Service Fabric 健康情況監視簡介
Azure Service Fabric 導入了健康狀態模型,提供豐富、彈性且可延伸的健康狀態評估與報告。 此模型允許幾乎即時地監視叢集狀態以及其中所執行的服務。 您可以輕鬆地取得健康狀態資訊,並在潛在問題引起連鎖反應和造成大規模中斷之前,予以更正。 在一般模型中,服務會根據其本機檢視傳送報告,且該資訊會進行彙總以提供整體叢集層級檢視。
Service Fabric 元件會使用此健康狀態模型來報告其目前狀態。 您可以使用相同機制來報告應用程式的健康狀態。 只要投入時間規劃高品質的健康狀態報告來擷取您的自訂條件,就能更輕鬆地偵測並修正執行中應用程式的問題。
查看此頁面以取得訓練影片,其說明 Service Fabric 健康情況模型和使用方式:
注意
我們會啟動健康狀態子系統來滿足受監視升級的需求。 Service Fabric 提供受監視應用程式和叢集升級,可以確保完整的可用性、永不停機,且幾乎或完全不需要使用者介入。 為了達成這些目的,升級會依照已設定的升級原則來檢查健康情況。 只有在健康情況達到所需的臨界值時,才可繼續進行升級。 否則,升級會自動回復或暫停,讓系統管理員有機會來修正問題。 若要深入了解應用程式升級,請參閱 這篇文章。
健康狀態資料存放區
健康狀態資料存放區會保留叢集中實體的健康狀態相關資訊,以便輕鬆進行擷取和評估。 其會實作為 Service Fabric 保存的具狀態服務,以確保高可用性和延展性。 健康狀態資料存放區是 fabric:/System 應用程式的一部分,在叢集已啟動且正在執行時可供使用。
健康狀態實體和階層
健康狀態實體會在邏輯階層中組合管理,用來擷取不同實體之間的互動和相依性。 健康狀態存放區會依照從 Service Fabric 元件收到的報告,自動建置健康情況實體和階層。
健康狀態實體會鏡像處理 Service Fabric 實體 (例如,健康狀態應用程式實體符合部署於叢集中的應用程式執行個體,而健康狀態節點實體符合 Service Fabric 叢集節點)。健康狀態階層會擷取系統實體的互動,並作為進階健康狀態評估的基礎。 您可以在 Service Fabric 技術概觀中了解重要的 Service Fabric 概念。 如需應用程式的詳細資訊,請參閱 Service Fabric 應用程式模型。
健康狀態實體和階層可讓您有效率地報告、偵錯和監視叢集和應用程式。 健康狀態模型可針對叢集中許多移動的項目提供精確且「細微」 的健康狀態呈現方式。
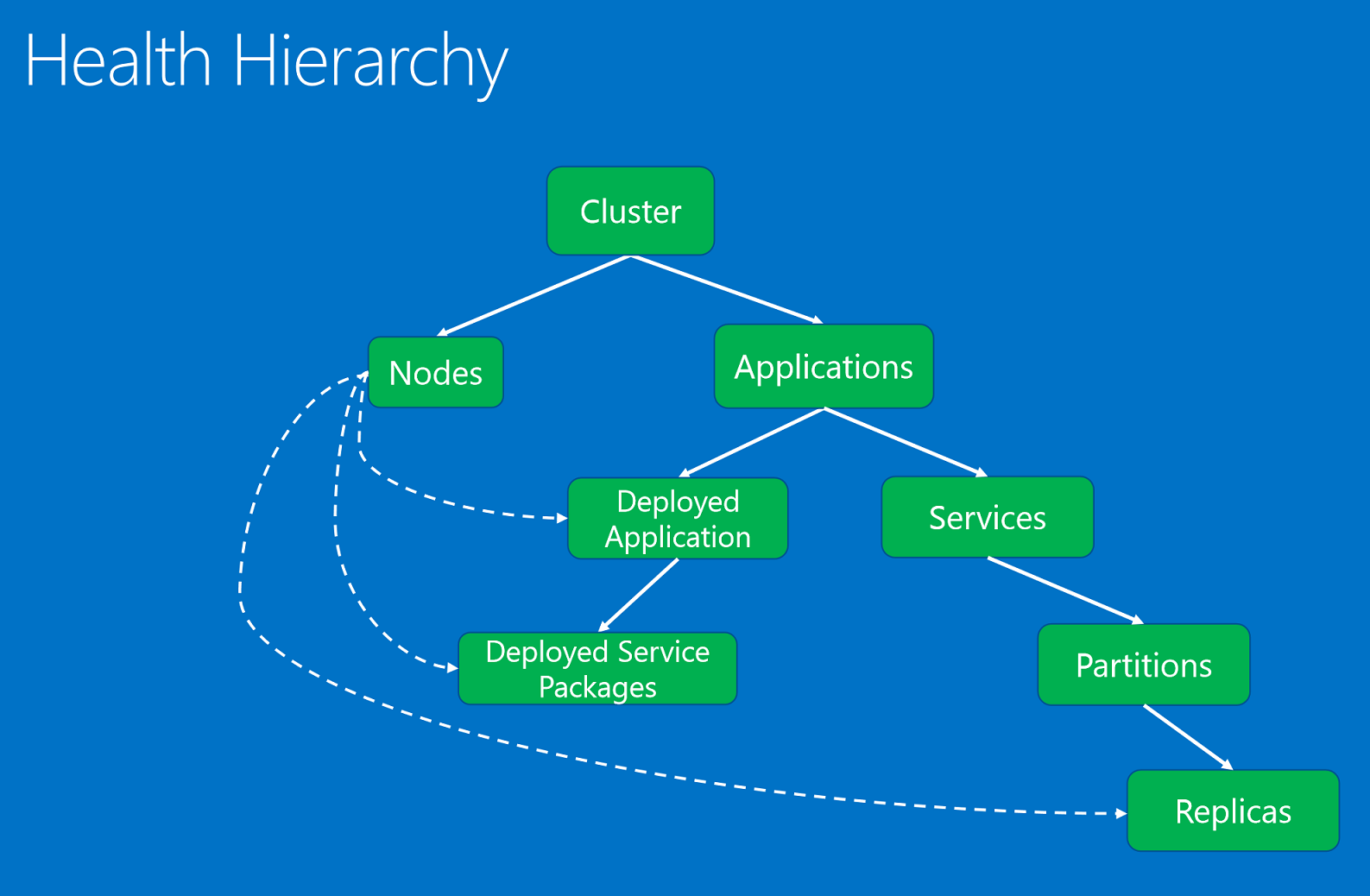 階層中的健康狀態實體將依照父系-子系關聯性組織管理。
階層中的健康狀態實體將依照父系-子系關聯性組織管理。
健康狀態實體包含:
- 叢集。 表示 Service Fabric 叢集的健康狀態。 叢集健康情況報告會說明影響整體叢集的條件。 這些條件會影響叢集中的多個實體或叢集本身。 據此條件,此報告無法將問題縮小到一或多個狀況不良的子系。 範例包括因網路分割或通訊問題而造成叢集核心分裂。
- 節點。 表示 Service Fabric 節點的健康狀態。 節點健康狀態報告會說明影響節點功能的條件。 它們通常會影響在其上執行的所有已部署的實體。 範例包括節點的磁碟空間不足 (或其他電腦全域屬性,例如記憶體、連線) 以及節點已關閉時。 節點實體將透過節點名稱 (字串) 來識別。
- 應用程式。 表示叢集中所執行應用程式執行個體的健康狀態。 應用程式健康狀態報告會說明影響應用程式整體健康狀態的條件。 它們不能將範圍縮小至個別的子系 (服務或已部署的應用程式)。 範例包括應用程式中不同服務之間的端對端互動。 應用程式實體將透過應用程式名稱 (URI) 來識別。
- 服務。 表示叢集中所執行服務的健康狀態。 服務健康情況報告會說明影響服務整體健康狀態的條件。 此報告無法將問題縮小為狀況不良的磁碟分割或複本。 範例包括造成所有分割區發生問題的服務組態 (例如,連接埠或外部檔案共用)。 服務實體將透過服務名稱 (URI) 來識別。
- 資料分割。 表示服務資料分割的健康狀態。 資料分割健康狀態報告會說明影響整體複本集的條件。 範例包括當複本的數目低於目標計數以及當分割區發生仲裁遺失時。 分割區實體將透過分割識別碼 (GUID) 來識別。
- 複本。 表示具狀態服務複本或無狀態服務執行個體的健康狀態。 複本是看門狗和系統元件可針對應用程式進行報告的最小單位。 針對具狀態服務,範例包括無法將作業複寫至次要資料庫並使複寫變慢的主要複本。 此外,若無狀態的執行個體在執行時資源不足或發生連線問題,則其會進行報告。 複本實體將透過分割識別碼 (GUID) 以及複本或執行個體識別碼 (完整) 來識別。
- 已部署應用程式。 表示 節點上所執行應用程式的健康狀態。 已部署應用程式健康狀態報告會描述專屬於節點上應用程式的條件,且無法將範圍縮小至部署在相同節點上的服務封裝。 範例包括無法在該節點上下載應用程式套件時,以及在節點上設定應用程式安全性主體時發生問題。 已部署的應用程式將透過應用程式名稱 (URI) 和節點名稱 (字串) 來識別。
- 已部署服務封裝。 表示叢集的節點上所執行的服務封裝的健康狀態。 其會描述專屬於服務封裝的條件,該條件對於相同應用程式之相同節點上的其他服務封裝不會造成影響。 範例包括服務封裝中的程式碼封裝無法啟動,以及無法讀取組態封裝。 已部署的服務套件將透過應用程式名稱 (URI)、節點名稱 (字串) 和服務資訊清單名稱 (字串) 來識別。
健康狀態模型的細微性可讓您輕鬆地偵測並更正問題。 例如,如果服務沒有回應,則可報告應用程式執行個體的狀況不良。 但在該層級上回報並不理想,因為問題可能不會影響該應用程式中的所有服務。 報告應套用至狀況不良的服務上,或者若有更多資訊指向特定的子系分割區,則套用至該分割區上。 資料將自動浮現於階層中,而狀況不良的分割區將顯示於服務和應用程式層級上。 此彙總可協助您更快速找出並解決問題的根本原因。
健康狀態階層是由父系-子系關聯性所組成。 叢集是由節點和應用程式所組成。 應用程式包含服務和已部署的應用程式。 已部署的應用程式包含已部署的服務封裝。 服務包含資料分割,且每個資料分割包含一個或多個複本。 節點和已部署實體之間具有特殊關聯性。 由其授權單位系統元件 (容錯移轉管理員服務) 報告為健康情況不良的節點,會影響已部署的應用程式、服務套件,以及部署於其中的複本。
健康狀態階層會依照最新健康狀態報告來表示系統的最新狀態,且幾乎是即時資訊。 內部和外部看門狗可以依照應用程式特定邏輯或自訂監視的條件來報告相同實體。 使用者報告會與系統報告同時存在。
在設計大型雲端服務期間,投入時間規劃如何報告和回應健康情況。 此預先投入可讓您更輕鬆地偵錯、監視和操作該服務。
健康狀態
Service Fabric 會使用三種健康狀態來描述實體的健康狀態是否良好:「OK」、「Warning」和「Error」。 傳送至健康狀態資料存放區的任何報告都必須指定這其中一個狀態。 健康狀態評估結果即為這些狀態的其中之一。
可能的 健康狀態 為:
- OK。 實體的健康狀態良好。 報告實體本身或其子系 (適用時) 沒有已知問題。
- Warning。 實體發生一些問題,但仍可正常運作。 例如,發生延遲,但尚未造成任何功能上的問題。 在某些情況下,不需外部介入,警告狀況即可本身進行修正。 在這些情況下,健康情況報告會引起關注,並提供後續狀況的可見性。 在其他情況中,「Warning」狀況可能會惡化為嚴重問題,但不需使用者介入。
- Error。 實體的狀況不良。 因為實體無法正常運作,故應採取動作來修正實體的狀態。
- 未知。 實體不存在於健康狀態資料存放區中。 此結果可以從合併來自多個元件之結果的分散式查詢中取得。 例如,取得節點清單查詢會傳送至 FailoverManager、ClusterManager 和 HealthManager,而取得應用程式清單查詢會傳送至 ClusterManager 和 HealthManager。 這些查詢會合併來自多個系統元件的結果。 若其他系統元件傳回的實體不存在於健康情況存放區,則合併的查詢會處於未知的健康情況。 因為尚未處理健康情況報告或實體已在刪除後清除,所以實體不在存放區中。
健康狀態原則
健康狀態資料存放區會套用健康狀態原則,依照它的報告及其子系來判斷實體的健康狀態是否良好。
注意
健康狀態原則可在叢集資訊清單 (適用於叢集和節點健康狀態評估) 或應用程式資訊清單 (適用於應用程式評估及其任何子系) 中指定。 健康情況評估要求也可傳入僅用於該評估的自訂健康情況評估原則。
根據預設,Service Fabric 適用於父系-子系階層式關聯性的嚴格規則 (所有項目都必須是狀況良好的) 。 如果有一個子系具有一個狀況不良的事件,就會將父系視為狀況不良。
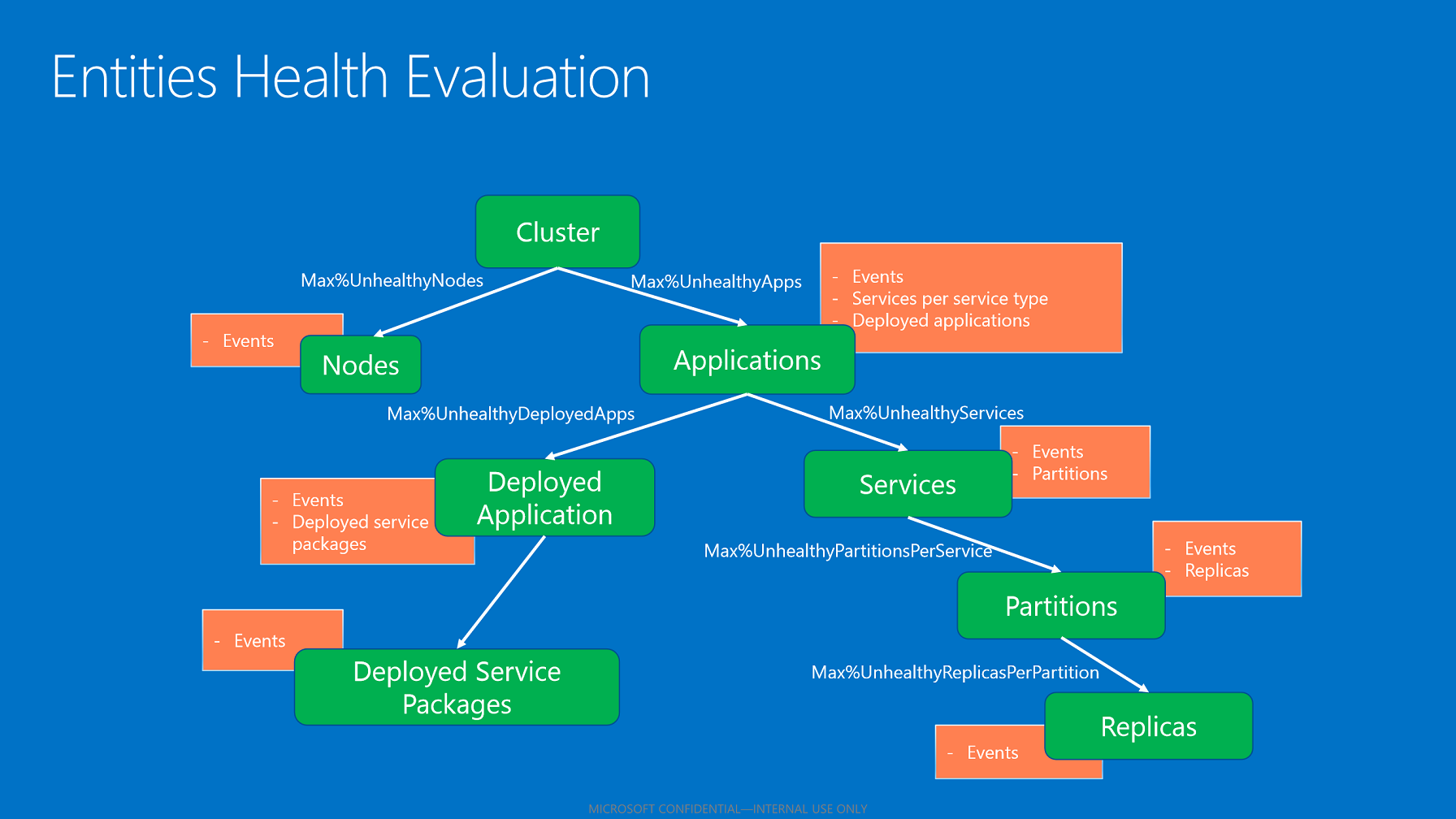
叢集健康狀態原則
叢集健康狀態原則 是用來評估叢集健康狀態和節點健康狀態。 原則可以定義於叢集資訊清單中。 如果原則不存在,則會使用預設原則 (不容許失敗)。
叢集健康狀態原則包含:
ConsiderWarningAsError。 指定是否要在健康狀態評估期間將「Warning」健康狀態報告視為錯誤。 預設:false。
MaxPercentUnhealthyApplications。 指定在系統將叢集視為「Error」之前,對狀況不良之應用程式的最大容許百分比。
MaxPercentUnhealthyNodes。 指定在系統將叢集視為「Error」之前,對狀況不良之節點的最大容許百分比。 在大型叢集中,永遠都有一些節點會關閉或需要修復,因此應設定此百分比來容許這種情形。
ApplicationTypeHealthPolicyMap。 應用程式類型的健康狀態原則對應可以在叢集健康狀態評估期間,用來描述特殊的應用程式類型。 根據預設,所有的應用程式都會放入集區,並使用 MaxPercentUnhealthyApplications 加以評估。 如果某些應用程式類型應該以不同方式處理,則可以從全域集區中取出它們。 反之,則會根據對應中的應用程式類型名稱相關聯的百分比來評估它們。 例如,在叢集中,有數千個不同類型的應用程式,以及某個特殊應用程式類型的數個控制應用程式執行個體。 控制應用程式應該絕對不會發生錯誤。 您可以將全域的 MaxPercentUnhealthyApplications 指定為 20%,以容許一些失敗,但如果應用程式類型為 "ControlApplicationType",請將 MaxPercentUnhealthyApplications 設為 0。 如此一來,如果這許多應用程式中有一些的狀況不良,但低於全域狀況不良的百分比,則會將叢集評估為 Warning。 Warning 健康狀態並不會影響叢集升級或由 Error 健康狀態觸發的其他監視。 但是,即使只有一個控制應用程式錯誤,也會造成叢集狀況不良,視升級組態而定,這將會觸發回復或暫停叢集升級。 對於對應中定義的應用程式類型,所有的應用程式執行個體都是從應用程式的全域集區中所取出。 系統會使用對應的特定 MaxPercentUnhealthyApplications,根據應用程式類型的應用程式總數來評估它們。 所有其他的應用程式都會保留於全域集區中,並使用 MaxPercentUnhealthyApplications 加以評估。
下列範例是來自叢集資訊清單的摘要。 若要定義應用程式類型對應中的項目,請在參數名稱前面加上 "ApplicationTypeMaxPercentUnhealthyApplications-",後面接著應用程式類型名稱。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. 節點類型的健康狀態原則對應,可用於在叢集健康狀態評估期間描述特殊的節點類型。 系統會根據對應中節點類型名稱相關聯的百分比來評估節點類型。 設定這個值不會影響用於MaxPercentUnhealthyNodes節點的全域集區。 例如,叢集具有數百個不同類型的節點,以及一些裝載重要工作的節點類型。 該類型中沒有任何節點應關閉。 您可以指定全域MaxPercentUnhealthyNodes到 20% 以容忍所有節點中發生一些失敗,但針對節點類型SpecialNodeType,將MaxPercentUnhealthyNodes設定為 0。 如此一來,如果這許多應用程式中有一些狀況不良,但低於全域狀況不良的百分比,則會將叢集健康狀態評估為 Warning。 Warning 健康狀態並不會影響叢集升級,或由 Error 健康狀態觸發的其他監視。 但是,即使只有一個處於錯誤健康狀態的類型SpecialNodeType節點,也會使叢集狀況不良,並觸發復原或暫停叢集升級 (視升級設定而定)。 相反地,若將全域MaxPercentUnhealthyNodes設定為 0,並將SpecialNodeType最大百分比狀況不良節點設定為 100,且包含一個處於錯誤健康狀態的類型SpecialNodeType節點,則會讓叢集處於錯誤狀態,因為在此情況下,全域限制較嚴格。下列範例是來自叢集資訊清單的摘要。 若要定義節點類型對應中的專案,請在參數名稱前面加上 "NodeTypeMaxPercentUnhealthyNodes-",後面接著節點類型名稱。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
應用程式健康狀態原則
應用程式健康狀態原則 會針對應用程式及其子系,說明完成事件和子系狀態彙總評估的方式。 在應用程式封裝中,它可以定義於應用程式資訊清單 (即 ApplicationManifest.xml) 中。 若未指定任何原則,則當健康狀態報告或子系處於「Warning」或「Error」健康狀態時,Service Fabric 會假設實體狀況不良。 可設定的原則包含:
- ConsiderWarningAsError。 指定是否要在健康狀態評估期間將「Warning」健康狀態報告視為錯誤。 預設:false。
- MaxPercentUnhealthyDeployedApplications。 指定在系統將應用程式視為「Error」之前,對狀況不良之已部署應用程式的最大容許百分比。 此百分比的計算方式是將狀況不良的已部署應用程式數目,除以叢集中目前部署應用程式的節點數目。 針對較少的節點數目,計算會四捨五入以容許一個失敗。 預設百分比:零。
- DefaultServiceTypeHealthPolicy。 指定預設服務類型健康狀態原則,這會取代應用程式中所有服務類型的預設健康狀態原則。
- ServiceTypeHealthPolicyMap。 針對每個服務類型提供服務健康狀態原則的對應。 這些原則會取代每個指定服務類型的預設服務類型健康狀態原則。 例如,如果應用程式具有無狀態閘道服務類型和具狀態引擎服務類型,您可以設定不同的健康狀態原則來評估它們。 當您針對每個服務類型指定原則時,可以對服務的健康狀態取得更細微的控制。
服務類型健康狀態原則
服務類型健康狀態原則 會指定評估和彙總服務及服務子系的方式。 原則包含:
- MaxPercentUnhealthyPartitionsPerService。 指定在系統將服務視為狀況不良之前,狀況不良之分割區的最大容許百分比。 預設百分比:零。
- MaxPercentUnhealthyReplicasPerPartition。 指定在系統將分割區視為狀況不良之前,狀況不良之複本的最大容許百分比。 預設百分比:零。
- MaxPercentUnhealthyServices。 指定在系統將應用程式視為狀況不良之前,狀況不良之服務的最大容許百分比。 預設百分比:零。
下列範例是來自應用程式資訊清單的摘要:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
健康狀態評估
使用者和自動化服務可以隨時評估任何實體的健康狀態。 為了評估實體的健康狀態,健康狀態資料存放區會彙總實體的所有健康狀態報告,並評估其所有子系 (適用時)。 健康狀態彙總演算法會使用健康狀態原則,來指定如何評估健康狀態報告,以及如何彙總子系健康狀態 (適用時)。
健康狀態報告彙總
一個實體可以具有由不同回報者針對不同屬性 (系統元件或看門狗) 所傳送的多個健康狀態報告。 彙總會使用相關聯的健康狀態原則,特別是應用程式的 ConsiderWarningAsError 成員或叢集健康狀態原則。 ConsiderWarningAsError 指定如何評估警告。
已彙總健康狀態是由實體上的 最差 健康狀態報告所觸發。 若至少有一個「Error」健康狀態報告存在,則已彙總的健康狀態會顯示為錯誤。
有一或多個錯誤健康狀態報告的健康狀態實體會評估為「錯誤」。 已過期的健康狀態報告,不論其健康狀態如何,結果也是如此。
如果沒有任何「Error」報告以及一或多個「Warning」,則根據 ConsiderWarningAsError 原則旗標而定,已彙總的健康狀態可能會是「Warning」或「Error」。
健康狀態報告彙總包含「Warning」報告以及設為 false (預設值) 的 ConsiderWarningAsError。
子系健康狀態彙總
實體的已彙總健康狀態會反映子系健康狀態 (適用時)。 彙總子系健康狀態的演算法會依照實體類型使用適用的健康狀態原則。
以健康狀態原則為基礎的子系彙總。
當健康狀態資料存放區已評估過所有子系之後,即會根據狀況不良子系已設定的最大百分比來彙總其健康狀態。 此百分比是根據實體和子類型而取自於原則。
- 若所有子系都具有「OK」狀態,則子系已彙總的健康狀態為「OK」。
- 若子系同時具有「OK」和「Warning」狀態,則子系已彙總的健康狀態會是「Warning」。
- 若具有「Error」狀態的子系不符合狀況不良子系的最大允許百分比,則已彙總的父系健康狀態為「Error」。
- 若具有「Error」狀態的子系符合狀況不良子系的最大允許百分比,則已彙總的父系健康狀態為「Warning」。
健康狀態報告
系統元件、System Fabric 應用程式和內部/外部看門狗可以報告 Service Fabric 實體。 報告程式會依照其所監視的條件,來決定「本機」 受監視實體的健康狀態。 回報者不需查看任何全域狀態或彙總資料。 最好是使用簡單的報告程式,因為太複雜的有機體需要查看許多項目,才能推斷所要傳送的資訊。
若要將健康狀態資料傳送至健康狀態資料存放區,報告程式需要識別受影響的實體,並建立健康狀態報告。 若要傳送報告,請使用 FabricClient.HealthClient.ReportHealth API、Partition 或 CodePackageActivationContext 物件上公開的報告健康情況 API、PowerShell cmdlet 或 REST。
健康狀態報告
叢集中每個實體的 健康狀態報告 包含下列資訊:
SourceId。 用來識別健康狀態事件回報者的唯一字串。
實體識別碼。 識別報告所套用的實體。 其會依照 實體類型而有所不同:
- 叢集。 無。
- 節點。 節點名稱 (字串)。
- 應用程式。 應用程式名稱 (URI)。 表示叢集中已部署應用程式執行個體的名稱。
- 服務。 服務名稱 (URI)。 表示叢集中已部署服務執行個體的名稱。
- 分割區。 分割識別碼 (GUID)。 表示資料分割的唯一識別碼。
- 複本。 具狀態服務複本識別碼,或無狀態服務執行個體識別碼 (INT64)。
- DeployedApplication。 應用程式名稱 (URI) 和節點名稱 (字串)。
- DeployedServicePackage。 應用程式名稱 (URI)、節點名稱 (字串) 和服務資訊清單名稱 (字串)。
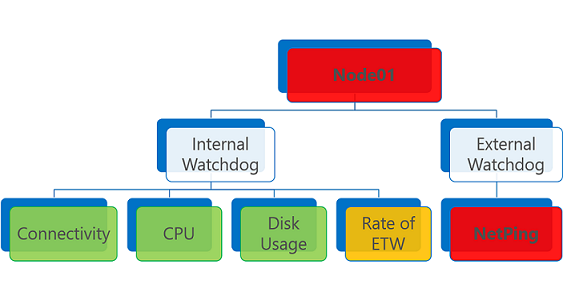
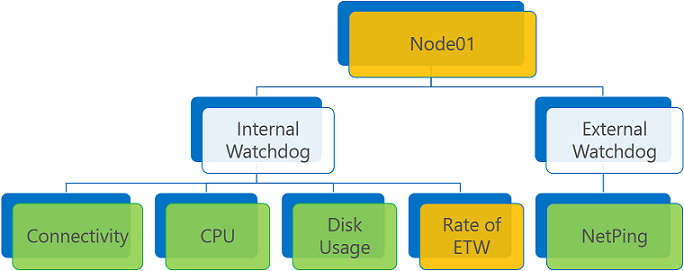
屬性。 可讓回報者針對實體的特定屬性來分類健康狀態事件的 字串 (非固定列舉)。 例如,報告程式 A 可以針對 Node01 的「儲存體」屬性報告健康情況,而報告程式 B 可以針對 Node01 的「連線」屬性報告健康情況。 在健康狀態資料存放區中,這兩個報告會將 Node01 實體視為個別的健康狀態事件。
描述。 可讓報告程式提供健康狀態事件相關詳細資訊的字串。 SourceId、Property 和 HealthState 應在報告中完整說明。 說明可增加人們可讀取的報告相關資訊。 文字可讓系統管理員和使用者更容易了解健全狀況報告。
HealthState。 描述報告健康狀態的 列舉 。 接受的值是「OK」、「Warning」和「Error」。
TimeToLive。 指出健康狀態報告持續有效的時間範圍。 可以搭配 RemoveWhenExpired,讓健康狀態資料存放區知道如何評估過期的事件。 根據預設,該值為「Infinite」,代表報告將永遠有效。
RemoveWhenExpired。 布林值。 若設為 True,則過期的健康狀態報告會自動從健康狀態資料存放區移除,且報告不會影響實體健康狀態評估。 只有當報告在一段指定時間內有效時才會使用此值,且報告程式不需明確地將其清除。它也會用來從健康狀態資料存放區刪除報告 (例如,變更看門狗,並停止傳送含有先前來源和屬性的報告)。 其傳送的報告可以使用短暫的 TimeToLive 和 RemoveWhenExpired,以便從健康狀態資料存放區清除任何先前的狀態。 若將此值設為 False,則會將過期的報告視為健康狀態評估的錯誤。 False 值示意健康狀態資料存放區,來源應定期報告此屬性。 如果沒有,則一定是看門狗發生了某些錯誤。 看門狗的健康狀態是藉由將事件視為錯誤來擷取。
SequenceNumber。 這個值是必須持續增加的正整數,其表示報告的順序。 健康狀態資料存放區會使用其來偵測因網路延遲或其他問題而較晚收到的陳舊報告。 針對相同的實體、來源和屬性,若序號小於或等於最新套用的數字,則報告會遭到拒絕。 如果未指定,即會自動產生序號。 只有在報告狀態轉換時,才需放入序號。 在此情況下,來源必須記住它所傳送的報告,並保留在容錯移轉復原的資訊。
每個健康狀態報告都需要四種資訊 (SourceId、實體識別碼、Property 和 HealthState)。 不允許 SourceId 字串以前置詞 "System." 開頭,因為這是保留給系統報告。 針對相同的實體,相同的來源和屬性僅能有一個報告。 無論在健康狀態用戶端 (若是批次處理) 或健康狀態資料存放區端,相同來源和屬性的多個報告會互相覆寫。 取代是以序號為根據;較新的報告 (具有較大的序號) 會取代較舊的報告。
健康狀態事件
就內部而言,健康狀態資料存放區會保留 健康狀態事件,其中包含報告的所有資訊以及其他中繼資料。 中繼資料包括報告送至健康狀態用戶端的時間,以及在伺服器端修改該報告的時間。 健康狀態事件將透過 健康狀態查詢來傳回。
新增的中繼資料包含:
- SourceUtcTimestamp。 報告送至健康狀態用戶端的時間 (國際標準時間)
- LastModifiedUtcTimestamp。 報告上一次在伺服器端修改的時間 (國際標準時間)
- IsExpired。 指出報告於健康狀態資料存放區執行查詢時是否已到期的旗標。 只有當 RemoveWhenExpired 為 False,事件才會過期。 否則,事件不會由查詢傳回,並從存放區中移除。
- LastOkTransitionAt、LastWarningTransitionAt、LastErrorTransitionAt。 上一次轉換 OK/Warning/Error 的時間。 這些欄位會針對事件的健康狀態轉換提供歷程記錄。
狀態轉換欄位可用於更聰明的警示或「歷程記錄」的健康狀態事件資訊。 所適用的案例如下:
- 當屬性處於「Warning/Error」狀態持續超過 X 分鐘時發出警示。 檢查一段時間的狀況,可避免暫時狀況所造成的警示。 例如,當健康狀態處於「Warning」狀態持續超過五分鐘時發出警示,可以轉譯為 (HealthState == Warning 且 Now - LastWarningTransitionTime > 5 分鐘)。
- 僅在前 X 分鐘內發生變更的情況時發出警示。 如果報告在指定的時間之前即處於「Error」狀態,則可忽略 (因為其先前已發出訊號)。
- 若屬性交叉出現警告和錯誤,請判斷狀況不良 (亦即不是 OK) 已持續多久。 例如,若屬性狀況良好的狀態不超過 5 分鐘時發出警示,可以轉譯為 (HealthState != Ok 且 Now - LastOkTransitionTime > 5 分鐘)。
範例:報告和評估應用程式健康狀態
下列範例會從來源 MyWatchdog,透過應用程式 fabric:/WordCount 上的 PowerShell 來傳送健康狀態報告。 健康狀態報告會在 Error 健康狀態中包含健康狀態屬性「可用性」的相關資訊,並包含「Infinite」的 TimeToLive。 然後它會查詢應用程式健康狀態,並在健康狀態事件清單中傳回已彙總的健康狀態錯誤和已報告的健康狀態事件。
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
健康狀態模型使用方式
健康狀態模型可讓雲端服務和基礎 Service Fabric 平台進行調整,因為監視及健康狀態決定會分散至叢集內的不同監視器。 其他系統在叢集層級具有單一的集中式服務,可剖析服務所發出的所有「可能」 的實用資訊。 這個方法會防礙其延展性。 同時也不允許其收集特定資訊來協助識別問題和潛在問題,並盡可能接近根本原因。
健康狀態模型常用來監視和診斷,以便評估叢集和應用程式健康狀態,以及監視升級。 其他服務會使用健康狀態資料來執行自動修復、建置叢集健康狀態歷程記錄,以及發出特定情況的警示。