瞭解如何使用 適用於 .NET 的 Azure SDK ,在編製索引期間建立內容擷取和轉換的 AI 擴充管線 。
技能組合將人工智慧處理添加於原始內容,使其更一致且易於搜尋。 一旦您知道技能集的運作方式,您就可以支援各種不同的轉換,從影像分析到自然語言處理,到您從外部提供的自定義處理。
在本教學課程中,您會:
- 在擴充管線中定義物件。
- 發展技能 叫用 OCR、語言偵測、實體辨識和關鍵片語擷取。
- 執行管線。 建立及載入搜尋索引。
- 使用全文搜索檢查結果。
概觀
本教學課程使用 C# 和 Azure.Search.Documents 用戶端程式庫來建立資料來源、索引、索引子和技能集。
索引器驅動每一個處理流程的步驟,從 Azure 儲存體上的 Blob 容器中擷取範例資料的內容開始,這些資料包括非結構化的文字和影像。
擷取內容之後,技能集 會從 Microsoft 執行內建技能,以尋找和擷取資訊。 這些技能包括影像上的光學字元辨識 (OCR)、文字的語言偵測、關鍵片語擷取和實體辨識 (組織)。 技能集所建立的新資訊會傳送至索引中的欄位。 一旦填入了索引,您就可以在查詢、Facet 和篩選條件中使用這些欄位。
必要條件
具有有效訂閱的 Azure 帳戶。 免費建立帳戶。
附註
您可以使用免費搜尋服務來進行本教學。 免費層會將您限制為三個索引、三個索引器和三個數據源。 本教學課程會各建立一個。 開始之前,請確定您的服務有空間可接受新的資源。
下載檔案
下載範例資料存放庫的 ZIP 檔案,並擷取內容。 了解作法。
將範例資料上傳至 Azure 儲存體
在 Azure 儲存體中,建立新的容器並命名為 cog-search-demo。
取得儲存體連接字串,以便在 Azure AI 搜尋服務中制訂連線。
在左側,選取 [存取金鑰]。
複製金鑰一或金鑰二的連接字串。 連接字串應類似於下列範例:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI 服務
內建 AI 擴充以 Azure AI 服務為後盾,包括用於自然語言和影像處理的文字分析和 Azure AI 視覺。 針對如本教學課程的小型工作負載,您可以使用每個索引子 20 筆交易的免費配置。 針對較大的工作負載,將 Azure AI Services 多區域資源附加至技能集,以使用標準定價。
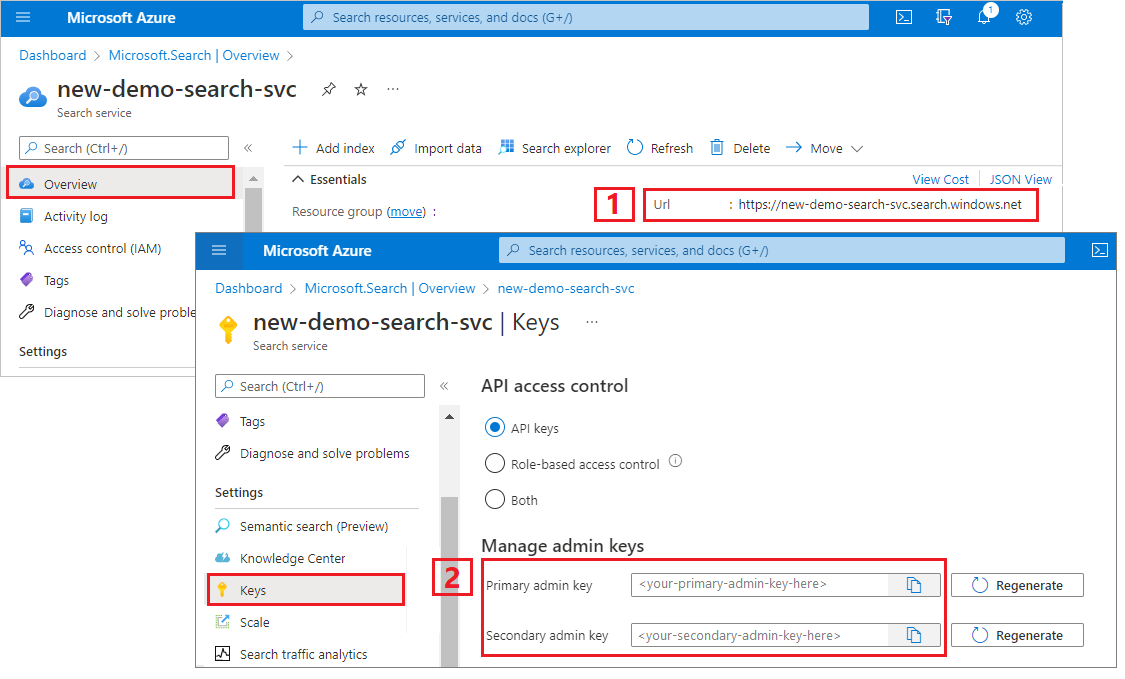
複製搜尋服務 URL 與 API 金鑰
在本教學課程中,Azure AI 搜尋服務的連線需要端點和 API 金鑰。 您可以從 Azure 入口網站取得這些值。
登入 Azure 入口網站,瀏覽至搜尋服務的 [概觀] 頁面,然後複製 URL。 範例端點看起來會像是
https://mydemo.search.windows.net。在 設定>金鑰中,複製系統管理金鑰。 系統管理金鑰可用來新增、修改和刪除物件。 有兩個可交換的系統管理密鑰。 複製其中一個。
設定您的環境
一開始請開啟 Visual Studio,並建立可在 .NET Core 上執行的新主控台應用程式專案。
安裝 Azure.Search.Documents
Azure AI 搜尋服務 .NET SDK 包含用戶端程式庫,可讓您管理索引、資料來源、索引子及技能集,以及上傳和管理文件,還可以執行查詢,而且一律不需要處理 HTTP 和 JSON 的細節。 此用戶端程式庫會以 NuGet 套件的形式散發。
針對此專案,請安裝第 11 版或更新版本的 Azure.Search.Documents 和最新版本的 Microsoft.Extensions.Configuration。
在 Visual Studio 中,依序選取 [工具]>[NuGet 套件管理員]>[管理解決方案的 NuGet 套件]。
選取最新版本,然後選取 [安裝] 。
重複先前的步驟以安裝 Microsoft.Extensions.Configuration 和 Microsoft.Extensions.Configuration.Json。
新增服務連線資訊
在 [方案總管] 中以滑鼠右鍵按一下您的專案,然後選取 [新增]>[新增項目...]。
命名檔案
appsettings.json,並選取 [新增]。將此檔案包含在您的輸出目錄中。
- 以滑鼠右鍵按一下
appsettings.json,然後選取 [屬性]。 - 將 [複製到輸出目錄] 的值變更為 [有更新時才複製]。
- 以滑鼠右鍵按一下
將下列 JSON 複製到新的 JSON 檔案。
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
新增您的搜尋服務與 Blob 儲存體帳戶資訊。 您應該記得,您可以從上一節所指示的服務佈建步驟中取得這項資訊。
針對 SearchServiceUri,輸入完整的 URL。
新增命名空間
在 Program.cs 中,新增下列命名空間。
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
建立用戶端
在 SearchIndexClient 底下建立 SearchIndexerClient 和 Main 的執行個體。
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
附註
用戶端會連線到您的搜尋服務。 為了避免開啟太多連線,您應該在應用程式中儘量共用單一實例,如果可以的話。 方法是可啟用這類共用的安全執行緒。
新增函式以在失敗期間結束程式
本教學課程旨在協助您了解編製索引管線的每個步驟。 如果發生嚴重問題,導致程式無法建立資料來源、技能集、索引或索引子,程式將會輸出錯誤訊息並結束,讓您可以得知並解決問題。
將 ExitProgram 新增至 Main,以處理需要結束程式的案例。
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
建立管線
在 Azure AI 搜尋服務中,AI 處理會在編製索引 (或資料內嵌) 期間進行。 逐步解說的這個部分會建立四個物件:資料來源、索引定義、技能集、索引子。
步驟 1:建立資料來源
SearchIndexerClient 具有 DataSourceName 屬性,您可以將其設定為 SearchIndexerDataSourceConnection 物件。 此物件會提供您建立、列出、更新或刪除 Azure AI 搜尋服務資料來源所需的所有方法。
呼叫 SearchIndexerDataSourceConnection 來建立新的 indexerClient.CreateOrUpdateDataSourceConnection(dataSource) 執行個體。 下列程式碼會建立 AzureBlob 類型的資料來源。
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
如果要求成功,方法會傳回已建立的資料來源。 如果要求發生問題 (例如無效的參數),則方法會擲回例外狀況。
現在,在 Main 中新增一行,以呼叫您剛才新增的 CreateOrUpdateDataSource 函式。
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
建置並執行方案。 由於這是您第一次的要求,請查看 Azure 入口網站,以確認已在 Azure AI 搜尋服務中建立資料來源。 在搜尋服務概觀頁面上,確認 [資料來源] 清單有新的項目。 您可能需要等候幾分鐘,讓 Azure 入口網站重新整理頁面。

步驟 2:建立技能集
在此節中,您會定義一組要套用至資料的擴充步驟。 每個擴充步驟均稱為一個「技能」,而一組擴充步驟會稱為一個「技能集」。 本教學課程會使用為技能集內建的技能:
光學字元辨識可辨識影像檔案中的列印和手寫文字。
文字合併,用以將欄位集合中的文字合併成單一「合併內容」欄位。
語言偵測,用以識別內容的語言。
實體辨識,用以從 Blob 容器中的內容擷取組織名稱。
文字分割,用以在呼叫關鍵片語擷取技能和實體辨識技能之前,將大型內容分成較小的區塊。 關鍵片語擷取和實體辨識接受 50,000 個字元 (含) 以下的輸入。 有些範例檔案需要進行分割,以符合這項限制。
關鍵片語擷取,用以提取最高排名的關鍵片語。
在初始處理階段,Azure AI 搜尋服務會解析每份文件,以從不同檔案格式中擷取內容。 來源檔案中的文字會放入產生的 content 欄位內,每份文件一個欄位。 如前所述,將輸入設定為 "/document/content" 以使用此文字。 影像內容會放入產生的 normalized_images 欄位中,在技能集中指定為 /document/normalized_images/*。
輸出可以對應至索引、作為下游技能的輸入,或在使用語言代碼時同時作為對應和輸入。 在索引中,語言代碼可用於篩選。 作為輸入時,文字分析技能會使用語言代碼指出斷字方面的語言規則。
如需技能集基本概念的詳細資訊,請參閱如何定義技能集。
OCR 技術
OcrSkill 可從影像中擷取文字。 此技能假設 normalized_images 欄位存在。 為產生此欄位,我們會在此教學課程稍後,於索引子定義中將 "imageAction" 設定設為 "generateNormalizedImages"。
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
合併技能
在本節中,您會建立 MergeSkill,合併文件內容欄位與 OCR 技能所產生的文字。
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
語言偵測技能
LanguageDetectionSkill 會偵測輸入文字的語言,並針對要求所提交的每份文件回報單一語言代碼。 我們使用語言偵測技能的輸出作為文字分割技能輸入的一部分。
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
文字分割技能
下列 SplitSkill 會依頁面分割文字,並將頁面的長度限制為按 String.Length 所測量的 4,000 個字元。 此演算法會嘗試將文字分割成區塊,且區塊大小最多為 maximumPageLength。 在此案例中,演算法會盡量在例句邊界斷句,好讓區塊大小稍微小於 maximumPageLength。
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
實體辨識技能
此 EntityRecognitionSkill 執行個體會設定來辨識類別類型 organization。
EntityRecognitionSkill 也可以辨識類別類型 person 和 location。
請注意,[內容] 欄位會設定為附有星號的 "/document/pages/*",這表示會在 "/document/pages" 下方針對每個頁面呼叫擴充步驟。
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
關鍵片語擷取技能
如同剛建立的 EntityRecognitionSkill 執行個體一樣,KeyPhraseExtractionSkill 會被呼叫以處理文件的每個頁面。
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
建置和建立技能集
使用您建立的技能來建置 SearchIndexerSkillset。
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
將下列數行新增至 Main。
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
步驟 3:建立索引
在本節中,您會藉由指定要在可搜尋索引中包含哪些欄位以及每個欄位的搜尋屬性,來定義索引結構描述。 欄位具有類型,並且可取用決定如何使用欄位 (可搜尋、可排序等等) 的屬性。 索引中的欄位名稱不需要完全符合來源中的欄位名稱。 在後續步驟中,您可以在索引子中新增欄位對應以連接來源-目的地欄位。 針對此步驟,請使用與搜尋應用程式相關的欄位命名慣例來定義索引。
此練習會使用下列欄位和欄位類型:
| 欄位名稱 | 欄位類型 |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
清單<Edm.String> |
organizations |
列出<Edm.String> |
建立 DemoIndex 類別
此索引的欄位會使用模型類別來定義。 每個模型類別的屬性都有其獨特的屬性,這些屬性會決定索引欄位的搜尋相關行為。
我們會將模型類別新增至新的 C# 檔案。 以滑鼠右鍵選取您的專案,然後選取 [新增]>[新增項目]、選取 [類別] 並將檔案命名為 DemoIndex.cs,然後選取 [新增]。
請務必指出您想要使用來自 Azure.Search.Documents.Indexes 和 System.Text.Json.Serialization 命名空間的類型。
將下列模型類別定義新增至 DemoIndex.cs,然後將它包含於建立索引的相同命名空間。
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
既然您已定義模型類別,請返回 Program.cs,您現在可以非常輕鬆地建立索引定義。 此索引的名稱將會是 demoindex。 如果已有索引使用該名稱,會加以刪除。
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
在測試期間,您可能會發現您正嘗試多次建立索引。 基於此緣故,請檢查以查看您即將建立的索引是否已經存在,然後再嘗試建立它。
將下列數行新增至 Main。
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
新增下列 using 陳述式以解析「消除歧義」參考。
using Index = Azure.Search.Documents.Indexes.Models;
若要深入了解索引概念,請參閱建立索引 (REST API)。
步驟 4:建立及執行索引子
至此,您已建立資料來源、技能集和索引。 這三項元件構成了索引子的一部分,可將各項資料一併提取到多階段的單一作業中。 若要在索引子中結合這些項目,您必須定義欄位對應。
fieldMappings 會在技能集之前進行處理,用來將資料來源中的來源欄位對應到索引中的目標欄位。 如果兩端上的欄位名稱和類型都相同,則不需要任何對應。
outputFieldMappings 會在技能集之後進行處理,用來參考文件萃取或擴充後才建立的 sourceFieldNames。 targetFieldName 是索引中的欄位。
除了將輸入連結至輸出,您也可以使用欄位對應來將資料結構壓平合併。 如需詳細資訊,請參閱如何將擴充的欄位對應至可搜尋的索引。
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
將下列數行新增至 Main。
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
預期索引子處理需要一些時間才能完成。 即使資料集很小,分析技能仍需要大量計算。 某些技能 (例如影像分析) 需要長時間執行。
秘訣
建立索引子時會叫用管線。 資料的存取、輸入和輸出的對應或作業順序若有問題,都會在這個階段中出現。
探索建立索引子
程式碼會將 "maxFailedItems" 設定為 -1,這會指示索引引擎在資料匯入期間忽略錯誤。 此設定有其用處,因為示範資料來源中只有少量文件。 若要有較大的資料來源,您應將值設定為大於 0。
另請注意,"dataToExtract" 會設定為 "contentAndMetadata"。 此陳述式會指示索引子自動擷取不同檔案格式的內容,以及每個檔案的相關中繼資料。
在擷取內容時,您可以設定 imageAction,以從在資料來源中找到的影像擷取文字。 設定為 "imageAction" 組態的 "generateNormalizedImages" 可與 OCR 技能和文字合併技能相結合,以指示索引子從影像中擷取文字 (例如,從「停」交通號誌中擷取「停」這個字),並將其內嵌為內容欄位的一部分。 此行為適用於內嵌在文件中的影像 (例如 PDF 內的影像),以及在資料來源中找到的影像 (例如 JPG 檔案)。
監視編製索引
索引子經定義後,將會在您提交要求時自動執行。 根據您所定義的技能,編製索引所需的時間可能會超出您的預期。 若要了解索引子是否仍在執行,請使用 GetStatus 方法。
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo 表示索引子的目前狀態和執行記錄。
某些來源檔案和技能的組合常會出現警告,這並不一定表示有問題。 在本教學課程中,警告是良性的 (例如,沒有來自 JPEG 檔案的文字輸入)。
將下列數行新增至 Main。
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
搜尋
在 Azure AI 搜尋服務教學課程主控台應用程式中,我們通常會在執行傳回結果的查詢之前加上 2 秒的延遲,但是因為擴充需要數分鐘的時間才能完成,所以我們將會關閉主控台應用程式,並改用另一種方法。
最簡單的選項是 Azure 入口網站 中的 [搜尋總管]。 您可以先執行會傳回所有文件的空查詢,或執行更具針對性的搜尋,傳回由數據管道所建立的新欄位的內容。
在 Azure 入口網站的 [搜尋總覽] 頁面中,選取 索引。
在清單中尋找
demoindex。 應該有 14 份文件。 如果文件計數為零,表示索引子仍在執行中,或頁面尚未重新整理。選取
demoindex。 搜尋總管是第一個索引標籤。只要載入第一份文件,您就可以查詢內容。 若要確認內容是否存在,請按一下 [搜尋] 來執行未指定的查詢。 此查詢會傳回所有目前已編製索引的文件,讓您了解索引所包含的內容。
接下來,貼上下列字串以取得更容易管理的結果:
search=*&$select=id, languageCode, organizations
重設並重新執行
在開發的早期實驗階段中,若要設計反覆項目,最實用的方法是從 Azure AI 搜尋服務中刪除物件,並讓您的程式碼重建這些物件。 資源名稱是唯一的。 刪除物件可讓您使用相同的名稱加以重新建立。
本教學課程的範例程式碼會檢查是否有現有的物件,並將其刪除,以便您重新執行程式碼。 您也可以使用 Azure 入口網站 來刪除索引、索引器、數據源和技能集。
重要心得
本教學課程示範了藉由建立下列元件組件來建置擴充索引管線的基本步驟:資料來源、技能集、索引和索引子。
內建技能已被引入,並且技能集的定義以及透過輸入和輸出的技能串聯機制也一同引入。 您還了解到,索引子定義中需要有 outputFieldMappings,以便將增強的值從管線路由到 Azure AI 搜尋服務的可搜尋索引中。
最後,您了解到如何測試結果並重設系統,以進行進一步的反覆運算。 您已了解,對索引進行查詢會傳回由增強的索引管道所生成的輸出。 您也已了解如何檢查索引子狀態,以及在重新執行管線之前應刪除哪些物件。
清除資源
如果您使用自己的訂用帳戶,當專案結束時,建議您移除不再需要的資源。 讓資源繼續執行可能會產生費用。 您可以個別刪除資源,或刪除資源群組以刪除整組資源。
您可以使用左側瀏覽窗格中的 [所有資源] 或 [資源群組] 連結,在 Azure 入口網站 中找到和管理資源。
下一步
現在您已熟悉 AI 擴充管線中的所有物件,接下來我們將進一步了解技能集定義和個別技能。