Azure Data Lake Storage 移轉指導方針和模式
您可以將資料、工作負載和應用程式從 Azure Data Lake Storage Gen1 移轉至 Azure Data Lake Storage Gen2。 本文說明建議的移轉方法,並涵蓋不同的移轉模式和使用時機。 為了方便閱讀,此文章使用 Gen1 一詞來指稱 Azure Data Lake Storage Gen1,並使用 Gen2 一詞來指稱 Azure Data Lake Storage Gen2。
注意
Azure Data Lake Storage Gen1 現已淘汰。 請參閱這裡的淘汰公告。Data Lake Storage Gen1 資源無法再存取。
Azure Data Lake Storage Gen2 建置於 Azure Blob 儲存體上,並提供一組專門用於巨量資料分析的功能。 Data Lake Storage Gen2 結合了 Azure Data Lake Storage Gen1 中的功能 (例如檔案系統語意、目錄及檔案層級安全性和調整),與 Azure Blob 儲存體的低成本、分層式儲存體、高可用性/災害復原功能。
注意
由於 Gen1 和 Gen2 是不同的服務,因此未提供就地升級體驗。 若要使用 Azure 入口網站 簡化移轉至 Gen2 的作業,請參閱使用 Azure 入口網站將 Azure Data Lake Storage 從 Gen1 移轉至 Gen2。
建議的方法
若要從 Gen1 移轉至 Gen2,建議您採用下列方法。
步驟 1:評估整備程度
步驟 2:準備遷移
步驟 3:移轉資料和應用程式工作負載
步驟 4:從 Gen1 完全移轉至 Gen2
步驟 1:評估整備程度
瞭解 Data Lake Storage Gen2 供應項目,及其優點、成本和一般架構。
檢閱已知問題清單,以評估任何功能差距。
Gen2 支援 Blob 儲存體功能,例如診斷記錄、存取層和 Blob 儲存體生命週期管理原則。 如果您想要使用其中任何功能,請參閱目前的支援層級。
檢閱 Azure 生態系統支援目前的狀態,以確定 Gen2 支援您解決方案所依存的任何服務。
步驟 2:準備遷移
識別您要遷移的資料集。
請利用這個機會清除您不再使用的資料集。 除非您打算一次遷移所有資料,否則請在此時找出可在階段中遷移的邏輯資料群組。
在您的 Gen1 帳戶上執行過時分析 (或類似分析),以識別哪些檔案或資料夾長時間保留於詳細目錄中,或可能已過時。
判斷移轉對您的業務有何影響。
例如,請考量您在移轉執行期間是否可承受任何停機。 這些考量可協助您找出適合的移轉模式,以及選擇最適當的工具。
建立移轉計畫。
我們建議採用這些移轉模式。 您可以選擇其中一個模式、將其合併在一起,或自行設計您的自訂模式。
步驟 3:遷移資料、工作負載和應用程式
使用您偏好的模式來遷移資料、工作負載和應用程式。 建議您以累加方式驗證案例。
建立儲存體帳戶,並啟用階層命名空間功能。
遷移您的資料。
將工作負載中的服務設定為指向您的 Gen2 端點。
針對 HDInsight 叢集,您可以將儲存體帳戶組態設定新增至 %HADOOP_HOME%/conf/core-site.xml 檔案。 如果您打算將外部 Hive 資料表從 Gen1 移轉至 Gen2,則也請務必將儲存體帳戶設定新增至 %HIVE_CONF_DIR%/hive-site.xml 檔案。
您可以使用 Apache Ambari 來修改每個檔案的設定。 若要尋找儲存體帳戶設定,請參閱 Hadoop Azure 支援:ABFS - Azure Data Lake Storage Gen2。 此範例使用
fs.azure.account.key設定來啟用共用金鑰授權:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>如需可協助您設定 HDInsight、Azure Databricks 及其他 Azure 服務來使用 Gen2 的文章連結,請參閱支援 Azure Data Lake Storage Gen2 的 Azure 服務。
更新應用程式以使用 Gen2 API。 請參閱下列指南:
更新指令碼,以使用 Data Lake Storage Gen2 PowerShell Cmdlet 和 Azure CLI 命令。
在程式碼檔案中,或在 Databricks 筆記本、Apache Hive HQL 檔案或用來作為工作負載一部分的任何其他檔案中,搜尋包含
adl://字串的 URI 參考。 以新儲存體帳戶的 Gen2 格式化 URI 取代這些參考。 例如:Gen1 URI:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfile可能會變成abfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile。在您的帳戶上設定安全性,以納入 Azure 角色、檔案和資料夾層級安全性,以及 Azure 儲存體防火牆和虛擬網路。
步驟 4:從 Gen1 完全移轉至 Gen2
在您確信應用程式和工作負載可在 Gen2 上穩定執行後,您就可以開始使用 Gen2 以因應商業需求。 關閉在 Gen1 上執行的任何其餘管線,並解除委任您的 Gen1 帳戶。
Gen1 與 Gen2 的功能比較
下表比較 Gen1 與 Gen2 的功能。
| 區域 | Gen1 | Gen2 |
|---|---|---|
| 資料組織 | 階層式命名空間 檔案和資料夾支援 |
階層式命名空間 容器、檔案和資料夾支援 |
| 異地備援 | LRS | LRS、ZRS、GRS、RA-GRS |
| 驗證 | Microsoft Entra 受控識別 服務主體 |
Microsoft Entra 受控識別 服務主體 共用存取金鑰 |
| 授權 | 管理 - Azure RBAC 資料 - ACL |
管理 - Azure RBAC 資料 - ACL、Azure RBAC |
| 加密 - 待用資料 | 伺服器端 - 使用 Microsoft 管理的金鑰或客戶自控金鑰 | 伺服器端 - 使用 Microsoft 管理的金鑰或客戶自控金鑰 |
| VNET 支援 | VNET 整合 | 服務端點、私人端點 |
| 開發人員體驗 | REST、.NET、Java、Python、PowerShell、Azure CLI | 正式推出 - REST、.NET、Java、Python 公開預覽 - JavaScript、PowerShell、Azure CLI |
| 資源記錄 | 傳統記錄 已整合 Azure 監視器 |
傳統記錄 - 正式推出 已整合 Azure 監視器 - 預覽 |
| 生態系統 | HDInsight (3.6)、Azure Databricks (3.1 和更新版本)、Azure Synapse Analytics、ADF | HDInsight (3.6、4.0)、Azure Databricks (5.1 和更新版本)、Azure Synapse Analytics、ADF |
Gen1 至 Gen2 模式
選擇移轉模式,然後視需要修改該模式。
| 移轉模式 | 詳細資料 |
|---|---|
| 隨即轉移 | 最簡單的模式。 如果您的資料管線可承受停機則適用。 |
| 增量備份 | 類似於隨即轉移,但停機時間較短。 適用於需要較長時間才能複製的大量資料。 |
| 雙重管線 | 適用於無法承受任何停機的管線。 |
| 雙向同步 | 類似於雙重管線,但使用更具階段性的方法,適用於更複雜的管線。 |
我們來仔細看看每個模式。
隨即轉移模式
這是最簡單的模式。
停止所有對 Gen1 的寫入。
將資料從 Gen1 移至 Gen2。 建議使用 Azure Data Factory,或使用 Azure 入口網站。 ACL 會與資料一起複製。
將擷取作業和工作負載指向 Gen2。
解除委任 Gen1。
請在我們的隨即轉移移轉範例中,查看隨即轉移模式的範例程式碼。
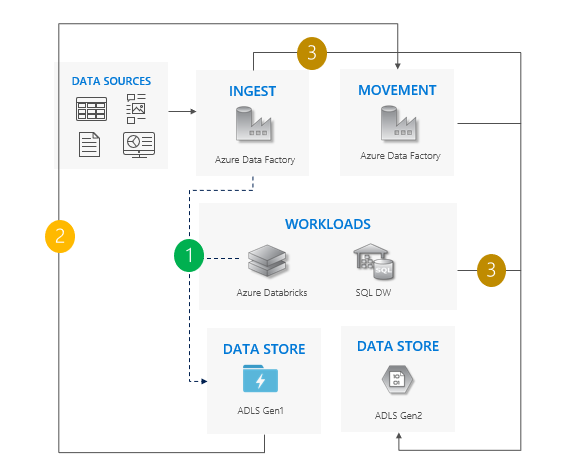
使用隨即轉移模式的考量
同時將所有工作負載從 Gen1 完全移轉至 Gen2。
預期在移轉期間和完全移轉期間都需要停機。
適用於可承受停機,且可以一次升級所有應用程式的管線。
提示
請考慮使用 Azure 入口網站以縮短停機時間,並減少您完成移轉所需的步驟數目。
增量複製模式
開始將資料從 Gen1 移至 Gen2。 建議使用 Azure Data Factory。 ACL 會與資料一起複製。
以累加方式從 Gen1 複製新資料。
所有資料皆複製後,請停止所有對 Gen1 的寫入,並將工作負載指向 Gen2。
解除委任 Gen1。
請在我們的增量複製移轉範例中,查看增量複製模式的範例程式碼。
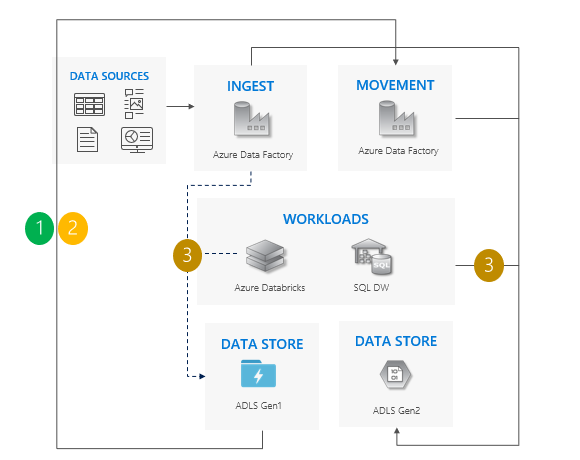
使用增量複製模式的考量:
同時將所有工作負載從 Gen1 完全移轉至 Gen2。
預期只有完全移轉期間需要停機。
適用於一次升級所有應用程式,但複製資料需要較多時間的管線。
雙重管線模式
將資料從 Gen1 移至 Gen2。 建議使用 Azure Data Factory。 ACL 會與資料一起複製。
將新資料擷取至 Gen1 和 Gen2。
將工作負載指向 Gen2。
停止所有對 Gen1 的寫入,然後解除委任 Gen1。
請在我們的雙重管線移轉範例中,查看雙重管線模式的範例程式碼。
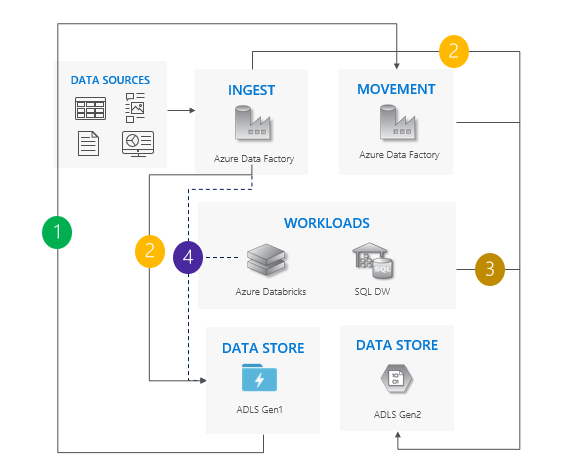
使用雙重管線模式的考量:
Gen1 和 Gen2 管線並存執行。
支援零停機。
適用於您的工作負載和應用程式無法承受任何停機,且您可以擷取至兩個儲存體帳戶的情況。
雙向同步模式
設定 Gen1 與 Gen2 之間的雙向複寫。 建議使用 WanDisco。 它提供現有資料的修復功能。
所有移動都完成後,請停止所有對 Gen1 的寫入,並關閉雙向複寫。
解除委任 Gen1。
請在我們的雙向同步移轉範例中,查看雙向同步模式的範例程式碼。
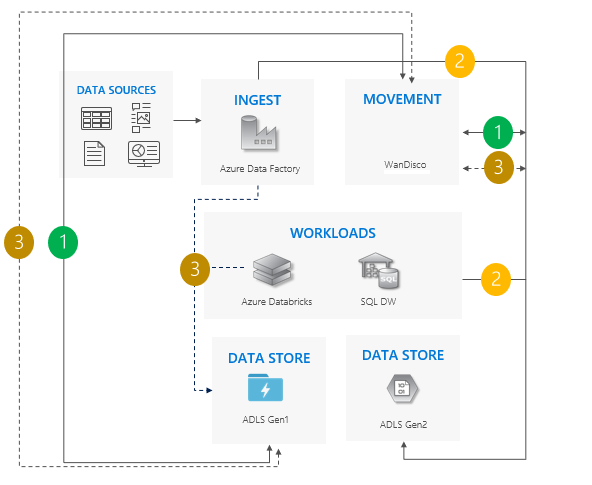
使用雙向同步模式的考量:
適用於涉及大量管線和相依性,且分階段的方法可能更恰當的複雜案例。
移轉工作量較高,但提供 Gen1 與 Gen2 的並存支援。
下一步
- 了解設定儲存體帳戶安全性的各個環節。 如需詳細資料,請參閱 Azure 儲存體安全性指南。
- 將 Data Lake Store 的效能最佳化。 請參閱最佳化 Azure Data Lake Storage Gen2 效能
- 檢閱管理 Data Lake Store 的最佳做法。 請參閱使用 Azure Data Lake Storage Gen2 的最佳做法