Azure Stream Analytics 同時支援雲端與 Azure IoT Edge,內建基於機器學習的異常偵測功能,可用來監控兩種最常見的異常:暫時性與持續性。 透過使用 AnomalyDetection_SpikeAndDip 和 AnomalyDetection_ChangePoint 函式,你可以直接在 Stream Analytics 工作中進行異常偵測。
機器學習模型採用統一採樣的時間序列。 如果時間序列不均勻,請在呼叫異常偵測前插入帶有翻滾視窗的聚合步驟。
目前機器學習操作不支援季節性趨勢或多變量相關性。
利用機器學習在 Azure Stream Analytics 進行異常偵測
以下影片示範如何利用 Azure Stream Analytics 中的機器學習功能即時偵測異常。
模型行為
通常,滑動視窗中的數據越多,模型的準確性就越高。 指定滑動視窗中的數據被視為該時間範圍內其正常值範圍的一部分。 該模型僅考慮滑動視窗上的事件歷史記錄,以檢查當前事件是否異常。 當滑動視窗移動時,舊值將被移除出模型的訓練資料中。
這些函數的運作方式是根據到目前為止他們所見到的情況來建立某種標準常態。 通過在置信度內與已建立的正常值進行比較來識別異常值。 視窗大小應基於訓練模型實現正常行為所需的最小事件數,以便在發生異常時能夠識別它。
模型的回應時間隨著歷史記錄大小的增加而增加,因為它需要與過去更多事件進行比較。 為了提升效能,只包含必要的事件數量。
當模型在某些時間點未接收事件時,時間序列中會出現缺口。 Stream Analytics 透過補值邏輯處理此情況。 歷史大小及同一滑動視窗的時間長度,用來計算事件預期抵達的平均速率。
你可以使用 異常產生器來餵入包含不同異常模式的資料給IoT Hub。 你可以利用這些異常偵測功能設定 Azure Stream Analytics 工作,從這個 IoT Hub 讀取並偵測異常。
尖峰和谷底
時間序列事件流中的臨時異常稱為峰值和低谷。 你可以使用基於Machine Learning的運算子
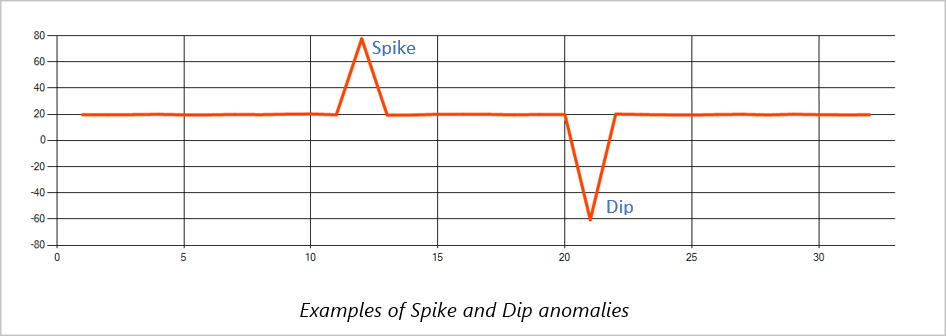
在同一滑動視窗中,若第二個尖峰比第一個尖峰小,較小尖峰的計算分數可能與第一個尖峰在指定信賴水準內的分數不夠顯著。 您可以嘗試降低模型的置信度來檢測此類異常。 不過,如果警報過多,建議使用較高的信賴區間。
以下示例查詢假定在 2 分鐘滑動視窗中的統一輸入速率為每秒 1 個事件,歷史記錄為 120 個事件。 最終的 SELECT 語句提取並輸出置信度為 95%的分數和異常狀態。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
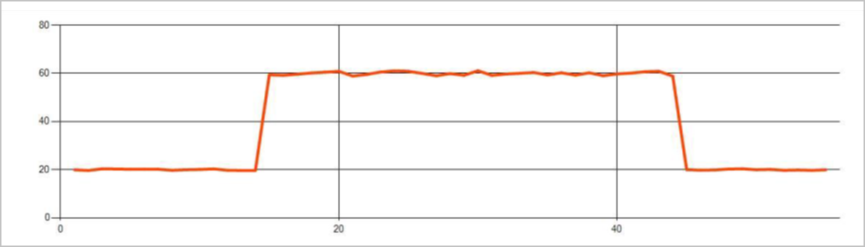
轉折點
時間序列事件流中的持續異常是事件流中值分佈的變化,例如級別變化和趨勢。 在 Stream Analytics 中,基於 Machine Learning 的
持續的變化比高峰和低谷持續的時間長得多,可能預示著災難性事件。 持續的變化通常肉眼看不到,但 AnomalyDetection_ChangePoint 操作員可以察覺。
下圖是等級更改的範例:
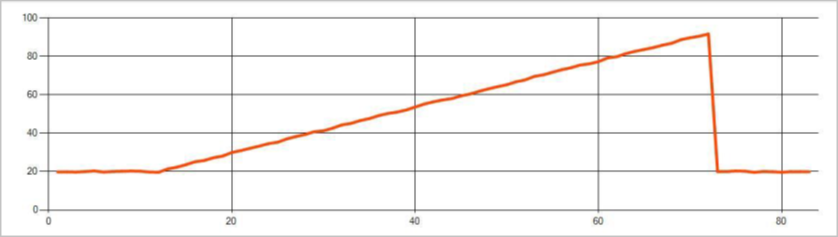
下圖是趨勢變化的範例:
以下示例查詢假定在 20 分鐘滑動視窗中的統一輸入速率為每秒一個事件,歷史記錄大小為 1,200 個事件。 最終的 SELECT 語句提取並輸出置信度為 80%的分數和異常狀態。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
效能特性
這些模型的性能取決於歷史記錄大小、視窗持續時間、事件負載以及是否使用函數級分區。 本節討論這些配置,並提供如何維持每秒1 千、5 千及10 千事件的攝取速率的範例。
- 歷史大小 - 這些模型的表現與歷史大小成線性關係。 歷史記錄大小越長,模型對新事件進行評分所需的時間就越長。 模型會將新事件與歷史緩衝區中過去的每個事件進行比較。
- 視窗長度 - 視窗長度 應反映收到與歷史大小所規定事件數量所需的時間。 若視窗內沒有那麼多事件,Azure 串流分析將會插補遺失值。 因此,CPU 消耗是與歷史大小相關的函數。
- 事件負載 - 事件負載越大,模型執行的工作越多,進而影響 CPU 消耗。 假設業務邏輯適合使用更多輸入分區,您可以透過使作業成為極致平行來向外擴充作業。
-
函式層級分割 - 在異常偵測函式呼叫中使用
PARTITION BY以執行 函式層級分割。 這種分割方式會增加開銷,因為工作需要同時維持多個模型的狀態。 在像裝置層級分割這類情境中使用函式層級分割。
關聯性
歷史記錄大小、視窗持續時間和總事件負載按以下方式相關:
windowDuration (以毫秒為單位) = 1000 * historySize / (每秒總輸入事件數 / 輸入分區計數)
當按 deviceId 對函數進行分區時,在異常檢測函數調用中添加 「PARTITION BY deviceId」。
觀測
下表顯示了非分割情況下單一節點(六個 SU)的吞吐量觀測值:
| 歷史記錄大小(事件) | 視窗持續時間 (ms) | 每秒輸入事件總數 |
|---|---|---|
| 六十 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
下表顯示分割情況下單一節點(六個 SU)的吞吐量觀察值:
| 歷史記錄大小(事件) | 視窗持續時間 (ms) | 每秒輸入事件總數 | 裝置計數 |
|---|---|---|---|
| 六十 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 六十 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
你可以在 Azure Samples 的
備註
如需更精確的評估,請自訂範例以符合您的案例。
識別瓶頸
要找出管線中的瓶頸,請使用 Azure Stream Analytics 工作中的 Metrics 面板。 檢視 輸入/輸出事件 的吞吐量,以及 「浮水印延遲」 或 待辦事件 ,看看工作是否能跟上輸入速率。 針對事件中樞計量,請尋找節流要求並據此調整閾值單位。 針對 Azure Cosmos DB 指標,請查看輸送量底下的每個分區金鑰範圍的最大已取用 RU/s,以確保您的分區金鑰範圍已平均取用。 對於Azure SQL資料庫,監控 Log IO 和 CPU。