Azure Synapse Analytics 中的專用 SQL 集區 (先前稱為 SQL DW) 架構
Azure Synapse Analytics 是一項分析服務,可將企業數據倉儲和巨量數據分析整合在一起。 它可讓您自由地根據字詞查詢數據。
注意
如需 Azure Synapse Analytics 的詳細資訊,請觀看此影片,說明數據移動增強功能。
Synapse SQL 架構元件
專用 SQL 集區(先前稱為 SQL DW) 利用向外延展架構,將數據處理分散到多個節點。 縮放單位是計算能力的抽象概念,稱為 數據倉儲單位。 計算會與儲存體分開,讓您可以單獨調整系統中資料的計算。
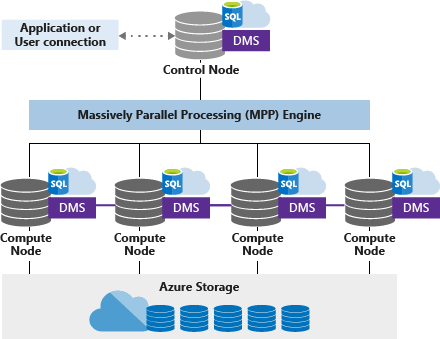
專用 SQL 集區 (先前稱為 SQL DW) 會使用以節點為基礎的架構。 應用程式會將 T-SQL 命令連線並發出至控制節點。 控制節點會裝載分散式查詢引擎,以優化查詢以進行平行處理,然後將作業傳遞至計算節點,以平行方式執行其工作。
計算節點會在 Azure 儲存體中儲存所有使用者資料,並執行平行查詢。 資料移動服務 (DMS) 是系統層級的內部服務,其會視需要在節點之間移動資料,以平行方式執行查詢並傳回精確的結果。
使用分離的記憶體和計算,使用專用 SQL 集區時,可以:
- 不論您的記憶體需求為何,獨立調整計算能力的大小。
- 在專用 SQL 集區中成長或縮小計算能力(先前稱為 SQL DW),而不需要行動數據。
- 暫停計算容量,同時讓資料保持不變,因此您只需支付儲存體的費用。
- 在營運時間期間繼續計算容量。
Azure 儲存體
專用 SQL 集區 SQL(先前稱為 SQL DW)利用 Azure 儲存體 來保護您的用戶數據安全。 由於您的數據會由 Azure 儲存體 儲存和管理,因此記憶體耗用量會有個別的費用。 數據會分區化成 散發, 以將系統的效能優化。 您可以選擇在定義資料表時用來散發數據的分區化模式。 支援這些分區化模式:
- 雜湊
- 循環配置資源
- 複寫
控制節點
控制節點是架構的大腦。 它是與所有應用程式與連線互動的前端。 分散式查詢引擎會在控制節點上執行,以優化及協調平行查詢。 當您提交 T-SQL 查詢時,控制節點會將它轉換成以平行方式針對每個散發執行的查詢。
計算節點
計算節點可提供計算能力。 散發會對應至計算節點進行處理。 當您支付更多計算資源的費用時,散發套件會重新對應至可用的計算節點。 計算節點的數目從 1 到 60 不等,並由 Synapse SQL 的服務等級決定。
每個計算節點都有系統檢視中可見的節點標識碼。 您可以在名稱開頭為sys.pdw_nodes的系統檢視中尋找node_id數據行,以查看計算節點識別碼。 如需這些系統檢視的清單,請參閱 Synapse SQL 系統檢視。
資料移動服務
數據行動服務 (DMS) 是協調計算節點之間數據行動的數據傳輸技術。 某些查詢需要數據移動,以確保平行查詢傳回精確的結果。 需要數據移動時,DMS 可確保正確的數據到達正確的位置。
分佈
散發是儲存體的基本單位,也是處理在分散式資料上所執行平行查詢時的基本單位。 當 Synapse SQL 執行查詢時,工作會分成 60 個平行執行的較小查詢。
每個 60 個較小的查詢都會在其中一個數據散發上執行。 每個計算節點都會管理一或多個 60 個散發套件。 計算資源上限的專用 SQL 集區(先前稱為 SQL DW),每個計算節點都有一個散發。 具有最低計算資源的專用 SQL 集區(先前稱為 SQL DW)具有一個計算節點上的所有散發。
注意
如需根據工作負載使用的最佳數據表散發策略建議,請參閱 Azure Synapse SQL 散發建議程式。
雜湊分散式資料表
雜湊分散式資料表可以針對大型資料表上的聯結和彙總提供最高查詢效能。
若要將數據分區化為哈希分散式數據表,哈希函式可用來確定性地將每個數據列指派給一個散發。 在資料表定義中,其中一個資料行會指定為散發資料行。 雜湊函式會使用散發資料行中的值,將每個資料列指派給一個散發。
下圖說明完整(非分散式數據表)如何儲存為哈希分散式數據表。

- 每個數據列都屬於一個散發。
- 決定性哈希演算法會將每個數據列指派給一個散發。
- 每個散發的數據表數據列數目會隨著數據表大小的不同而有所不同。
選取散發資料行具有效能考量,例如相異性、資料扭曲,以及在系統上執行的查詢類型。
循環配置資源分散式資料表
迴圈配置資源數據表是建立及提供快速效能的最簡單數據表,當做載入的臨時表使用時。
循環配置資源分散式資料表會在整個資料表中平均散發資料,但不需任何進一步最佳化。 會先隨機選擇一個散發,然後將資料列的緩衝區循序指派給散發。 將資料快速載入循環配置資源資料表,但搭配雜湊分散式資料表通常會有較佳的查詢效能。 迴圈配置資源數據表上的聯結需要重新洗牌數據,這需要額外的時間。
複寫的資料表
複寫資料表可為小型資料表提供最快速的查詢效能。
複寫的資料表會在每個計算節點上快取一份完整的資料表複本。 因此,複寫資料表就不需在進行聯結或彙總之前,於計算節點之間傳輸資料。 複寫的資料表最適合與小型資料表搭配使用。 需要額外的記憶體,而且寫入數據時會產生額外的額外負荷,使得大型數據表不切實際。
下圖顯示在每個計算節點上第一個散發上快取的復寫數據表。

下一步
既然您已瞭解 Azure Synapse,請瞭解如何快速 建立專用 SQL 集區(先前稱為 SQL DW), 並 載入範例數據。 如果您不熟悉 Azure,當您遇到新術語時,可能會發現 Azure 詞彙 很有説明。 或查看其中一些其他 Azure Synapse 資源。