使用 Azure Machine Learning 大規模將 TensorFlow 模型定型
適用於: Python SDK azure-ai-ml v2 (最新)
Python SDK azure-ai-ml v2 (最新)
在此文章中,了解如何使用 Azure Machine Learning Python SDK v2 大規模執行您的 TensorFlow 定型指令碼。
此文章中的範例程式碼會使用深度神經網路 (DNN) 來將 TensorFlow 模型定型以分類手寫數字,註冊該模型,並將其部署至線上端點。
無論您是從頭開始開發 TensorFlow 模型,或是將現有的模型帶到雲端,您都可以使用 Azure Machine Learning,利用彈性的雲端計算資源來擴增開放原始碼定型作業。 您可以使用 Azure Machine Learning 建立、部署、版本設定和監視生產等級的模型。
必要條件
若要受益於本文,您需要:
- 存取 Azure 訂用帳戶。 如果您還沒有 Azure 訂用帳戶,請建立免費帳戶。
- 使用 Azure Machine Learning 計算執行個體或您自己的 Jupyter Notebook,執行本文中的程式碼:
- Azure Machine Learning 計算執行個體 (不需要下載或安裝)
- 完成開始建立資源教學課程,以建立預先載入 SDK 和範例存放庫的專用筆記本伺服器。
- 在筆記本伺服器上的範例深度學習資料夾中,透過瀏覽至下列目錄來找到完整和擴充的筆記本:v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow。
- 您的 Jupyter 筆記本伺服器
- Azure Machine Learning 計算執行個體 (不需要下載或安裝)
- 下載下列檔案:
- 定型指令碼 tf_mnist.py (英文)
- 評分指令碼 score.py (英文)
- 範例要求檔案 sample-request.json (英文)
您也可以在 GitHub 範例頁面上找到本指南的完整 Jupyter Notebook 版本。
您必須先要求增加工作區的配額,才能執行本文中的程式碼以建立 GPU 叢集。
設定作業
本節透過載入必要的 Python 套件、連線至工作區、建立計算資源來執行命令作業,以及建立環境來執行作業,來設定定型作業。
連線到工作區
首先,您需要連線至您的 Azure Machine Learning 工作區。 Azure Machine Learning 工作區是服務的最上層資源。 其可以在您使用 Azure Machine Learning 時,提供集中式位置以處理您建立的所有成品。
我們正在使用 DefaultAzureCredential 來存取工作區。 此認證應該能夠處理大部分的 Azure SDK 驗證案例。
如果 DefaultAzureCredential 不適用於您,請參閱 azure-identity reference documentation 或 Set up authentication 來取得更多可用的認證。
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()如果您想要使用瀏覽器來登入並驗證,您應該取消註解下列程式碼,並改為使用它。
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
接下來,提供您的訂用帳戶識別碼、資源群組名稱和工作區名稱,以取得工作區的控制碼。 若要尋找這些參數:
- 在 Azure Machine Learning 工作室工具列右上角尋找您的工作區名稱。
- 選取您的工作區名稱以顯示您的資源群組和訂用帳戶識別碼。
- 將資源群組和訂用帳戶識別碼的值複製到程式碼中。
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)執行此腳本的結果是您用來管理其他資源和作業的工作區句柄。
注意
- 建立
MLClient時不會將用戶端連線至工作區。 用戶端初始化作業是緩慢的,會等第一次它所需要的時間到時才會進行呼叫。 在此文章中,這會在計算建立期間發生。
建立計算資源
Azure Machine Learning 需要計算資源才能執行工作。 此資源可以是採用 Linux 或 Windows OS 的單一或多節點機器,或 Spark 之類的特定計算網狀架構。
在下列範例指令碼中,我們會佈建 Linux compute cluster。 您可以查看 Azure Machine Learning pricing 頁面以取得 VM 大小和價格的完整清單。 由於我們需要此範例的 GPU 叢集,因此讓我們挑選 STANDARD_NC6 模型並建立 Azure Machine Learning 計算。
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)建立作業環境
若要執行 Azure Machine Learning 作業,您需要環境。 Azure Machine Learning 環境會封裝相依性 (例如軟體執行時間和程式庫) 在您的計算資源上執行您的機器學習訓練指令碼。 此環境類似於您本機電腦上的 Python 環境。
Azure Machine Learning 可讓您使用策展 (或現成) 的環境 (適用於常見的定型和推斷案例) 或使用 Docker 映像或 Conda 設定建立自訂環境。
在本文中,您會重複使用策劃的 Azure Machine Learning 環境 AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu。 您可以使用 指示詞使用此環境的 @latest 最新版本。
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"設定並提交您的定型作業
在本節中,我們會從介紹用於訓練的資料開始。 接著,我們會說明如何使用我們提供的定型指令碼來執行定型作業。 您將瞭解如何藉由設定執行定型腳本的命令來建置定型作業。 然後,您會提交定型作業,以在 Azure 機器學習 中執行。
取得訓練資料
您將使用來自修改的美國國家標準暨技術研究院 (MNIST) 手寫數字資料庫的資料。 此資料是源自 Yan LeCun 的網站,並儲存在 Azure 儲存體帳戶中。
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"如需 MNIST 資料集的詳細資訊,請瀏覽 Yan LeCun 的網站 (英文)。
建立定型指令碼
在此文章中,我們已提供定型指令碼 tf_mnist.py。 實務上,您應該能夠按原樣採用任何的自訂定型指令碼,並在不需修改程式碼的情況下,使用 Azure Machine Learning 來執行。
所提供的定型指令碼會執行下列動作:
- 處理資料前置處理,將資料分成測試和定型資料;
- 使用資料將模型定型;以及
- 傳回輸出模型。
在管線執行期間,您會使用MLFlow來記錄參數和計量。 若要了解如何啟用 MLFlow 追蹤,請參閱使用 MLflow 追蹤 ML 實驗和模型。
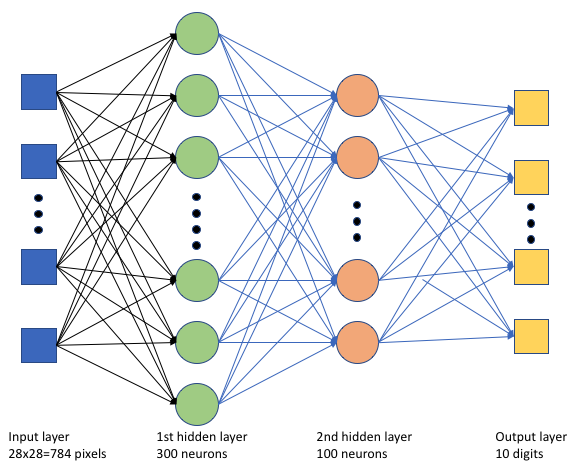
在定型指令碼 tf_mnist.py 中,我們會建立簡單的深度神經網路 (DNN)。 此 DNN 具有:
- 含 28 * 28 = 784 個神經元的輸入層。 每個神經元代表一個影像像素。
- 兩個隱藏層。 第一個隱藏層有 300 個神經元,而第二個隱藏層有 100 個神經元。
- 含 10 個神經元的輸出層。 每個神經元代表一個從 0 到 9 的目標標籤。
建置定型作業
現在您已有執行工作所需的所有資產,接下來即可使用 Azure Machine Learning Python SDK 第 2 版來組建作業。 在這裡範例中,我們會建立 command。
Azure Machine Learning command 是一項資源,指定在雲端中執行定型程式碼所需的所有詳細資料。 這些詳細資料包括輸入和輸出、要使用的硬體類型、要安裝的軟體,以及如何執行程式碼。 command 包含執行單一命令的資訊。
設定命令
您可以使用一般用途 command 來執行定型腳本,並執行所需的工作。 建立 Command 物件以指定定型作業的設定詳細資料。
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)此命令的輸入包括資料位置、批次大小、第一層和第二層的神經元數目,以及學習率。 請注意,我們已直接傳入 Web 路徑作為輸入。
對於參數值:
- 提供您為執行此命令所建立的計算叢集
gpu_compute_target = "gpu-cluster"; - 提供您稍早宣告的策展環境
curated_env_name; - 設定命令列動作本身,在此案例中命令為
python tf_mnist.py。 您可以透過${{ ... }}標記法存取命令中的輸入和輸出;以及 - 設定中繼資料,例如顯示名稱和實驗名稱;其中,實驗是一個在特定專案上執行之所有反復專案的容器。 所有以相同實驗名稱提交的工作,都會在 Azure Machine Learning 工作室中相鄰列出。
- 提供您為執行此命令所建立的計算叢集
在此範例中,您將使用
UserIdentity來執行命令。 使用使用者身分識別表示命令會使用您的身分識別來執行作業,並從 Blob 存取資料。
提交作業
接著即可提交工作,以在 Azure Machine Learning 中執行。 這次,您會對 ml_client.jobs 使用 create_or_update。
ml_client.jobs.create_or_update(job)完成後,工作會在工作區中註冊模型 (作為定型的結果),並輸出可用來在 Azure Machine Learning 工作室中檢視作業的連結。
警告
Azure Machine Learning 藉由複製整個來源目錄來執行定型指令碼。 如果您不想上傳敏感性資料,請使用 .ignore 檔案,或不要將敏感性資料放入來源目錄中。
作業執行期間發生的情況
作業執行時,會經歷下列階段:
準備:根據定義的環境來建置 Docker 映像。 映像上傳至工作區的容器登錄,並快取以供稍後執行。 記錄也會串流至作業歷程記錄,並可檢視以監視進度。 如果指定策展環境,則會使用支援該策展環境的快取映像。
縮放:如果叢集需要更多節點來執行執行比目前可用的節點,則叢集會嘗試擴大規模。
執行中:指令碼資料夾 src 中的所有指令碼都會上傳至計算目標、掛接或複製資料存放區,並執行指令碼。 stdout 和 ./logs 資料夾的輸出都會串流到作業歷程記錄,並且可用來監視作業。
微調模型超參數
既然您已了解如何使用 SDK 執行 TensorFlow 定型執行,讓我們看看您是否可以進一步改善模型的正確性。 您可以使用 Azure Machine Learning 的sweep功能來微調和最佳化模型的超參數。
若要微調模型的超參數,請定義在定型期間搜尋的參數空間。 為此,您將使用來自 azure.ml.sweep 套件的特殊輸入取代傳遞給定型作業的一些參數 (batch_size、first_layer_neurons、second_layer_neurons 和 learning_rate)。
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)然後,您可以使用某些掃掠特定參數,在命令作業上設定掃掠,例如要監看的主要計量,以及要使用的取樣演算法。
在下列程式碼中,我們會使用隨機取樣來嘗試不同的超參數設定組,以嘗試將主要計量 validation_acc 最大化。
我們也會定義提前終止原則 BanditPolicy。 此原則的運作方式是每隔兩次反覆運算便檢查一次作業。 如果主要計量validation_acc、落在前 10% 範圍之外,Azure 機器學習 就會終止作業。 這可避免模型繼續探索無助於達到目標計量的超參數。
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)現在,您可以如先前一樣提交此作業。 這次,您將執行掃掠作業,以掃掠定型作業。
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)您可以使用在作業執行期間呈現的工作室使用者介面連結來監視作業。
尋找並註冊最佳的模型
一旦完成所有執行,您就可以找到產生模型且精確度最高的回合。
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)然後,您可以註冊此模型。
registered_model = ml_client.models.create_or_update(model=model)將模型部署為線上端點
註冊模型之後,您可以將它部署為 在線端點,也就是 Azure 雲端中的 Web 服務。
若要部署機器學習服務,您一般需要:
- 您想要部署的模型資產。 這些資產包括您已在定型作業中註冊的模型檔案和中繼資料。
- 一些要以服務的形式執行的程式碼。 程式碼會在指定的輸入要求 (輸入腳本) 上執行模型。 輸入腳本會接收提交給已部署 Web 服務的資料,並將其傳遞給模型。 模型處理資料之後,指令碼會將模型的回應傳回給用戶端。 指令碼是模型專用的,必須了解模型所預期和傳回的資料。 當您使用 MLFlow 模型時,Azure Machine Learning 會自動為您建立此指令碼。
如需部署的詳細資訊,請參閱使用 Python SDK 第 2 版,搭配受控線上端點部署和評分機器學習模型。
建立新的線上端點
在部署模型的第一個步驟中,您需要建立線上端點。 端點名稱在整個 Azure 區域中必須是唯一的。 在本文中,您會使用通用唯一識別碼 (UUID) 建立唯一名稱。
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")建立端點之後,您可以擷取它,如下所示:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)將模型部署至端點
建立端點之後,您可以使用輸入腳本來部署模型。 一個端點可以有多個部署。 接著,端點就可以使用規則將流量導向這些部署。
在下列程式代碼中,您會建立單一部署,以處理 100% 的連入流量。 我們會使用任意色彩名稱 (tff-blue) 進行部署。 您也可以為部署使用任何的其他名稱,例如 tff-green 或 tff-red。 將模型部署至端點的程式碼會執行下列動作:
- 會部署您稍早註冊之模型的最佳版本;
- 使用
score.py檔案來為模型評分;以及 - 使用 (您先前宣告的) 相同策展環境來執行推斷。
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()注意
預計此部署需要一些時間才能完成。
使用範例查詢測試部署
將模型部署至端點之後,您可以使用端點上的 方法來 invoke 預測已部署模型的輸出。 若要執行推斷,請使用 [request] 資料夾中的範例要求檔案 sample-request.json。
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)您接著可以印出傳回的預測,並將其與輸入影像一起繪製。 使用紅字型色彩和顛倒影像 (黑底白字) 來醒目提示分類錯誤的樣本。
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()注意
由於模型正確性很高,因此您可能必須執行資料格數次,才能看到分類錯誤的樣本。
清除資源
如果您不會使用端點,請將其刪除以停止使用資源。 刪除端點之前,請確定沒有其他部署在使用端點。
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)注意
預期此清除需要一些時間才能完成。
下一步
在此文章中,您已定型並註冊 TensorFlow 模型。 您也已將模型部署至線上端點。 若要深入了解 Azure Machine Learning,請參閱下列其他文章。