AI 代理程式藉由結合大型語言模型與外部工具和資料庫,來轉換應用程式與數據互動的方式。 代理程式可自動化複雜的工作流程、增強資訊擷取的正確性,以及輔助資料庫的自然語言介面。
本文探討如何建立智慧型 AI 代理程式,以在 Azure Database for PostgreSQL 中搜尋和分析您的數據。 它會逐步解說使用法律研究助理作為範例的設定、實作和測試。
什麼是 AI 代理程式?
AI 代理程式透過結合 LLM 與外部工具和資料庫,超越簡單的聊天機器人。 與獨立 LLM 或標準檢索增強生成(RAG)系統不同,AI 代理可以:
- 計劃:將複雜工作細分為較小的循序步驟。
- 使用工具:使用 API、程式代碼執行和搜尋系統來收集資訊或執行動作。
- 感知:瞭解和處理來自各種數據源的輸入。
- 請記住:儲存並重新叫用先前的互動,以取得更好的決策。
藉由將 AI 代理程式連線到適用於 PostgreSQL 的 Azure 資料庫等資料庫,代理程式可以根據您的數據提供更精確的內容感知回應。 AI 代理程式超越基本人類對話,以根據自然語言執行工作。 這些工作在傳統上是需要編碼邏輯才能完成的事情。 不過,代理程式可以根據使用者提供的內容來規劃執行所需的工作。
AI 代理程式的實作
使用適用於 PostgreSQL 的 Azure 資料庫實作 AI 代理程式,牽涉到整合進階 AI 功能與健全的資料庫功能,來建立智慧型、具情境感知能力的系統。 透過向量搜尋、嵌入與 Foundry 代理服務等工具,開發者能打造能理解自然語言查詢、擷取相關資料並提供可行洞察的代理。
下列各節概述設定、設定及部署 AI 代理程式的逐步程式。 此程式可讓您在 AI 模型與 PostgreSQL 資料庫之間順暢地互動。
框架
各種架構和工具可輔助開發及部署 AI 代理程式。 所有這些架構都支援使用適用於 PostgreSQL 的 Azure 資料庫作為工具:
實作範例
本文範例使用 代理服務 進行代理規劃、工具使用與感知。 它會使用適用於 PostgreSQL 的 Azure 資料庫作為向量資料庫和語意搜尋功能的工具。
下列各節將逐步引導您建置 AI 代理程式,協助法律小組研究相關案例,以支援其在華盛頓州的客戶。 代理程式:
- 接受有關法律情況的自然語言查詢。
- 使用適用於PostgreSQL的 Azure 資料庫中的向量搜尋來尋找相關的案例先例。
- 分析並以對法律專業人員實用的方式總結結果。
先決條件
啟用和設定
azure_ai和pg_vector延伸模組。部署模型
gpt-4o-mini和text-embedding-small。安裝 Python 延伸模組。
安裝 Python 3.11.x。
安裝 Azure CLI (最新版本)。
備註
您需要您為代理程式建立的已部署模型中的金鑰和端點。
入門指南
此 GitHub 存放庫中提供所有程式代碼和範例數據集。
步驟 1:在適用於 PostgreSQL 的 Azure 資料庫中設定向量搜尋
首先,準備您的資料庫,以使用向量內嵌來儲存和搜尋法律案例數據。
進行環境設定
如果您使用 macOS 和 Bash,請執行下列命令:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
如果您使用 Windows 和 PowerShell,請執行下列命令:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
如果您使用 Windows 和 cmd.exe,請執行下列命令:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
設定環境變數
使用您的認證建立 .env 檔案:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
載入文件和向量
Python 檔案 load_data/main.py 可作為將數據載入適用於 PostgreSQL 的 Azure 資料庫的核心進入點。 程式代碼會處理 範例案例的數據,包括華盛頓案例的相關信息。
main.py 檔案:
- 建立必要的擴充功能、設定 OpenAI API 設定,以及卸除現有的資料庫數據表,並建立新的資料庫數據表來儲存案例數據。
- 從 CSV 檔案讀取數據,並將其插入臨時表,然後將它傳輸到主要案例數據表。
- 在案例表格中新增一個嵌入欄位,並使用OpenAI的API生成案例意見的嵌入。 它會將內嵌儲存在新數據行中。 內嵌程序大約需要 3 到 5 分鐘。
若要啟動資料載入程式,請從 load_data 目錄執行下列命令:
python main.py
以下是main.py的輸出:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
步驟 2:建立代理程式的 Postgres 工具
接下來,設定 AI 代理程式工具以從 Postgres 擷取數據。 接著使用 Agent Service SDK 將你的 AI 代理人連接到 Postgres 資料庫。
定義代理程式呼叫的函式
首先,藉由描述代理程序的結構和 docstring 中的任何必要參數來定義要呼叫的函式。 在單一檔案中包含所有函式定義, legal_agent_tools.py。 然後,您可以將檔案匯入主要腳本。
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
步驟 3:使用 Postgres 建立及設定 AI 代理程式
現在,設定 AI 代理程式,並將其與 Postgres 工具整合。 Python 檔案 src/simple_postgres_and_ai_agent.py 可作為建立和使用代理程式的中央進入點。
simple_postgres_and_ai_agent.py 檔案:
- 用特定模型初始化你的 Foundry 專案中的代理。
- 在代理程式初始化期間,在資料庫上新增適用於向量搜尋的Postgres工具。
- 設定通訊線程。 此線程用來將訊息傳送至代理程式進行處理。
- 使用代理程式和工具處理用戶的查詢。 代理程式可以使用工具來規劃,以取得正確的答案。 在此使用案例中,代理程式會根據函式簽章和 docstring 呼叫 Postgres 工具,以執行向量搜尋並擷取相關數據以回答問題。
- 顯示代理程式對使用者查詢的回應。
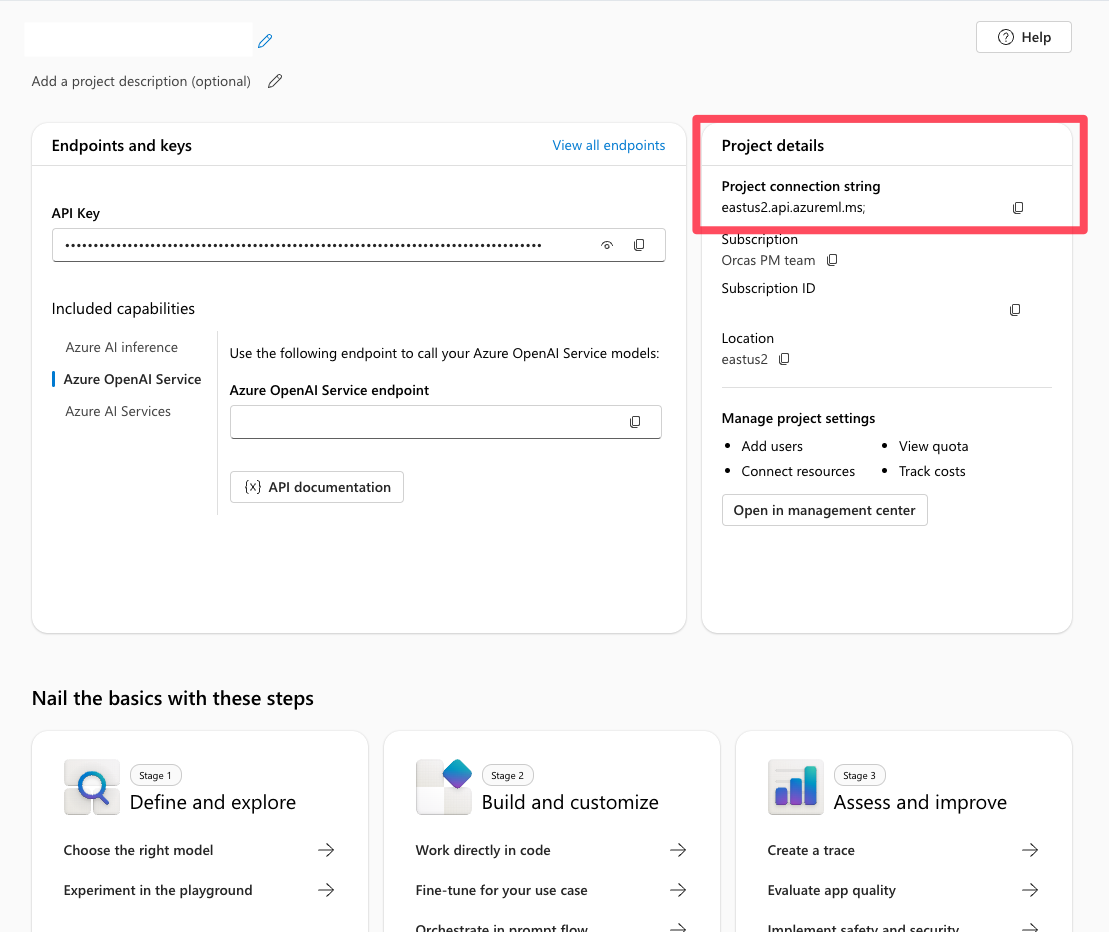
在 Foundry 中尋找專案連接字串
在你的 Foundry 專案中,你可以從專案的總覽頁面找到你的專案連接字串。 你用這個字串將專案連接到代理服務 SDK。 將此字串新增至 .env 檔案。
設定連線
將這些變數新增至根 .env 目錄中的檔案:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
建立通訊線程
此代碼段示範如何建立代理程式線程和訊息,代理程式會在執行中處理:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
處理要求
下列代碼段會建立執行,讓代理程式處理訊息,並使用適當的工具來提供最佳結果。
藉由使用工具,代理程式可以呼叫 Postgres 並透過向量搜尋,針對「水從上方樓層洩漏至公寓」這一查詢擷取所需的數據,以便更好地回答問題。
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
執行代理程式
若要執行代理程式,請從 src 目錄執行下列命令:
python simple_postgres_and_ai_agent.py
代理程式會使用適用於 PostgreSQL 的 Azure 資料庫工具來存取儲存在 Postgres 資料庫中的案例數據,以產生類似的結果。
以下是代理程式輸出的代碼段:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
步驟 4:使用代理程式遊樂場進行測試和偵錯
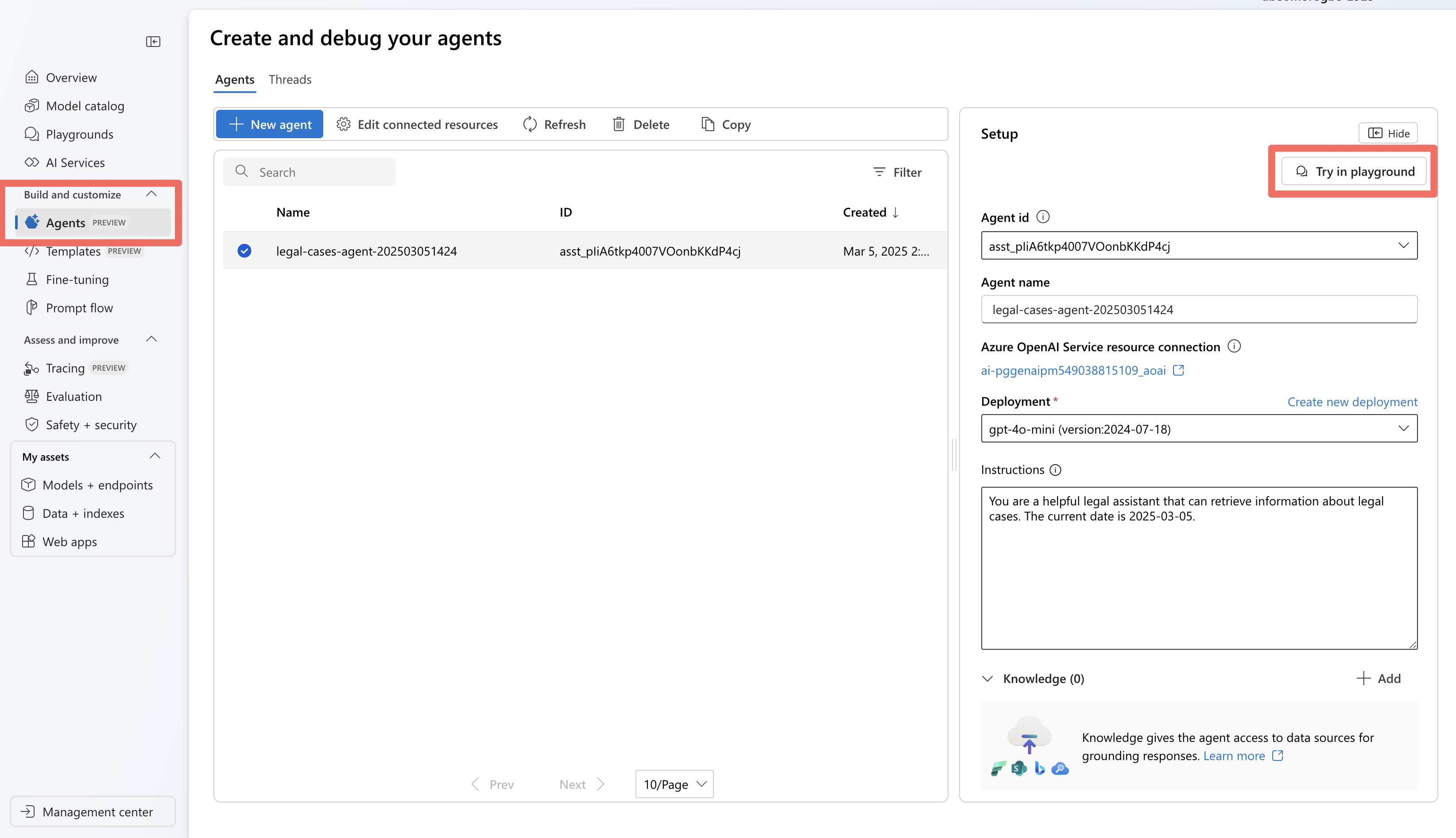
當你使用 Agent Service SDK 執行代理後,代理會被儲存在你的專案中。 您可以在代理程式遊樂場中對該代理程式進行實驗:
在 Foundry 中,前往代理程式區段。
在清單中尋找您的代理程式,然後加以選取以開啟。
使用遊樂場介面來測試各種法律查詢。
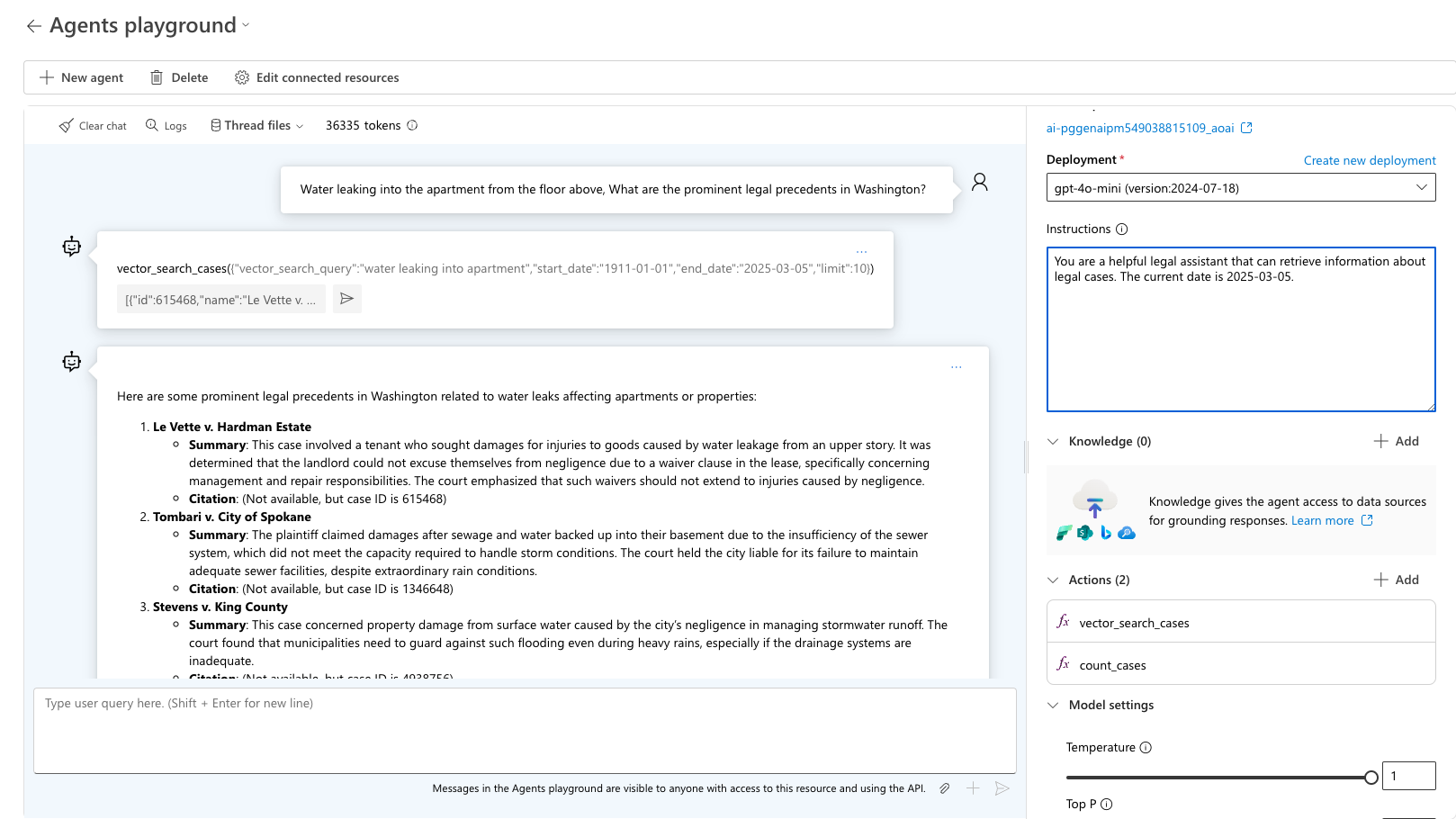
測試查詢「水從樓上的公寓洩漏進來,華盛頓有哪些著名的法律先例?」代理程式會選擇合適的工具,並詢問該查詢的預期結果。 使用 sample_vector_search_cases_output.json 作為範例輸出。
步驟 5:使用 Foundry 的追蹤功能進行除錯
當你使用 Agent Service SDK 開發代理時,可以使用追蹤功能來調試代理。 追蹤可讓您偵錯對 Postgres 等工具的呼叫,並查看代理程式如何協調每個工作。
在Foundry中,前往追蹤。
若要建立新的 Application Insights 資源,請選取 [新建]。 若要連線現有的資源,請在 [Application Insights 資源名稱 ] 方塊中選取一個資源,然後選取 [ 連線]。
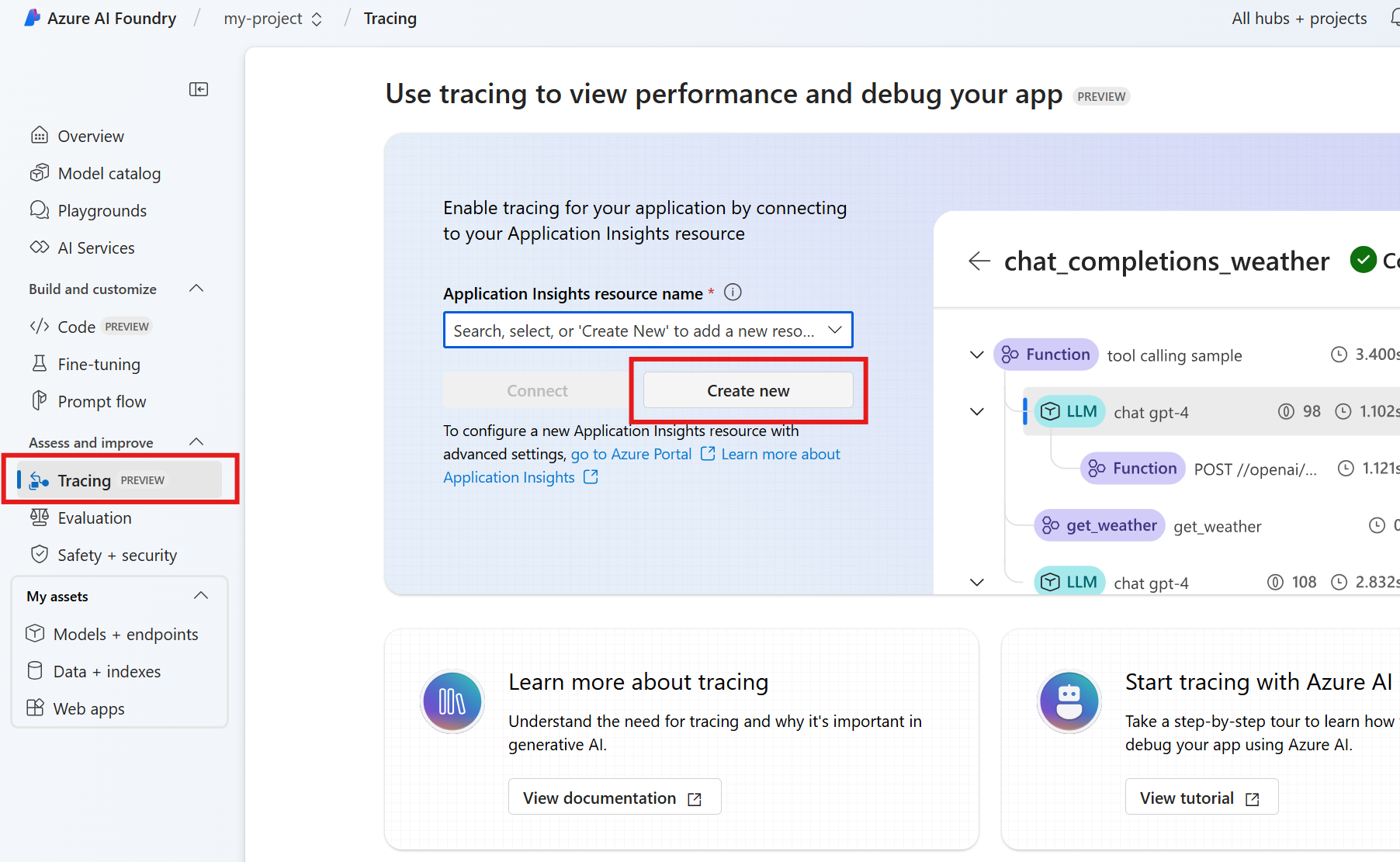
檢視您代理程式作業的詳細追蹤。
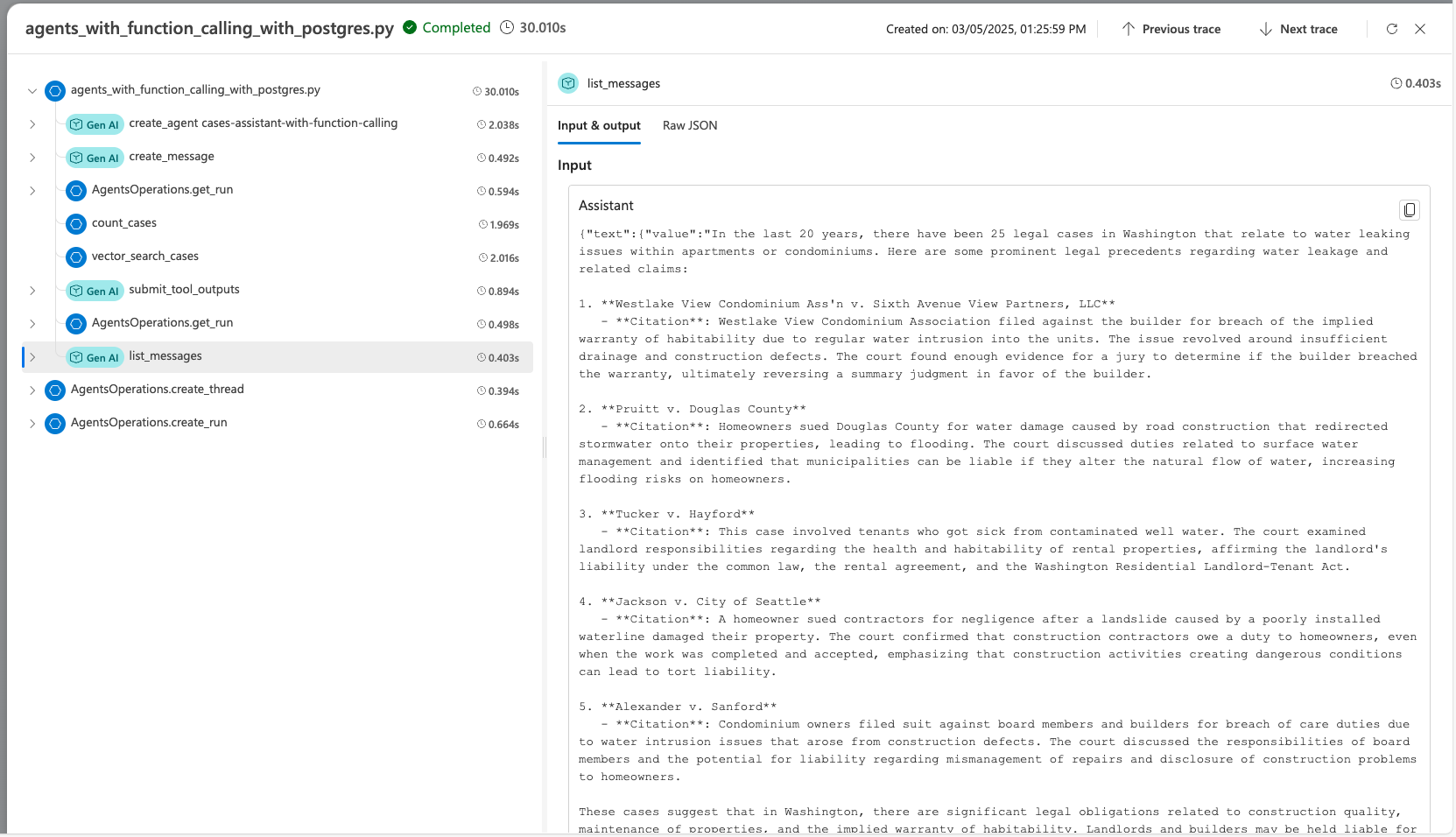
深入瞭解如何在 GitHub 上的 advanced_postgres_and_ai_agent_with_tracing.py 檔案中使用 AI 代理程式和 Postgres 設定追蹤。