Azure Synapse Analytics 提供各種分析引擎,可協助您內嵌、轉換、模型、分析及散發數據。 Apache Spark 集區提供開放原始碼巨量數據計算功能。 在 Synapse 工作區中建立 Apache Spark 集區後,即可載入、建模、處理和散發數據,以更快速地獲得分析深入洞察。
在本快速入門中,您將瞭解如何使用 Azure 入口網站在 Synapse 工作區中建立 Apache Spark 集區。
這很重要
無論使用與否,Spark 執行個體都是按分鐘計費。 當您使用完 Spark 執行個體之後,請務必將其關閉,或設定短暫的逾時時間。 如需詳細資訊,請參閱本文的清除資源一節。
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
先決條件
- 您將需要 Azure 訂用帳戶。 如有需要, 請建立免費的 Azure 帳戶
- 您將會使用 Synapse 工作區 (部分機器翻譯)。
登入 Azure 入口網站
登入 Azure 入口網站
流覽至 Synapse 工作區
在搜尋列中輸入服務名稱 (或直接輸入資源名稱),瀏覽至要建立 Apache Spark 集區的 Synapse 工作區。
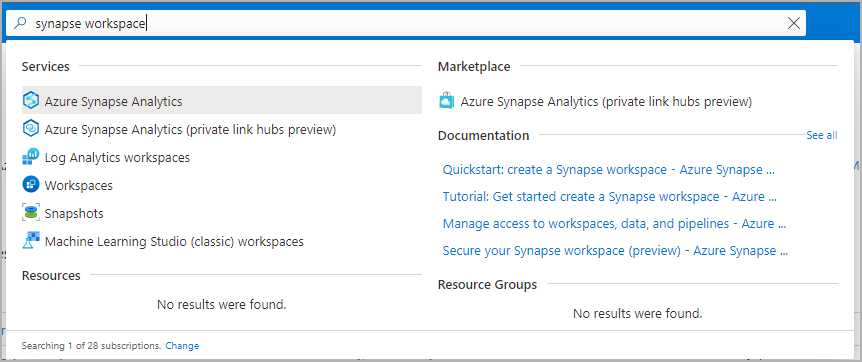
從工作區清單中,輸入要開啟之工作區的名稱(或部分名稱)。 在此範例中,我們會使用名為 contosoanalytics 的工作區。
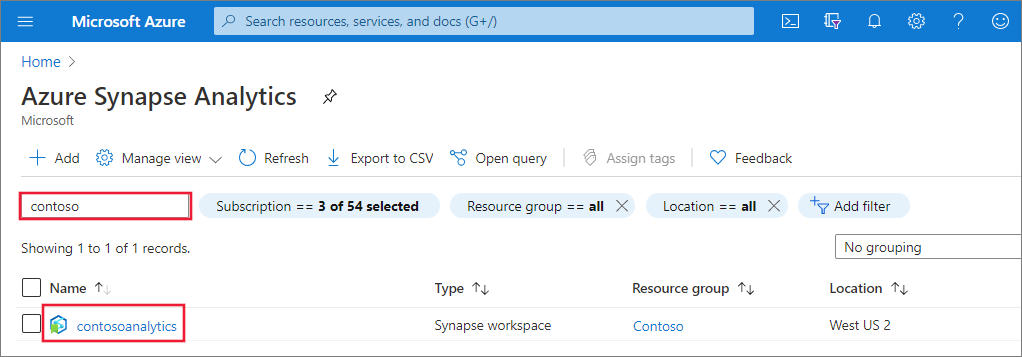


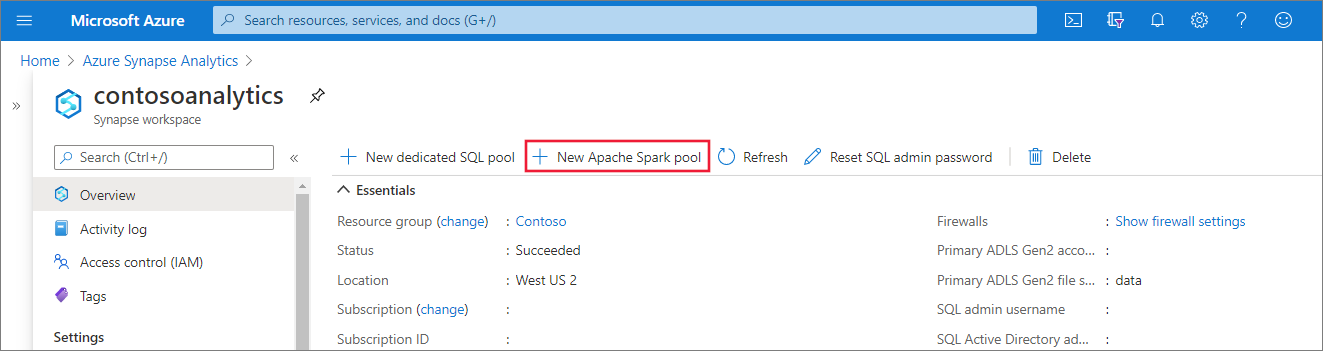
建立新的 Apache Spark 集區
在您要在其中建立 Apache Spark 集區的 Synapse 工作區中,選取 [新增 Apache Spark 集區]。
在 [基本] 索引標籤中,輸入下列詳細資料:
設定 建議的值 描述 Apache Spark 集區名稱 有效的集區名稱,如 contosospark這是 Apache Spark 集區將擁有的名稱。 節點大小 小 (4 個虛擬 CPU/32 GB) 將此設為最小的大小,以降低本快速入門的成本 自動調整 已停用 本快速入門不需要自動調整 節點數目 5 本快速入門使用小型大小來限制成本 
這很重要
Apache Spark 集區可以使用的名稱有特定限制。 名稱只可包含字母或數字,字元數必須為 15 或更少,且必須以字母開頭,不能包含保留字組,而且名稱在工作區中必須是唯一的。
選取 [下一步:其他設定 ],並檢閱預設設定。 請勿修改任何預設設定。
![Azure 入口網站的螢幕快照,顯示已選取 [其他設定] 索引標籤的 [建立 Apache Spark 集區] 頁面。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-03.png)
選取 [下一步:標籤]。 考慮使用 Azure 標記。 例如,"Owner" 或 "CreatedBy" 標記用來識別建立資源的人,以及 "Environment" 標記用來識別此資源是否在生產、開發。如需詳細資訊,請參閱開發 Azure 資源的命名和標記策略。

選擇 檢閱 + 創建。
請確認細節是否正確無誤,然後點擊 建立。

此時,資源佈建流程將會啟動,並在完成後提供指示。
![Azure 入口網站的螢幕快照,其中顯示 [概觀] 頁面,並顯示 [您的部署已完成] 訊息。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-06.png)
佈建完成之後,瀏覽回工作區時會顯示新建立的 Apache Spark 集區項目。
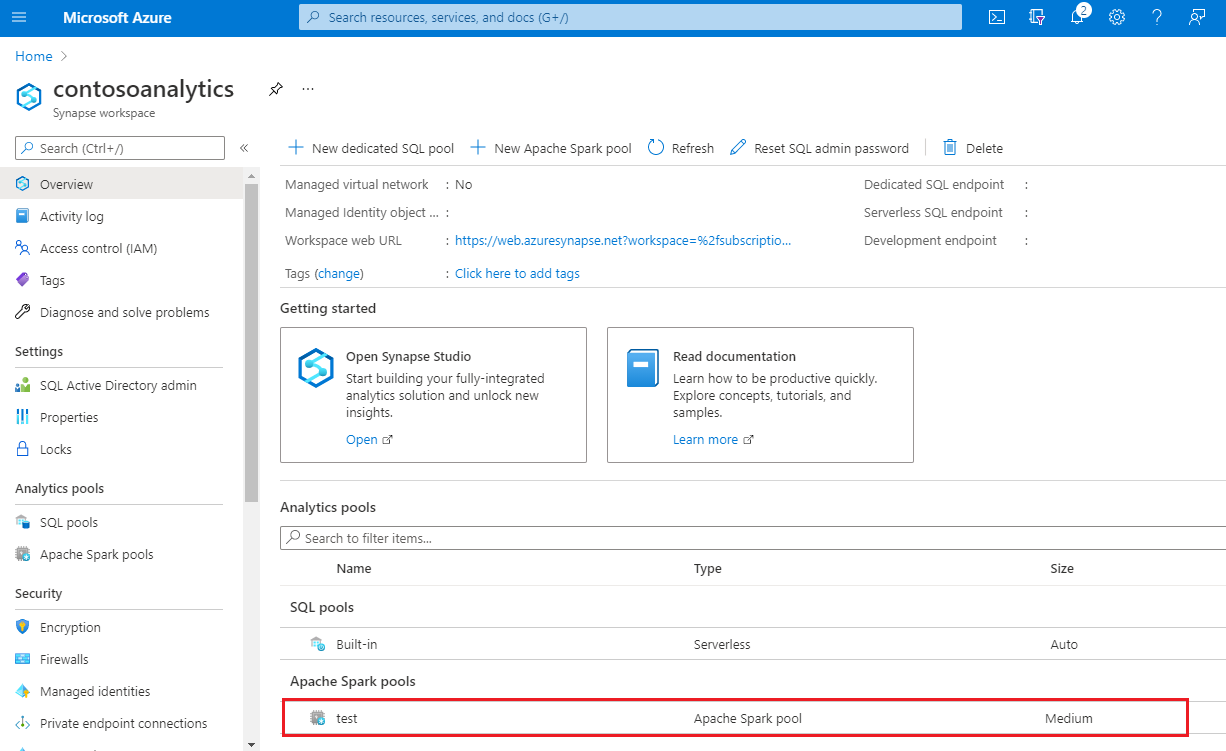
此時,沒有正在執行中的資源,Spark 不會產生費用,您已建立想建立的 Spark 執行個體中繼資料。


![Azure 入口網站的螢幕快照,顯示已選取 [其他設定] 索引標籤的 [建立 Apache Spark 集區] 頁面。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-03.png#lightbox)


![Azure 入口網站的螢幕快照,其中顯示 [概觀] 頁面,並顯示 [您的部署已完成] 訊息。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-06.png#lightbox)

清理資源
下列步驟會從工作區中刪除 Apache Spark 集區。
警告
刪除 Apache Spark 集區將會從工作區中移除分析引擎。 將無法再連線到集區,而且使用此 Apache Spark 集區的所有查詢、管線和筆記本將無法再運作。
如果要刪除 Apache Spark 集區,請執行下列步驟:
- 瀏覽至工作區中的 Apache Spark 集區窗格。
- 選取要刪除的 Apache Spark 集區(在此案例中為 contosospark)。
- 選擇 刪除。

- 確認刪除,然後選取 [ 刪除] 按鈕。
![從 Azure 入口網站的 [確認] 對話框螢幕快照,以刪除選取的 Apache Spark 集區。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-10.png)
- 當流程成功完成時,Apache Spark 集區就不會再列入工作區資源中。
