複製或貼上 YAML 檔案和其他檔案。 使用下列命令複製存放庫,並移至程式代碼撰寫語言的資料夾:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
在 Jupyter Notebook 中跟著做
若要遵循本文中的步驟,請參閱將 MLflow 模型部署至 範例存放庫中的在線端點筆記本。
連線到您的工作區
線上到您的 Azure Machine Learning 工作區:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<workspace-name> group=<resource-group-name> location=<location>
註冊模型
您只能將已註冊的模型部署到線上端點。 本文中的步驟使用針對糖尿病資料集訓練的模型。 在此案例中,您複製的存放庫中已有模型的本機複本,所以你只要在工作區的登錄中發佈模型即可。 如果您已註冊想要部署的模型,則可以略過此步驟。
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"
![Studio 中 [檢閱] 頁面的螢幕擷取畫面。列出五個上傳的模型檔案,而且會顯示名稱之類的模型設定。](media/how-to-deploy-mlflow-models-online-endpoints/register-model-in-studio.png?view=azureml-api-2#lightbox)
如果您的模型在某次運行中被記錄下來,該怎麼辦?
如果某個執行內已記錄您的模型,則您可以直接註冊該模型。
若要註冊模型,您必須知道其儲存位置:
- 如果您使用 MLflow
autolog功能,模型的路徑取決於模型類型和架構。 檢查作業輸出,以識別模型資料夾的名稱。 此資料夾包含名為 MLModel 的檔案。 - 如果您使用
log_model方法來手動記錄模型,請將路徑傳遞至模型做為該方法的自變數。 例如,如果您使用mlflow.sklearn.log_model(my_model, "classifier")來記錄模型,classifier就是儲存模型的路徑。
您可以使用 Azure Machine Learning CLI v2,從定型作業輸出建立模型。 下列程式代碼會使用標識碼為 $RUN_ID 的作業成品來註冊名為 $MODEL_NAME的模型。
$MODEL_PATH 是作業用來儲存模型的路徑。
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH
![螢幕擷取畫面:Studio 中 [從作業輸出註冊模型] 精靈的 [檢閱] 頁面。會顯示作業名稱和輸出模型檔案。](media/how-to-deploy-mlflow-models-online-endpoints/register-model-review-page.png?view=azureml-api-2#lightbox)
將 MLflow 模型部署到線上端點
使用下列程式代碼來設定您要部署模型之端點的名稱和驗證模式:
執行下列命令來設定端點名稱。 首先,以唯一的名稱取代
YOUR_ENDPOINT_NAME。export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"若要設定您的端點,請建立名為 create-endpoint.yaml 的 YAML 檔案,其中包含下列幾行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: key建立端點:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yaml設定部署。 部署是託管執行實際推斷模型所需的一組資源。
建立名為 sklearn-deployment.yaml 的 YAML 檔案,其中包含下列幾行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Note
僅支援對
scoring_script模型變體自動產生environment和PyFunc。 若要使用不同的模型類別,請參閱 自定義 MLflow 模型部署。建立部署:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficaz ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-traffic將所有流量指派給部署。 到目前為止,端點有一個部署,但不會為其指派任何流量。
如果您在建立期間使用
--all-traffic旗標,則不需要在 Azure CLI 中執行此步驟。 如果您需要變更流量,您可以使用az ml online-endpoint update --traffic命令。 如需如何更新流量的詳細資訊,請參閱 漸進式更新流量。更新端點組態:
如果您在建立期間使用
--all-traffic旗標,則不需要在 Azure CLI 中執行此步驟。 如果您需要變更流量,您可以使用az ml online-endpoint update --traffic命令。 如需如何更新流量的詳細資訊,請參閱 漸進式更新流量。
![Studio 中 [端點] 頁面的螢幕擷取畫面。已醒目提示 [端點] 和 [建立] 按鈕。](media/how-to-deploy-mlflow-models-online-endpoints/create-from-endpoints.png?view=azureml-api-2#lightbox)

叫用端點
當您的部署準備就緒時,您可以使用它來處理請求。 測試部署的其中一種方式是在部署用戶端中使用內建調用功能。 在範例存放庫中,sample-request-sklearn.json 檔案包含下列 JSON 程序代碼。 您可以使用它作為部署的範例要求檔案。
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Note
此檔案使用input_data 金鑰,而不是inputs,後者是 MLflow 服務使用的密鑰。 Azure Machine Learning 需要不同的輸入格式,才能自動產生端點的 Swagger 合約。 如需預期輸入格式的詳細資訊,請參閱 MLflow 內建伺服器與 Azure Machine Learning 推斷伺服器中的部署。
將要求提交至端點:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
回應應該類似下列文字:
[
11633.100167144921,
8522.117402884991
]
Important
在 MLflow 無代碼部署中,目前不支援透過本機端點進行測試。
自訂 MLflow 模型部署
您不需要在 MLflow 模型到線上端點的部署定義中指定評分指令碼。 但是,如果您想要自定義推斷程式,可以指定評分腳本。
在下列情況下,您通常會想要自定義 MLflow 模型部署:
- 模型沒有
PyFunc變體。 - 您必須自定義執行模型的方式。 例如,您必須使用
mlflow.<flavor>.load_model()來使用特定類別來載入模型。 - 您必須在評分例程中執行前置處理或後置處理,因為模型不會執行此處理。
- 模型輸出無法在表格式資料中正確表示。 例如,輸出是代表影像的張量。
Important
如果您指定 MLflow 模型部署的評分腳本,您也必須指定部署執行的環境。
部署自訂評分腳本
若要部署使用自定義評分腳本的 MLflow 模型,請執行下列各節中的步驟。
識別模型資料夾
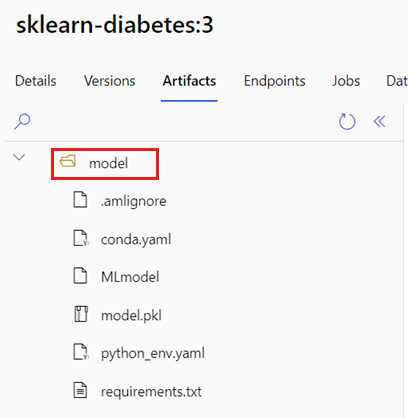
採取下列步驟來識別包含 MLflow 模型的資料夾:
移至 [模型] 區段。
選取您想要部署的模型,然後移至其 [成品] 索引標籤。
記下所顯示的資料夾。 當您註冊模型時,您可以指定此資料夾。

建立評分指令碼
下列評分腳本 score.py 提供如何使用 MLflow 模型執行推斷的範例。 您可以調整此指令碼以符合您的需求,或變更其中任何部分,以反映您的案例。 請注意,您先前識別的資料夾名稱 model,已包含在函數 init() 中。
import logging
import os
import json
import mlflow
from io import StringIO
from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json
def init():
global model
global input_schema
# "model" is the path of the mlflow artifacts when the model was registered. For automl
# models, this is generally "mlflow-model".
model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model")
model = mlflow.pyfunc.load_model(model_path)
input_schema = model.metadata.get_input_schema()
def run(raw_data):
json_data = json.loads(raw_data)
if "input_data" not in json_data.keys():
raise Exception("Request must contain a top level key named 'input_data'")
serving_input = json.dumps(json_data["input_data"])
data = infer_and_parse_json_input(serving_input, input_schema)
predictions = model.predict(data)
result = StringIO()
predictions_to_json(predictions, result)
return result.getvalue()
Warning
MLflow 2.0 諮詢:範例評分腳本適用於 MLflow 1.X 和 MLflow 2.X。 不過,這些版本的預期輸入和輸出格式可能會有所不同。 請檢查您的環境定義,以查看您使用的 MLflow 版本。 只有 Python 3.8 和更新版本才支援 MLflow 2.0。
建立環境
下一個步驟是建立您可以執行評分腳本的環境。 因為模型是 MLflow 模型,因此也會在模型套件中指定 conda 需求。 如需 MLflow 模型中所含檔案的詳細資訊,請參閱 MLmodel 格式。 您可以使用 檔案中的 conda 相依性來建置環境。 不過,您也必須包含 azureml-inference-server-http 套件,這是 Azure Machine Learning 中在線部署的必要專案。
您可以建立名為 conda.yaml 的 conda 定義檔案,其中包含下列幾行:
channels:
- conda-forge
dependencies:
- python=3.12
- pip
- pip:
- mlflow
- scikit-learn==1.7.0
- cloudpickle==3.1.1
- psutil==7.0.0
- pandas==2.3.0
- azureml-inference-server-http
name: mlflow-env
Note
此 Conda 檔案的 dependencies 區段包含 azureml-inference-server-http 套件。
使用此 conda 相依性檔案來建立環境:
環境會以內嵌方式建立到部署設定中。
建立部署
在 endpoints/online/ncd 資料夾中,建立部署配置檔deployment.yml,其中包含下列幾行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: sklearn-diabetes-custom
endpoint_name: my-endpoint
model: azureml:sklearn-diabetes@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04
conda_file: sklearn-diabetes/environment/conda.yaml
code_configuration:
code: sklearn-diabetes/src
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
建立部署:
az ml online-deployment create -f endpoints/online/ncd/deployment.yml
![在 Studio 中端點組態頁面的螢幕快照。[更多選項] 按鈕已被標示出來。](media/how-to-deploy-mlflow-models-online-endpoints/select-advanced-deployment-options.png?view=azureml-api-2#lightbox)

為要求提供服務
部署完成時,即可提供要求。 測試部署的其中一種方法是搭配範例要求檔案使用 invoke 方法,例如下列檔案,sample-request-sklearn.json:
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
將要求提交至端點:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
回應應該類似下列文字:
{
"predictions": [
1095.2797413413252,
1134.585328803727
]
}
Warning
MLflow 2.0 諮詢:在 MLflow 1.X 中,回應不包含 predictions 索引鍵。
清除資源
如果您不再需要端點,請刪除其相關聯的資源:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes