如何在您的機器學習管線中使用 Apache Spark (由 Azure Synapse Analytics 提供) (已淘汰)
適用於:  Python SDK azureml v1 (部分機器翻譯)
Python SDK azureml v1 (部分機器翻譯)
警告
Azure Synapse Analytics 與 Python SDK v1 中提供的 Azure Machine Learning 整合已淘汰。 使用者仍然可以使用向 Azure Machine Learning 註冊為連結服務的 Synapse 工作區。 不過,新的 Synapse 工作區無法再向 Azure Machine Learning 註冊為連結服務。 我們建議使用無伺服器 Spark 計算和連結的 Synapse Spark 集區,可在 CLI v2 和 Python SDK v2 中取得。 如需詳細資訊,請瀏覽 https://aka.ms/aml-spark。
在本文中,您會了解如何使用由 Azure Synapse Analytics 支援的 Apache Spark 集區,作為 Azure Machine Learning 管線中資料準備步驟的計算目標。 您會了解單一管線如何使用適合特定步驟的計算資源,例如資料準備或定型。 您也將了解如何為 Spark 步驟準備資料,以及如何將其傳遞至下一個步驟。
必要條件
建立 Azure Machine Learning 工作區以保存您的所有管線資源
設定開發環境以安裝 Azure Machine Learning SDK,或使用已安裝 SDK 的 Azure Machine Learning Compute 執行個體
建立 Azure Synapse Analytics 工作區建和 Apache Spark 集區。 如需詳細資訊,請瀏覽快速入門:使用 Synapse Studio 建立無伺服器 Apache Spark 集區
連結您的 Azure Machine Learning 工作區和 Azure Synapse Analytics 工作區
您會在 Azure Synapse Analytics 工作區中建立及管理您的 Apache Spark 集區。 若要整合 Apache Spark 集區與 Azure Machine Learning 工作區,您必須連結到 Azure Synapse Analytics 工作區。 一旦連結您的 Azure Machine Learning 工作區與 Azure Synapse Analytics 工作區,您即可透過下列項目來連結 Apache Spark 集區:
Python SDK,如稍後所述
Azure Resource Manager (ARM) 範本。 如需詳細資訊,請瀏覽範例 ARM 範本
- 您可以使用命令列,透過下列程式碼範例來遵循 ARM 範本、新增連結服務,以及連結 Apache Spark 集區:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
重要
若要成功連結至 Synapse 工作區,您必須獲授與 Synapse 工作區的擁有者角色。 在 Azure 入口網站中檢查您的存取權。
連結服務會在建立階段取得系統指派的受控識別 (SAI)。 您必須將此連結服務從 Synapse Studio 指派給 SAI「Synapse Apache Spark 管理員」角色,才能提交 Spark 作業 (請參閱如何在 Synapse Studio 中管理 SYNAPSE RBAC 角色指派)。
您也必須從資源管理 Azure 入口網站,為 Azure Machine Learning 工作區的使用者提供「參與者」角色。
擷取 Azure Synapse Analytics 工作區與 Azure Machine Learning 工作區之間的連結
此程式碼示範如何在工作區中擷取連結的服務:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
首先,Workspace.from_config() 使用 config.json 檔案中的組態來存取您的 Azure Machine Learning 工作區。 (如需詳細資訊,請瀏覽建立工作區組態檔)。 然後,程式碼會列印工作區中所有可用的連結服務。 最後,LinkedService.get() 擷取名為 'synapselink1' 的連結服務。
將您的 Apache Spark 集區連結為 Azure Machine Learning 的計算目標
若要使用您的 Apache spark 集區來開啟機器學習管線中的步驟,您必須將其連結為管線步驟的 ComputeTarget,如以下程式碼範例所示:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
程式代碼會先設定 SynapseCompute。 linked_service 引數是您在上一個步驟中建立或擷取的 LinkedService 物件。 type 引數必須是 SynapseSpark。 SynapseCompute.attach_configuration() 中的 pool_name 引數必須符合 Azure Synapse Analytics 工作區中現有的集區。 如需在 Azure Synapse Analytics 工作區中建立 Apache Spark 集區的詳細資訊,請瀏覽快速入門:使用 Synapse Studio 建立無伺服器 Apache Spark 集區。 attach_config 類型為 ComputeTargetAttachConfiguration。
建立組態之後,您可以在機器學習服務工作區中傳遞 Workspace 和 ComputeTargetAttachConfiguration 值,以及您想要用來參考計算的名稱,藉此建立機器學習 ComputeTarget。 對 ComputeTarget.attach() 的呼叫為非同步,因此範例會遭到封鎖,直到呼叫完成為止。
建立使用連結 Apache Spark 集區的 SynapseSparkStep
範例筆記本 Apache Spark 集區上的 Spark 作業會定義簡單的機器學習管線。 首先,筆記本會定義由前一個步驟中所定義 synapse_compute 支援的資料準備步驟。 然後,筆記本會定義定型步驟,其支援的計算目標更適合用於定型。 範例筆記本會使用 Titanic 生存資料庫來顯示資料輸入和輸出。 其實際上不會清除資料或建立預測模型。 由於此範例不會真正涉及定型,因此定型步驟會使用廉價的 CPU 型計算資源。
資料會透過 DatasetConsumptionConfig 物件流入機器學習管線中,這些物件可以保存表格式資料或檔案集。 資料通常來自於工作區資料存放區中 blob 儲存體中的檔案。 此程式碼範例顯示建立機器學習管線輸入的典型程式碼:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
程式碼範例假設檔案 Titanic.csv 位於 blob 儲存體中。 程式碼會示範如何將檔案讀取為 TabularDataset 和 FileDataset。 此程式碼僅供示範用途,因為可能會造成重複輸入的混淆,或是將單一資料來源轉譯為包含資料表的資源且嚴格作為檔案。
重要
若要使用 FileDataset 作為輸入,您需要至少 1.20.0 的 azureml-core版本。 您可使用 Environment 類別來指定此項,如稍後所述。 當步驟完成時,您可以儲存輸出資料,如下列程式碼範例所示:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
在此程式碼範例中,datastore 會將資料儲存在名為 test 的檔案中。 資料會以 Dataset 的形式在機器學習工作區內取得,名稱為 registered_dataset。
除了資料以外,管線步驟可有每個步驟的 Python 相依性。 此外,個別 SynapseSparkStep 物件也可以指定其精確的 Azure Synapse Apache Spark 組態。 若要顯示此項,下列程式碼指定 azureml-core 套件版本必須至少為 1.20.0。 如先前所述,需要 azureml-core 套件的這項需求才能使用 FileDataset 作為輸入。
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
此程式碼會在 Azure Machine Learning 管線中指定一個步驟。 此程式代碼的 environment 值會設定特定的 azureml-core 版本,而且程式碼可以視需要新增其他 conda 或 pip 相依性。
SynapseSparkStep 會壓縮 ./code 子目錄並從本機電腦上傳。 該目錄會在計算伺服器上重新建立,而步驟會從該目錄執行 dataprep.py 指令碼。 該步驟的 inputs 和 outputs 是先前所討論的 step1_input1、step1_input2 和 step1_output 物件。 在 dataprep.py 指令碼內存取這些值的最簡單方式,就是將其與名稱 arguments 產生關聯。
SynapseSparkStep 建構函式的下一組引數控制 Apache Spark。 compute_target 是我們先前連結作為計算目標的 'link1-spark01'。 其他參數則會指定我們想要使用的記憶體和核心。
範例筆記本會使用此程式碼進行 dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
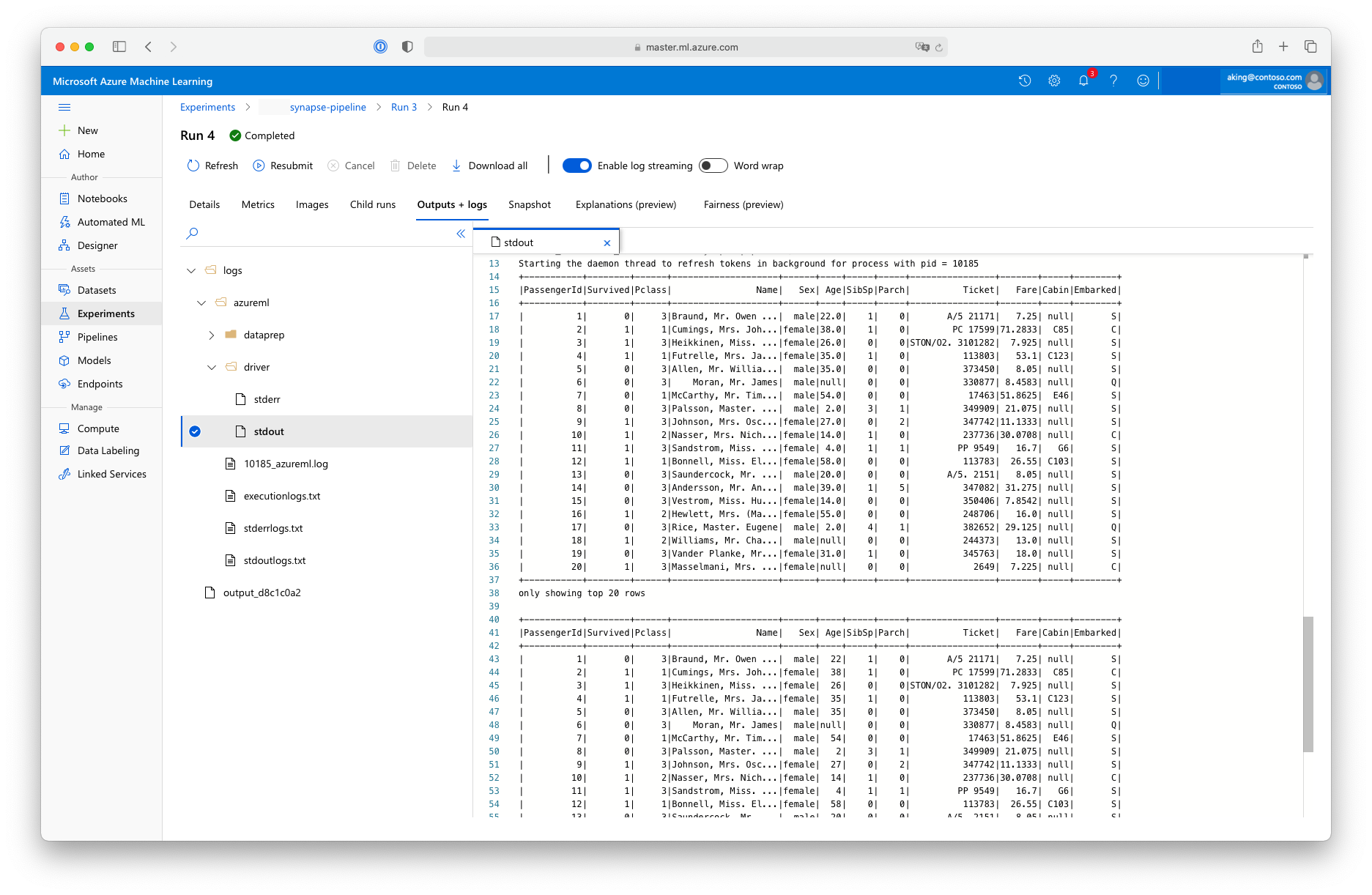
這種「資料準備」指令碼不會進行任何實際資料轉換,而是說明如何擷取資料、將資料轉換成 Spark 資料框架,以及如何進行一些基本的 Apache Spark 操作。 若要在 Azure Machine Learning 工作室中尋找輸出,請開啟子作業、選擇 [輸出 + 記錄] 索引標籤,然後開啟 logs/azureml/driver/stdout 檔案,如以下螢幕擷取畫面所示:
在管線中使用 SynapseSparkStep
下一個範例會使用在先前章節中所建立 SynapseSparkStep 的輸出。 管線中的其他步驟可能會有自己的唯一環境,並在適用於手邊工作的不同計算資源上執行。 範例筆記本會在小型 CPU 叢集上執行「定型步驟」:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
如有必要,此程式碼會建立新的計算資源。 然後,其會將 step1_output 結果轉換成定型步驟的輸入。 as_download() 選項表示資料會移至計算資源,進而加快存取的速度。 如果資料太大而無法放入本機計算硬碟,您必須使用 as_mount() 選項,透過 FUSE 檔案系統來串流資料。 第二個步驟的 compute_target 是 'cpucluster',不是您在資料準備步驟中使用的 'link1-spark01' 資源。 此步驟會使用簡單的 train.py 指令碼,而不是您在上一個步驟中使用的 dataprep.py 指令碼。 範例筆記本有 train.py 指令碼的詳細資料。
在定義所有步驟之後,您就可以建立並執行管線。
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
此程式碼會建立一個管線,其中包含由 Azure Synapse Analytics (step_1) 所支援 Apache Spark 集區上的資料準備步驟,以及定型步驟 (step_2)。 Azure 會檢查步驟之間的資料相依性來計算執行圖形。 在此情況下,只有一個直接的相依性。 在此,step2_input 一定需要 step1_output。
如有必要,對 pipeline.submit 的呼叫會建立名為 synapse-pipeline 的實驗,並且以非同步方式開始執行工作。 管線內的個別步驟會以此主要作業的子作業形式執行,而且 Studio 的 [實驗] 頁面可以監視和檢閱這些步驟。