以 Parquet 格式從事件中樞擷取資料
本文說明如何使用無程式碼編輯器,以 Parquet 格式自動擷取事件中樞 Azure Data Lake Storage Gen2中的串流資料。
必要條件
具有事件中樞的Azure 事件中樞命名空間,以及具有容器來儲存所擷取資料的Azure Data Lake Storage Gen2帳戶。 這些資源必須可公開存取,而且無法在 Azure 虛擬網路中位於防火牆後方或受到保護。
如果您沒有事件中樞,請依照快速入門中的指示建立一個: 建立事件中樞。
如果您沒有Data Lake Storage Gen2帳戶,請遵循建立儲存體帳戶的指示建立一個帳戶
事件中樞中的資料必須以 JSON、CSV 或 Avro 格式序列化。 基於測試目的,請選取左側功能表上的 [ 產生資料 (預覽) ],選取 [ 資料集的股票資料 ],然後選取 [ 傳送]。
![顯示 [產生資料] 頁面以產生範例股票資料的螢幕擷取畫面。](media/capture-event-hub-data-parquet/stocks-data.png)
![顯示 [產生資料] 頁面以產生範例股票資料的螢幕擷取畫面。](media/capture-event-hub-data-parquet/stocks-data.png#lightbox)
設定作業以擷取資料
使用下列步驟來設定串流分析作業,以擷取 Azure Data Lake Storage Gen2 中的資料。
在 Azure 入口網站中,瀏覽至您的事件中樞。
在左側功能表上,選取 [功能] 底下的[處理資料]。 然後,在[擷取資料至 Parquet 格式卡片的 ADLS Gen2] 上選取[開始]。

輸入串流分析作業 的名稱 ,然後選取 [ 建立]。
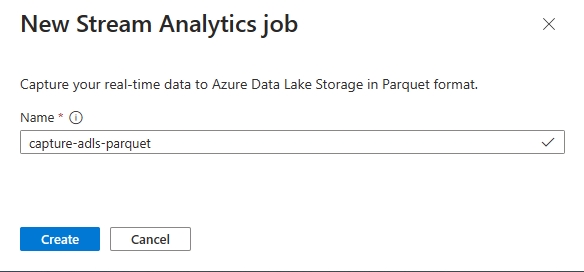
在事件中樞中指定資料的 序列化 類型,以及作業用來連線到事件中樞的 驗證方法 。 然後選取 [連線] 。

成功建立連線時,您會看到:
輸入資料中存在的欄位。 您可以選擇 [新增欄位],也可以選取欄位旁的三個點符號,以選擇性地移除、重新命名或變更其名稱。
圖表檢視下 [資料預覽] 資料表中傳入資料的即時範例。 該範例會定期重新整理。 您可以選取 [暫停串流預覽] 來檢視範例輸入的靜態檢視。

選取 [Azure Data Lake Storage Gen2] 圖格以編輯設定。
在 [Azure Data Lake Storage Gen2 設定] 頁面上,遵循下列步驟:
從下拉式功能表中選取訂用帳戶、儲存體帳戶名稱和容器。
選取訂用帳戶之後,系統應會自動填入驗證方法和儲存體帳戶金鑰。
選取 [Parquet ] 進行 序列化 格式。

對於串流 Blob,目錄路徑模式必須是動態值。 日期必須是 Blob 檔案路徑的一部分,稱為
{date}。 若要了解自訂路徑模式,請參閱 Azure 串流分析自訂 Blob 輸出分割。
選取 [連線]
建立連接時,您會看到輸出資料中存在的欄位。
在命令列上選取 [儲存],以便儲存設定。
![顯示命令列上選取 [儲存] 按鈕的螢幕擷取畫面。](media/capture-event-hub-data-parquet/save-configuration.png)
在命令列上選取 [啟動],以便啟動串流流程來擷取資料。 然後在 [啟動串流分析] 作業視窗中:
選擇輸出開始時間。
選取定價方案。
選取作業執行時的串流單位 (SU) 數目。 SU 代表配置用來執行串流分析作業的計算資源。 如需詳細資訊,請參閱 Azure 串流分析串流單位。

您應該會在事件中樞的 [處理資料] 頁面的 [串流分析作業] 索引標籤中看到串流分析作業。
![顯示 [處理資料] 頁面上串流分析作業的螢幕擷取畫面。](media/capture-event-hub-data-parquet/process-data-page-jobs.png)






![顯示 [處理資料] 頁面上串流分析作業的螢幕擷取畫面。](media/capture-event-hub-data-parquet/process-data-page-jobs.png#lightbox)
驗證輸出
在事件中樞的 [事件中樞實例] 頁面上,選取 [產生資料]、選取資料集的 [股票資料 ],然後選取 [ 傳送 ] 將一些範例資料傳送至事件中樞。
確認 Parquet 檔案是否在 Azure Data Lake Storage 容器中產生的。

選取左側功能表上的 [處理資料 ]。 切換至 [ 串流分析作業 ] 索引標籤。選取 [開啟計量 ] 以監視它。

以下是顯示輸入和輸出事件的計量範例螢幕擷取畫面。




後續步驟
現在,您已了解如何使用串流分析,而不需要程式碼編輯器來建立作業,以 Parquet 格式擷取至 Azure Data Lake Storage Gen2 的事件中樞資料。 接下來,您可以深入了解 Azure 串流分析,以及如何監視您所建立的作業。