管理及增加 Azure Machine Learning 資源的配額和限制
Azure 會使用配額和限制來防止因詐欺而導致的預算超支,並遵循 Azure 的容量條件約束。 當您對生產工作負載進行調整時,請考量這些限制。 在本文中,您會了解:
- 與 Azure Machine Learning 相關的 Azure 資源的預設限制。
- 建立工作區層級配額。
- 檢視您的配額和限制。
- 要求增加配額。
除了管理配額和限制之外,您還可以了解如何規劃和管理 Azure Machine Learning 的成本,或了解 Azure Machine Learning 中的服務限制。
特殊考量
配額會套用至您帳戶中的每個訂用帳戶。 如果您有多個訂用帳戶,則必須要求為每個訂用帳戶增加配額。
配額是對 Azure 資源的信用額度限制,而不是容量保證。 如果您有大規模的容量需求,請連絡 Azure 支援以增加配額。
配額會由訂用帳戶中的所有服務所共用,包括 Azure Machine Learning。 在評估容量時,請計算所有服務的使用量。
注意
Azure Machine Learning 計算是例外。 該計算具有與核心計算配額不同的配額。
預設限制會因供應項目類別類型而異,例如免費試用、隨用隨付和虛擬機器 (VM) 系列 (例如 Dv2、F、G)。
預設資源配額和限制
在本節中,您會了解下列資源的預設和配額和限制上限:
- Azure Machine Learning 資產
- Azure Machine Learning 計算 (包括無伺服器 Spark)
- Azure Machine Learning 共用配額
- Azure Machine Learning 線上端點 (受控和 Kubernetes) 和批次端點
- Azure Machine Learning 管線
- Azure Machine Learning 與 Synapse 整合
- 虛擬機器
- Azure Container Instances
- Azure 儲存體
重要
限制日後有可能會變更。 如需最新資訊,請參閱 Azure Machine Learning 中的服務限制。
Azure Machine Learning 資產
下列有關資產的限制適用於每個工作區。
| 資源 | 上限 |
|---|---|
| 資料集 | 1000 萬 |
| 執行 | 1000 萬 |
| 模型 | 1000 萬 |
| 元件 | 1000 萬 |
| Artifacts | 1000 萬 |
此外,執行階段上限為 30 天,而每次執行記錄的計量數目上限為 100 萬個。
Azure Machine Learning Compute
Azure Machine Learning Compute 對於訂用帳戶中的每個區域允許的核心數目與唯一計算資源數目,均有預設的配額限制。
注意
- 核心數目的配額會依每個 VM 系列和累計核心總計進行分割。
- 每個區域唯一計算資源數目的配額與 VM 核心配額不同,因為它僅適用 Azure Machine Learning 的受控計算資源。
若要提高下列項目的限制,請要求增加配額:
- VM 系列核心配額。 若要深入了解可要求增加配額的 VM 系列,請參閱 Azure 中的虛擬機器大小。 例如,GPU VM 系列的系列名稱開頭為 "N" (例如 NCv3 系列)。
- 訂用帳戶核心配額總計
- 叢集配額
- 本節中的其他資源
可用的資源:
根據您的訂用帳戶供應項目類型而定,每個區域的專用核心數預設限制為 24 到 300 個。 您可以為每個 VM 系列增加每個訂用帳戶的專用核心數目。 特製化的 VM 系列 (例如 NCv2、NCv3 或 ND 系列) 開頭會是預設的零個核心。 GPU 也預設為零核心。
根據您的訂用帳戶供應項目類型而定,每個區域的低優先順序核心數預設限制為 100 到 3,000 個。 您可以增加每個訂用帳戶的低優先順序核心數目,而這是跨 VM 系列的單一值。
每個區域的計算限制總計,針對指定訂用帳戶內的每個區域有 500 個的預設限制,且每個區域最多可增加至上限值 2500 個。 此限制由訓練叢集、計算執行個體和受控線上端點部署共用。 計算執行個體會被視為單一節點叢集,以供配額使用。
下表顯示平台中的其他限制。 請透過技術支援票證來與 Azure Machine Learning 產品小組連絡,以要求例外狀況。
| 資源或動作 | 上限 |
|---|---|
| 每個資源群組的工作區 | 800 |
| 單一 Azure Machine Learning Compute (AmlCompute) 叢集中的節點設定為非啟用通訊的集區 (亦即無法執行 MPI 作業) | 100 個節點,但可設定為最多 65,000 個節點 |
| 單一平行執行步驟中的節點會在 Azure Machine Learning Compute (AmlCompute) 叢集上執行 | 100 個節點,但如果您的叢集設定為根據上述比例調整,則最多可設定為 65,000 個節點 |
| 單一 Azure Machine Learning Compute (AmlCompute) 叢集中的節點設定為已啟用通訊的集區 | 300 個節點,但可設定為最多 4,000 個節點 |
| 單一 Azure Machine Learning Compute (AmlCompute) 叢集中的節點在已啟用 RDMA 的 VM 系列上設定為已啟用通訊的集區 | 100 個節點 |
| 單一 MPI 中的節點會在 Azure Machine Learning Compute (AmlCompute) 叢集上執行 | 100 個節點 |
| 作業存留期 | 21 天1 |
| 低優先順序節點上的作業存留期 | 7 天2 |
| 每個節點的參數伺服器 | 1 |
1 最大存留期是作業開始和完成時之間的持續時間。 已完成的作業會無限期保存。 未在最長存留期內完成的作業資料無法存取。
2 如果有容量限制,則低優先順序節點上的作業可被先佔。 建議您在作業中實作檢查點。
Azure Machine Learning 共用配額
Azure Machine Learning 提供共用配額集區,根據可用性而定,不同區域的使用者可以從中存取配額,以執行有限的時間測試。 特定時間持續時間取決於使用案例。 藉由暫時使用來自配額集區的配額,您不再需要提出短期配額增加的支援票證,或等候您的配額要求獲得核准,才能繼續進行您的工作負載。
使用共用配額集區可以在短時間內執行 Spark 作業,以及測試來自模型目錄的 Llama-2、Phi、Nemotron、Mistral、Dolly 及 Deci-DeciLM 模型的推斷。 您必須先擁有 Enterprise 合約訂用帳戶,才能透過共用配額部署這些模型。 如需如何使用共用配額來部署線上端點的詳細資訊,請參閱如何使用工作室部署基礎模型。
您應該只使用共用配額來建立暫存測試端點,而不是生產端點。 針對生產環境中的端點,您應該藉由提出支援票證來要求專用配額。 共用配額的計費是以使用量為基礎,就像專用虛擬機器系列的計費一樣。 若要退出離開 Spark 作業的共用配額,請填寫 Azure Machine Learning 共用容量配置退出表單。
Azure Machine Learning 線上端點和批次端點
Azure Machine Learning 線上端點和批次端點具有下表說明的資源限制。
重要
這些限制為區域性,表示您可以根據所使用的每個區域使用最多達這些限制。 例如,如果您目前每個訂用帳戶的端點數目限制為 100,則可以在美國東部區域建立 100 個端點、在美國西部區域建立 100 個端點,以及單一訂用帳戶中的其他支援區域中建立 100 個端點。 相同原則適用所有其他限制。
若要判斷端點目前的使用量,請檢視計量。
若要向 Azure Machine Learning 產品小組請求例外處理,請使用端點限制增加中的步驟。
| 資源 | 限制 1 | 允許例外狀況 | 適用於 |
|---|---|---|---|
| 端點名稱 | 端點名稱必須 |
- | 所有端點類型 3 |
| 部署名稱 | 部署名稱必須 |
- | 所有端點類型 3 |
| 每個訂用帳戶的端點數目 | 100 | Yes | 所有端點類型 3 |
| 每個叢集的端點數目 | 60 | - | Kubernetes 線上端點 |
| 每個訂用帳戶的部署數目 | 500 | Yes | 所有端點類型 3 |
| 每個端點的部署數目 | 20 | Yes | 所有端點類型 3 |
| 每個叢集的部署數目 | 100 | - | Kubernetes 線上端點 |
| 每個部署的執行個體數目 | 50 4 | Yes | 受控線上端點 |
| 端點層級的最大要求逾時 | 180 秒 | - | 受控線上端點 |
| 端點層級的最大要求逾時 | 300 秒 | - | Kubernetes 線上端點 |
| 所有部署的端點層級每秒要求總數 | 500 5 | Yes | 受控線上端點 |
| 所有部署的端點層級每秒連線總數 | 500 5 | Yes | 受控線上端點 |
| 所有部署的端點層級作用中連線總數 | 500 5 | Yes | 受控線上端點 |
| 所有部署的端點層級總頻寬 | 5 MBPS 5 | Yes | 受控線上端點 |
1 這是區域限制。 例如,如果端點數目目前的限制為100,您可以在美國東部區域、美國西部區域建立100個端點,以及單一訂用帳戶中其他支持區域中的100個端點。 相同原則適用所有其他限制。
2 單一虛線 (例如,my-endpoint-name) 在端點和部署名稱中可接受。
3 端點和部署可以是不同類型,但限制適用於所有類型的總和。 例如,每個訂用帳戶下的受控線上端點、Kubernetes 線上端點和批次端點的總和,依預設每個區域不能超過 100 個。 同樣地,每個訂用帳戶下受控在線部署、Kubernetes 在線部署和批次部署的總和預設不能超過每個區域 500 個。
4 我們會保留 20% 的額外計算資源來執行升級。 例如,如果您在部署中要求 10 個執行個體,則必須有 12 個的配額。 否則,您會收到錯誤。 有一些 VM SKU 會從額外配額中豁免。 如需配額配置的詳細資訊,請參閱為部署配置的虛擬機器配額。
5 每秒要求數、連線、頻寬等都相關。 如果您要求增加上述任何限制,請確定您一起估計/計算其他相關限制。
為部署配置的虛擬機器配額
針對受控線上端點,Azure Machine Learning 會保留 20% 的計算資源,以在某些 VM SKU 上執行升級。 如果您在部署中要求這些 VM SKU 的指定執行個體數目,則必須有可用的 ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU 配額,以避免收到錯誤。 例如,如果您在部署中要求 10 個 Standard_DS3_v2 VM (隨附四個核心) 執行個體,則應該有 48 個核心 (12 instances * 4 cores) 的配額可供使用。 此額外配額會保留給系統起始的作業,例如操作系統升級和 VM 復原,除非執行這類作業,否則不會產生成本。
有某些 VM SKU 不必額外保留配額。 若要檢視完整清單,請參閱受控線上端點 SKU 清單。 若要檢視使用量並要求增加配額,請參閱在 Azure 入口網站中檢視您的使用量和配額。 若要檢視執行受控線上端點的成本,請參閱檢視受控線上端點的成本。
Azure Machine Learning 管線
Azure Machine Learning 管線有下列限制。
| 資源 | 限制 |
|---|---|
| 管線中的步驟 | 30,000 |
| 每個資源群組的工作區 | 800 |
Azure Machine Learning 與 Synapse 整合
Azure Machine Learning 無伺服器 Spark 可讓您輕鬆存取分散式運算功能,以調整 Apache Spark 作業。 無伺服器 Spark 會使用與 Azure Machine Learning Compute 相同的專用配額。 配額限制可以增加,方法是可以提交支援票證並在「Machine Learning 服務: 虛擬機器配額」類別下,針對 ESv3 系列要求增加配額和限制。
若要檢視配額使用量,請瀏覽至 Machine Learning 工作室,然後選取您想要查看其使用量的訂用帳戶名稱。 選取左面板中的 [配額]。

虛擬機器
每個 Azure 訂用帳戶對於所有服務的虛擬機器數目都有限制。 虛擬機器核心有區域總限制和每個大小系列的區域限制。 這兩項限制會分別強制執行。
例如,請考慮美國東部訂用帳戶的總計 VM 核心限制為 30、A 系列核心限制為 30,和 D 系列核心限制為 30。 此訂用帳戶會允許部署 30 個 A1 VM、30 個 D1 VM,或是兩者的組合,總計不超過 30 個核心。
您無法將虛擬機器的限制提高至高於下表所顯示的值。
| 資源 | 限制 |
|---|---|
| 與 Microsoft Entra 租用戶相關聯的 Azure 訂用帳戶 | 不限定 |
| 每個訂用帳戶的共同管理員 | 不限定 |
| 每個訂用帳戶的資源群組 | 980 |
| Azure Resource Manager API 要求大小 | 4,194,304 個位元組 |
| 每個訂用帳戶的標記1 | 50 |
| 每個訂用帳戶的唯一標籤計算2 | 80,000 |
| 每個位置的訂用帳戶層級部署 | 8003 |
| 訂用帳戶層級部署的位置 | 10 |
1您可以直接將最多 50 個標記套用至一個訂用帳戶。 在訂用帳戶內,每個資源或資源群組也限制為 50 個標籤。 不過,訂用帳戶可包含不限數量的標籤,分散於資源和資源群組間。
2只有當唯一標籤數目為 80,000 或更少時,資源管理員才會傳回訂用帳戶中標籤名稱和值的清單。 唯一標籤是由資源識別碼、標籤名稱和標籤值的組合所定義。 例如,具有相同標籤名稱和值的兩個資源會計算為兩個唯一標籤。 當數目超出 80,000 時,您仍然可以依照標記尋找資源。
3當記錄接近上限時,部署會自動從歷程記錄中刪除。 如需詳細資訊,請參閱 從部署歷程記錄自動刪除。
容器執行個體
如需詳細資訊,請參閱容器執行個體限制。
儲存體
Azure 儲存體的上限是每一訂用帳戶每個區域 250 個儲存體帳戶。 此限制包括 Standard 和 Premium 儲存體帳戶。
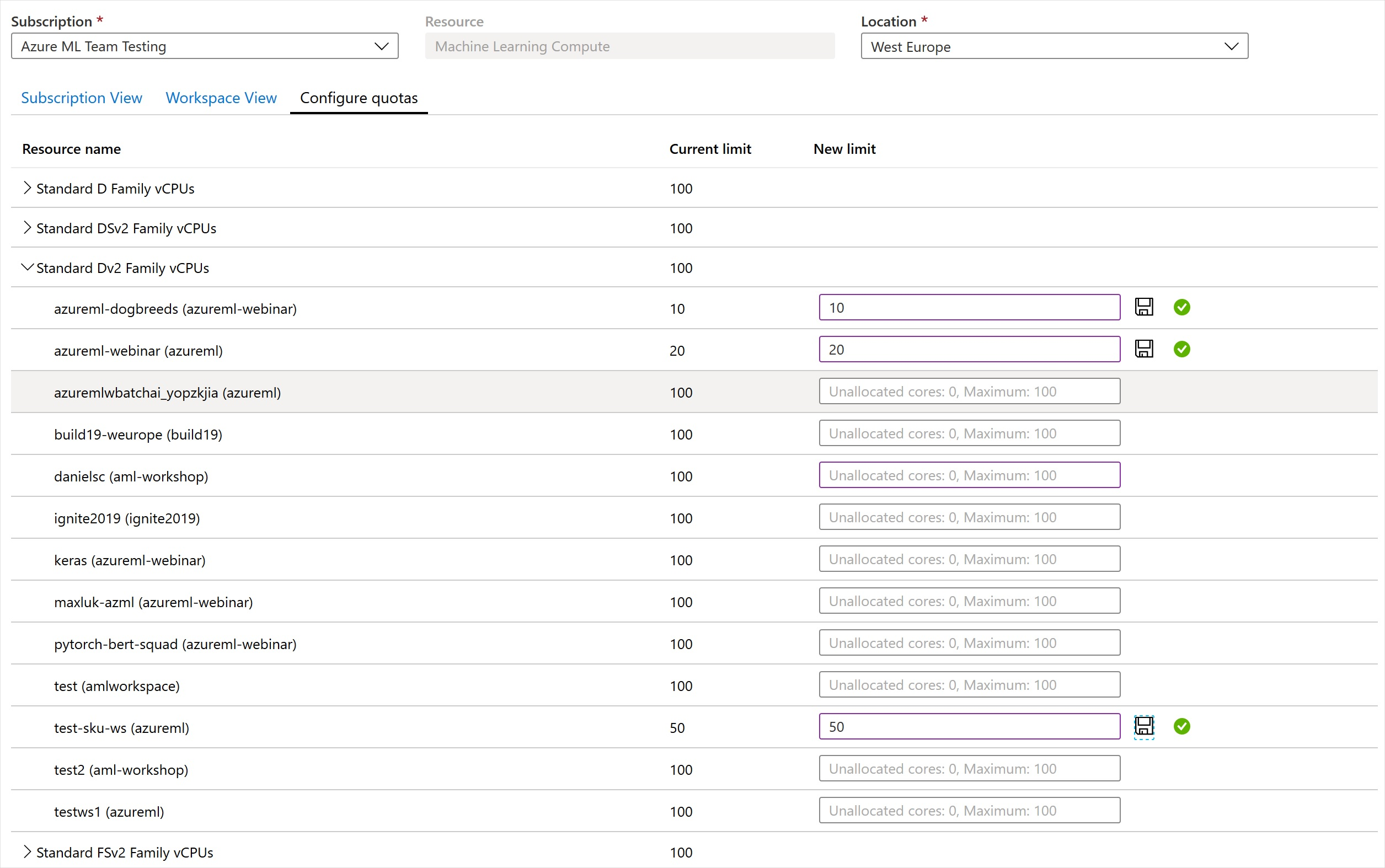
工作區層級配額
使用工作區層級配額來管理相同訂用帳戶中多個工作區之間的 Azure Machine Learning Compute 目標配置。
根據預設,所有工作區會共用與 VM 系列的訂用帳戶層級配額相同的配額。 不過,您可以在訂用帳戶中的工作區上設定個別 VM 系列的最大配額。 個別 VM 系列的配額可讓您共用容量,並避免資源爭用問題。
- 移至您訂用帳戶中的任何工作區。
- 在左側窗格中,選取 [使用量 + 配額]。
- 選取 [設定配額] 索引標籤以檢視配額。
- 展開 VM 系列。
- 在該 VM 系列下所列的任何工作區上設定配額限制。
您無法設定負值或高於訂用帳戶層級配額的值。
注意
您需要訂用帳戶層級的權限,才能在工作區層級上設定配額。
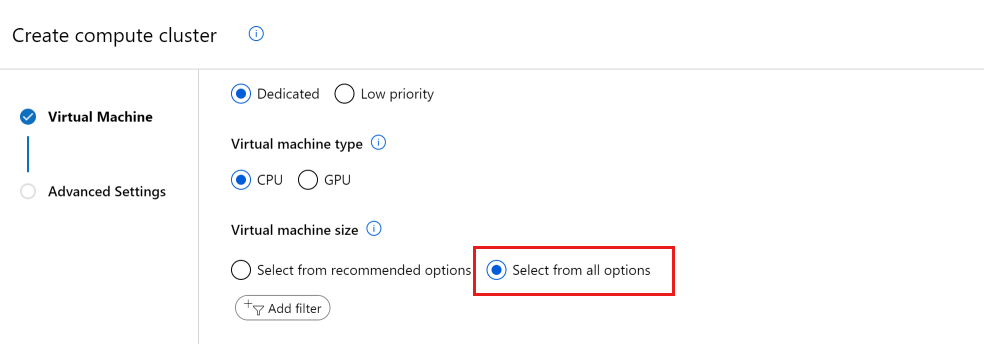
在工作室中檢視配額
當您建立新的計算資源時,預設只會看到您已有配額可用的 VM 大小。 將檢視切換為 [從所有選項選取]。
向下捲動,直到看到您沒有配額的 VM 大小清單為止。
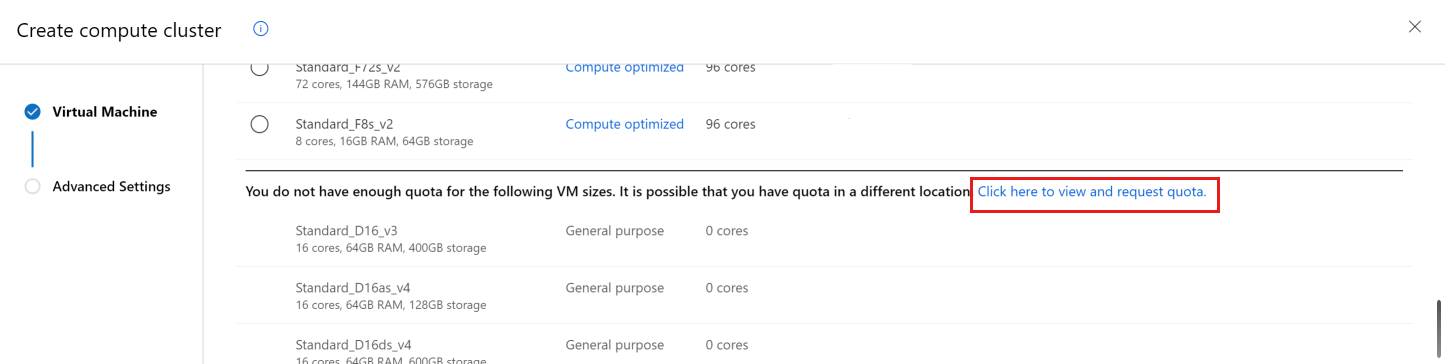
使用連結直接前往線上客戶支援要求,以取得更多配額。
在 Azure 入口網站中檢視您的使用量和配額
若要檢視各種 Azure 資源 (例如虛擬機器、儲存體或網路) 的配額,請使用 Azure 入口網站:
在左窗格中,選取 [所有服務],然後選取 [一般] 類別底下的 [訂用帳戶]。
從訂用帳戶清單中,選取您要尋找其配額的訂用帳戶。
選取 [使用量 + 配額] 以檢視目前配額限制與使用量。 使用篩選來選取提供者和位置。
您可以與其他 Azure 配額分開管理訂用帳戶上的 Azure Machine Learning Compute 配額:
在 Azure 入口網站,移至您的 Azure Machine Learning 工作區。
在左側窗格刀鋒的 [支援 + 疑難排解] 區段下方,選取 [使用量 + 配額],以檢視目前配額限制與使用量。
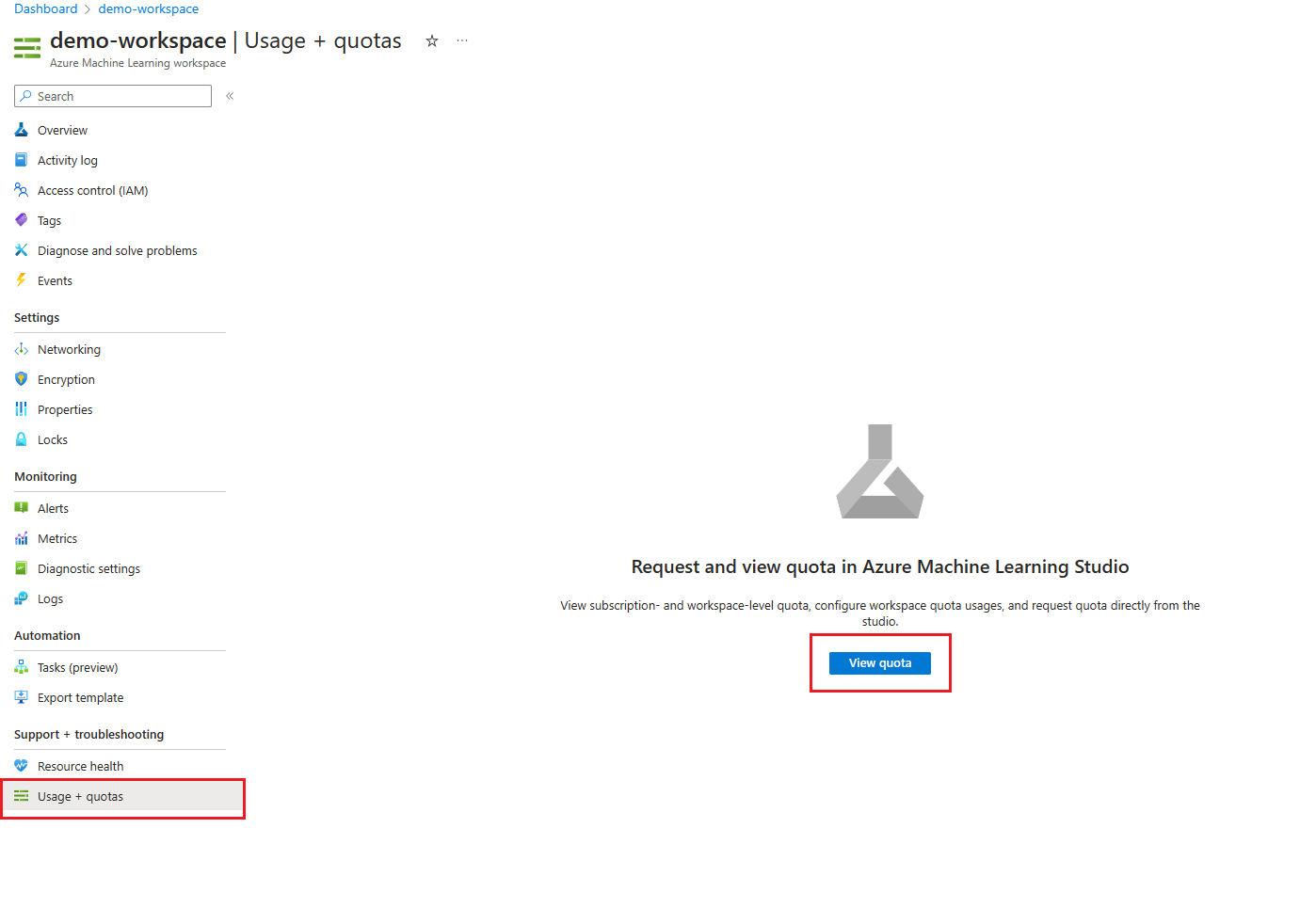
選取訂用帳戶以檢視配額限制。 篩選至您感興趣的區域。
您可以在訂用帳戶層級檢視和工作區層級檢視之間切換。
要求增加配額和限制
VM 配額增加是指提高每個區域每個 VM 系列的核心數。 端點限制增加是指提高每個區域每個訂用帳戶的特定端點限制。 當您提交配額增加要求時,請務必選擇正確的類別,如下一節所述。
VM 配額增加
若要將 Azure Machine Learning VM 配額的限制提高至超過預設限制,您可以從上述 [使用量 + 配額] 檢視要求增加配額,或從 Azure Machine Learning 工作室提交配額增加要求。
遵循上述指示瀏覽至 [使用量 + 配額] 頁面。 檢視目前的配額限制。 選取您想要求增加的 SKU。
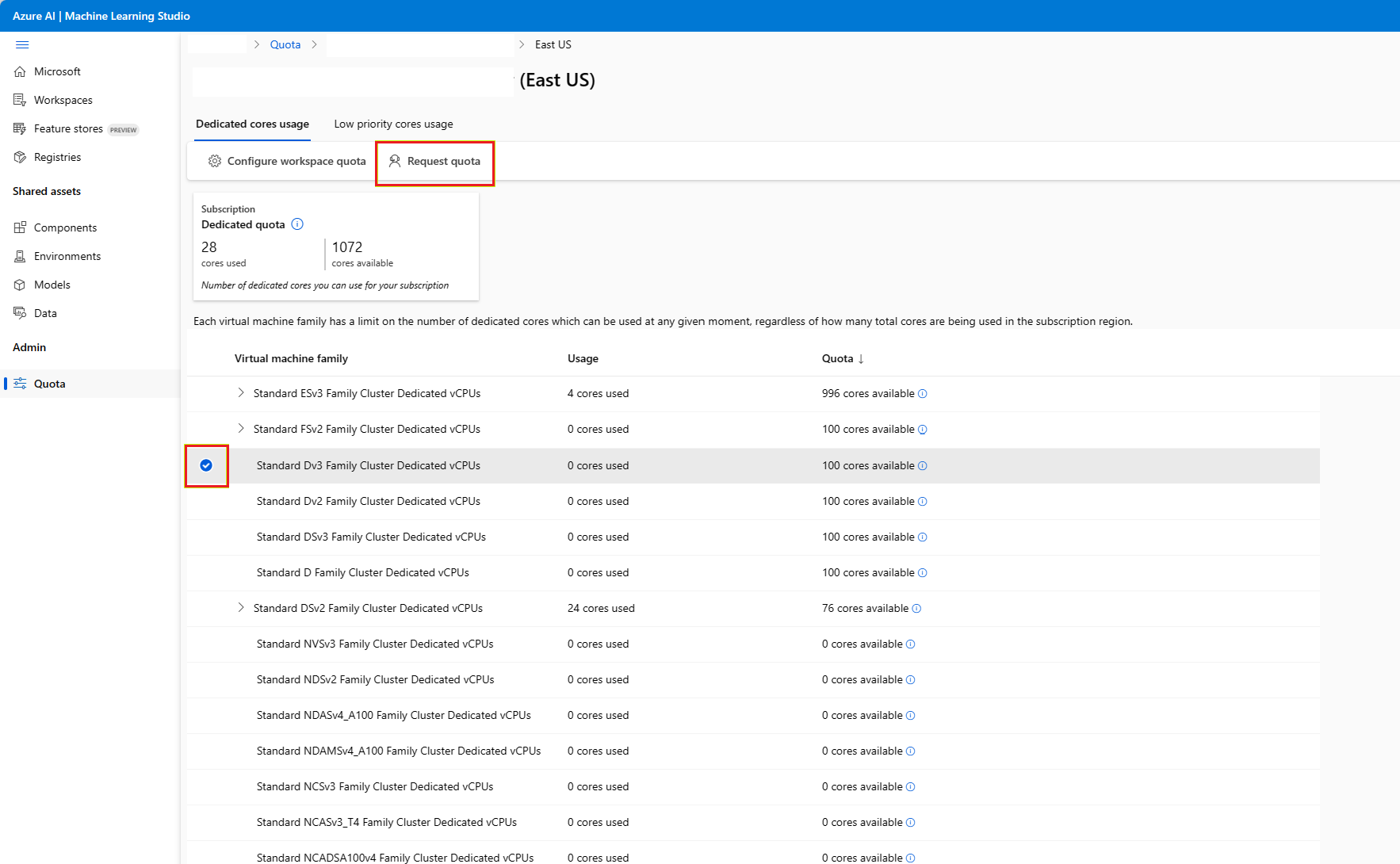
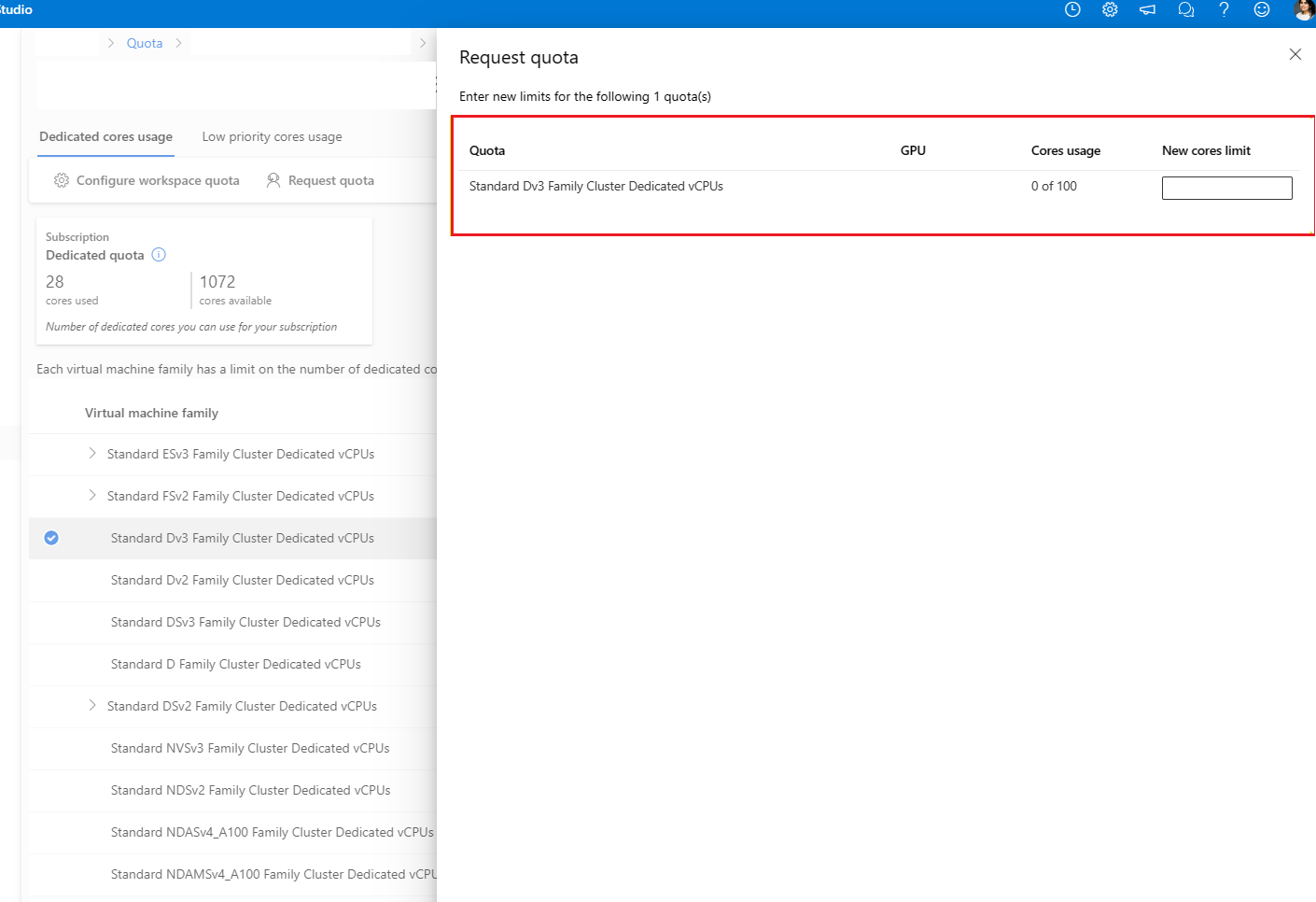
提供您想要增加的配額和新的限制值。 最後,選取 [提交] 以繼續。
端點限制增加
若要提高端點限制,請開啟線上客戶支援要求。 要求增加端點限制時,請提供下列資訊:
開啟支援要求時,請選取 [服務和訂用帳戶限制 (配額)] 作為 [問題類型]。
選取您選擇的訂用帳戶。
選取 [機器學習服務:端點限制] 作為 [配額類型]。
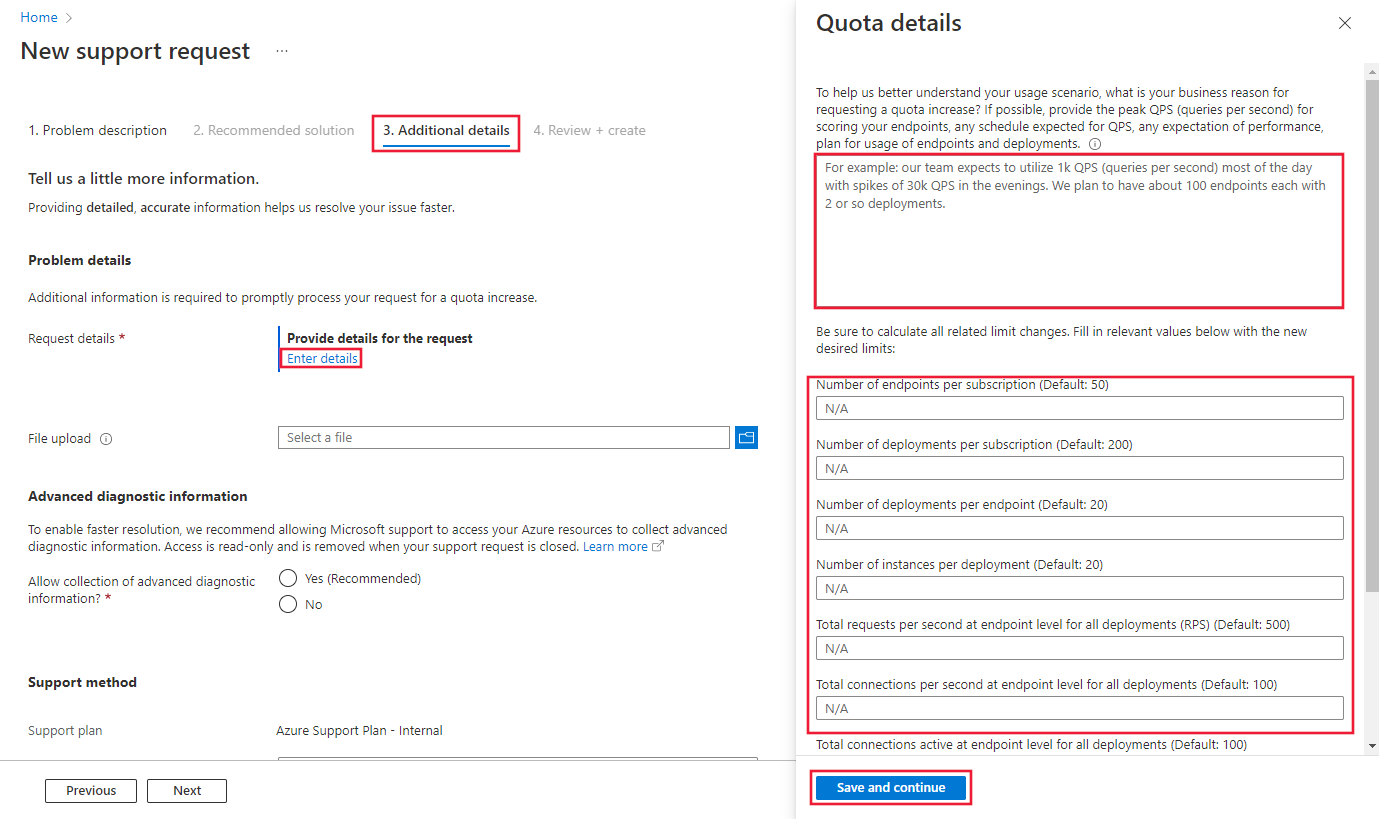
在 [其他詳細資料] 索引標籤上,您必須提供增加限制的詳細原因,才能處理您的要求。 選取 [輸入詳細資料],然後提供您想增加的限制和每個限制的新值、增加限制要求的原因,以及需要增加限制的位置。 請務必將下列資訊新增至限制增加的原因:
- 案例和工作負載的描述 (例如文字、影像等)。
- 要求增加的理由。
- 提供目標輸送量及其模式 (平均/尖峰 QPS、並行使用者)。
- 大規模提供目標延遲,以及您使用單一執行個體觀察到的目前延遲。
- 提供 VM SKU 和執行個體總數,以支援目標輸送量和延遲。 提供您計劃在每個區域中使用多少個端點/部署/執行個體。
- 確認您是否有基準檢驗,指出選取的 VM SKU 和執行個體數目符合輸送量和延遲需求。
- 提供單一承載的承載類型和大小。 網路頻寬應符合每秒的承載大小和要求。
- 提供規劃的時間方案 (當您需要增加限制時 - 盡可能提供分段方案),並確認 (1) 以該規模執行的成本是否反映在預算中,以及 (2) 是否已核准目標 VM SKU。
最後,選取 [儲存並繼續] 以便繼續。
注意
此端點限制增加要求與 VM 配額增加要求不同。 如果您的要求與 VM 配額增加有關,請遵循 VM 配額增加一節中的指示。
計算限制增加
若要增加總計算限制,請開啟線上客戶支援要求。 提供下列資訊:
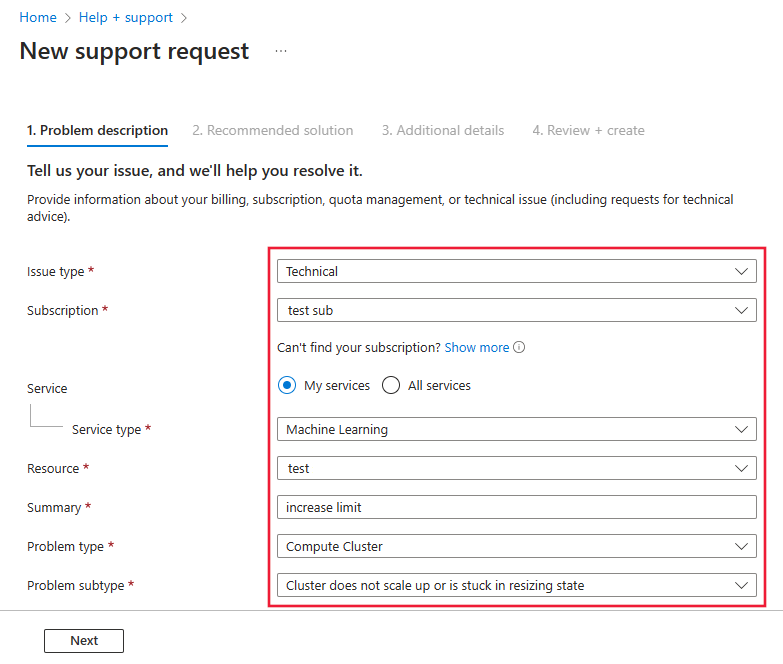
開啟支援要求時,請選取 [技術] 作為 [問題類型]。
選取您選擇的訂閱
選取 [機器學習] 作為 [服務]。
選取您選擇的資源
在摘要中,提及「增加總計算限制」
選取 [計算叢集] 作為 [問題類型],而 叢集不會相應增加或停滯在調整大小作為 [問題子類型]。
在 [其他詳細資料] 索引標籤上,如果您想要增加此區域中的總計算限制,請提供訂用帳戶 ID、區域、新限制 (介於 500 到 2500 之間) 和業務理由。
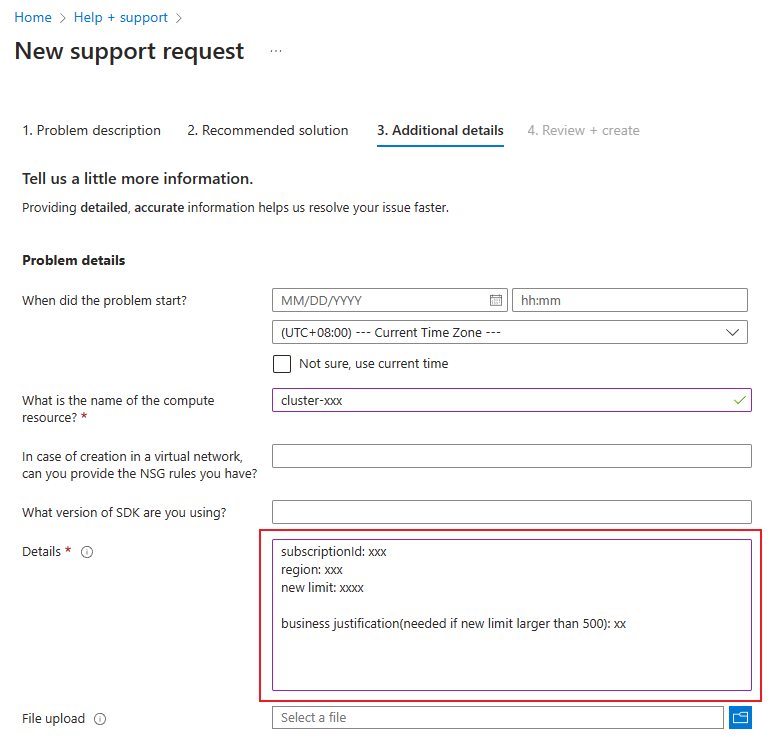
最後,選取 [建立] 以建立支援要求票證。