針對 Azure Synapse Analytics 中的無伺服器 SQL 集區進行疑難排解
關於如何針對 Azure Synapse Analytics 中的無伺服器 SQL 集區最常見問題進行疑難排解,本文會有相關資訊。
若要深入了解 Azure Synapse Analytics,請參閱概觀和 Azure Synapse Analytics 的新功能。
Synapse Studio
Synapse Studio 是很容易使用的工具,可用來透過瀏覽器存取資料,而不需要安裝資料庫存取工具。 Synapse Studio 並非設計來讀取大量資料或 SQL 物件的完整管理。
Synapse Studio 中的無伺服器 SQL 集區呈現灰色
如果 Synapse Studio 無法與無伺服器 SQL 集區連線,您將會發現無伺服器 SQL 集區呈現灰色,或顯示狀態為離線。
此問題通常是由於下列兩個原因之一所造成:
- 您的網路會防止與 Azure Synapse Analytics 後端通訊。 最常見的情況是 TCP 通訊埠 1443 已遭到封鎖。 若要讓無伺服器 SQL 集區正常執行,請將此連接埠解除封鎖。 其他問題也可能會造成無伺服器 SQL 集區無法運作。 如需詳細資訊,請參閱疑難排解指南。
- 您沒有登入無伺服器 SQL 集區的權限。 若要取得存取權,Azure Synapse 工作區管理員必須將您新增至工作區管理員角色或 SQL 管理員角色。 如需詳細資訊,請參閱 Azure Synapse 存取控制。
WebSocket 連線意外關閉
您的查詢可能失敗,並出現錯誤訊息 Websocket connection was closed unexpectedly.此訊息表示您的瀏覽器與 Synapse Studio 的連線已中斷,例如因為網路問題而中斷。
- 若要解決此問題,請重新執行您的查詢。
- 嘗試透過 Azure Data Studio 或 SQL Server Management Studio (而不是 Synapse Studio) 進行相同的查詢,做進一步的調查。
- 如果此問題經常發生在您的環境中,請向網路管理員尋求協助。 您也可以檢查防火牆設定,並查看疑難排解指南。
- 如果問題持續發生,請透過 Azure 入口網站建立支援票證。
Synapse Studio 不會顯示無伺服器資料庫
如果您在無伺服器 SQL 集區中沒有看到建立的資料庫,請檢查您的無伺服器 SQL 集區是否已啟動。 如果停用無伺服器 SQL 集區,則不會顯示資料庫。 在無伺服器 SQL 集區上執行任何查詢 (例如 SELECT 1) 以將其啟用,並讓資料庫顯示。
Synapse 無伺服器 SQL 集區會顯示為無法使用
造成此行為的原因通常是錯誤的網路設定。 請確認連接埠已正確設定。 如果您使用防火牆或私人端點,請一併檢查這些設定。
最後,請確認已授與適當的角色,且尚未撤銷這些角色。
無法建立新的資料庫,因為要求會使用舊的/過期的金鑰
此錯誤是由於變更用於加密的工作區客戶自控金鑰所造成。 您可以選擇使用最新版的使用中金鑰來重新加密工作區的所有資料。 若要重新加密,請在 Azure 入口網站將金鑰變更為臨時金鑰,然後切換回您要用於加密的金鑰。 在這裡了解如何管理工作區金鑰。
將訂閱轉移至不同的 Microsoft Entra 租用戶之後,即無法使用 Synapse 無伺服器 SQL 集區
如果您將訂閱移至另一個 Microsoft Entra 租用戶,可能會遇到一些無伺服器 SQL 集區問題。 請建立支援票證,Azure 支援人員會與您連絡以解決問題。
儲存體存取
如果您在嘗試存取 Azure 儲存體中的檔案時收到錯誤,請確認您有權存取資料。 您應該能夠存取公開可用的檔案。 如果您嘗試在沒有認證的情況下存取資料,請確認您的 Microsoft Entra 身分可以直接存取檔案。
如果您有用來存取檔案的共用存取簽章金鑰,請確認您已建立包括該認證的伺服器層級或資料庫範圍認證。 如果您需要使用工作區受控識別和自訂服務主體名稱 (SPN) 來存取資料,則需要認證。
無法讀取、列出或存取 Azure Data Lake Storage 中的檔案
如果您使用沒有明確認證的 Microsoft Entra 登入,請確認您的 Microsoft Entra 身分可以存取儲存體中的檔案。 若要存取檔案,您的 Microsoft Entra 身分必須具有 Blob 資料讀者權限,或具有列出和讀取ADLS 中存取控制清單 (ACL) 的權限。 如需詳細資訊,請參閱查詢因為無法開啟檔案而失敗。
如果您要使用認證來存取儲存體,請確認您的受控識別或 SPN 具有資料讀者或參與者角色,或是特定 ACL 權限。 如果您已使用共用存取簽章權杖,請確認其擁有 rl 權限且未過期。
如果您使用 SQL 登入並使用無資料來源的 OPENROWSET 函式,請確認您具有符合儲存體 URI 的伺服器層級認證,而且具有存取儲存體的權限。
查詢因為無法開啟檔案而失敗
如果您的查詢失敗,並出現錯誤 File cannot be opened because it does not exist or it is used by another process,而且您確定檔案既存在,也沒有由其他處理序使用中,則表示無伺服器 SQL 集區無法存取該檔案。 此問題發生的原因通常是您的 Microsoft Entra 身分沒有存取檔案的權限,或者因為防火牆封鎖了檔案的存取。
根據預設,無伺服器 SQL 集區會嘗試使用您的 Microsoft Entra 身分來存取檔案。 若要解決此問題,您必須具有可存取該檔案的適當權限。 最簡單的方式是在您嘗試查詢的儲存體帳戶上對自己授與儲存體 Blob 資料參與者角色。
如需詳細資訊,請參閱
「儲存體 Blob 資料參與者」的替代角色
除了對自己授與儲存體 Blob 資料參與者角色之外,您也可以授與更精細的檔案子集權限。
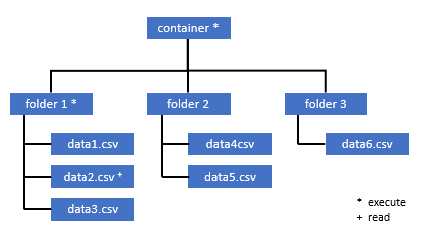
需要存取此容器中某些資料的所有使用者也必須擁有所有父代資料夾 (直到根目錄的容器) 的執行權限。
深入了解如何在 Azure Data Lake Storage Gen2 中設定 ACL。
注意
必須在 Azure Data Lake Storage Gen2 內設定容器層級的執行權限。 您可以在 Azure Synapse Analytics 中設定資料夾的權限。
如果要查詢在此範例中 data2.csv,則需要下列權限:
- 容器上的執行權限
- folder1 上的執行權限
- data2.csv 上的讀取權限
使用對欲存取的資料具有完整權限的系統管理員使用者身分,登入 Azure Synapse Analytics。
在資料窗格中,以滑鼠右鍵按一下檔案,然後選取 [管理存取]。
![顯示 [管理存取權] 選項的螢幕擷取畫面。](media/resources-self-help-sql-on-demand/manage-access.png)
至少選取 [讀取] 權限。 輸入使用者的 UPN 或物件識別碼,例如
user@contoso.com。 選取 [新增]。授與此使用者讀取權限。

注意
若是來賓使用者,此步驟必須直接使用 Azure Data Lake 完成,因為其無法直接透過 Azure Synapse 完成。
無法列出路徑上的目錄內容
此錯誤表示正在查詢 Azure Data Lake 的使用者無法列出儲存體中的檔案。 有幾種情況可能會發生此錯誤:
- 使用 Microsoft Entra 傳遞驗證的 Microsoft Entra 使用者沒有列出 Data Lake Storage 中檔案的權限。
- Microsoft Entra ID 或 SQL 使用者使用共用存取簽章金鑰或工作區受控識別讀取資料,而該金鑰或身分識別沒有列出儲存體中檔案的權限。
- 正在存取 Dataverse 資料的使用者無權查詢 DataVerse 中的資料。 如果您使用 SQL 使用者,便可能會發生這種情況。
- 正在存取 Delta Lake 的使用者可能沒有讀取 Delta Lake 交易記錄的權限。
解決此問題最簡單的方式是,在您嘗試查詢的儲存體帳戶中對自己授與儲存體 Blob 資料參與者角色。
如需詳細資訊,請參閱
無法列出 Dataverse 資料表的內容
如果您使用 Azure Synapse Link for Dataverse 來讀取已連結的 Dataverse 資料表,則需要使用 Microsoft Entra 帳戶來存取使用無伺服器 SQL 集區的連結資料。 如需詳細資訊,請參閱適用於 Dataverse 的 Azure Synapse Link 與 Azure Data Lake。
如果您嘗試使用 SQL 登入來讀取參考 DataVerse 資料表的外部資料表,您將會收到下列錯誤:External table '???' is not accessible because content of directory cannot be listed.
Dataverse 外部資料表一律使用 Microsoft Entra 傳遞驗證。 您無法將其設定為使用共用存取簽章金鑰或工作區受控識別。
無法列出 Delta Lake 交易記錄的內容
無伺服器 SQL 集區無法讀取 Delta Lake 交易記錄資料夾時,會傳回下列錯誤:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
確定 _delta_log 資料夾存在。 或許您正在查詢未轉換成 Delta Lake 格式的純 Parquet 檔案。 如果 _delta_log 資料夾存在,請確認您擁有基礎 Delta Lake 資料夾的讀取和列出權限。 嘗試使用 FORMAT='csv' 直接讀取 JSON 檔案。 將您的 URI 放在 BULK 參數中:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
如果此查詢失敗,則表示呼叫者沒有讀取基礎儲存體檔案的權限。
查詢執行
在下列情況下,您可能會在查詢執行期間收到錯誤:
- 呼叫者無法存取某些物件。
- 查詢無法存取外部資料。
- 查詢包含無伺服器 SQL 集區不支援的某些功能。
查詢失敗,因為目前的資源條件約束導致其無法執行
您的查詢可能失敗,並出現錯誤訊息 This query cannot be executed due to current resource constraints.此訊息表示目前無法執行無伺服器 SQL 集區。 以下是一些疑難排解選項:
- 確定您已使用適當大小的資料類型。
- 如果您的查詢以 Parquet 檔案為目標,請考慮定義明確的字串資料行類型,因為其預設為 VARCHAR (8000)。 檢查推斷的資料類型。
- 如果您的查詢以 CSV 檔案作為目標,請考慮建立統計資料。
- 若要將查詢最佳化,請參閱無伺服器 SQL 集區的效能最佳做法。
查詢逾時終止
如果查詢在無伺服器 SQL 集區上執行超過 30 分鐘,就會傳回錯誤 Query timeout expired。 您無法變更無伺服器 SQL 集區的此限制。
- 請嘗試套用最佳做法來最佳化您的查詢。
- 請嘗試使用 create external table as select (CETAS) 具體化部分查詢。
- 檢查無伺服器 SQL 集區上是否有並行執行的工作負載,因為其他查詢可能會使用資源。 在此情況下,建議您將工作負載分割在多個工作區上。
無效的物件名稱
錯誤 Invalid object name 'table name' 表示無伺服器 SQL 集區資料庫中不存在您正在使用的物件,例如資料表或檢視表。 請嘗試這些選項:
請列出資料表或視圖,然後檢查物件是否存在。 使用 SQL Server Management Studio 或 Azure Data Studio,因為Synapse Studio 可能會顯示無伺服器 SQL 集區中無法使用的一些資料表。
如果有看到物件,請確認您是否使用了一些區分大小寫/二進位資料庫定序的名稱。 可能是物件名稱不符合您在查詢中使用的名稱。 使用二進位資料庫定序,
Employee與employee會是兩個不同的物件。如果您沒有看到物件,可能是您嘗試從資料湖或 Spark 資料庫查詢資料表。 資料表可能無法在無伺服器 SQL 集區中使用,因為:
- 資料表有一些無法在無伺服器 SQL 集區中表示的資料行類型。
- 資料表具有無伺服器 SQL 集區中不支援的格式。 範例包括 Avro 或 ORC。
將會截斷字串或二進位資料
如果字串或二進位資料行類型的長度 (例如 VARCHAR、VARBINARY 或 NVARCHAR) 小於您讀取的實際資料大小,則會發生此錯誤。 您可以增加資料行類型的長度來修正此錯誤:
- 如果您的字串資料行定義為
VARCHAR(32)類型,而且文字為 60 個字元,則請在資料行結構描述中使用VARCHAR(60)類型 (或更長)。 - 如果您要使用結構描述推斷 (沒有
WITH結構描述),則所有字串資料行都會自動定義為VARCHAR(8000)類型。 如果您收到此錯誤,則請在WITH子句中明確定義具有較大VARCHAR(MAX)資料行類型的結構描述,以解決此錯誤。 - 如果您的資料表位於 Lake 資料庫中,則請嘗試增加 Spark 集區中的字串資料行大小。
- 嘗試
SET ANSI_WARNINGS OFF以讓無伺服器 SQL 集區自動截斷 VARCHAR 值,若這不會影響您的功能。
遺漏字元字串後面的引號
在罕見的情況下,當您在字串資料行上使用 LIKE 運算子或與字串常值進行一些比較時,您可能會收到下列錯誤:
Unclosed quotation mark after the character string
如果您在資料行上使用 Latin1_General_100_BIN2_UTF8 定序,就可能發生此錯誤。 請嘗試在資料行上設定 Latin1_General_100_CI_AS_SC_UTF8 定序 (而不是 Latin1_General_100_BIN2_UTF8 定序) 來解決問題。 如果仍然傳回錯誤,請透過 Azure 入口網站提出支援要求。
將資料從一個散發資料庫傳送到另一個時,無法配置 tempdb 空間
當查詢執行引擎無法處理資料,並且在執行查詢的節點之間傳送資料時,則會傳回錯誤 Could not allocate tempdb space while transferring data from one distribution to another。 此為一般查詢失敗,因為目前的資源條件約束導致其無法執行錯誤的特殊案例。 當配置給tempdb資料庫的資源不足以執行查詢時,會傳回此錯誤。
在您提出支援票證之前,請先套用最佳做法。
查詢失敗,並出現處理外部檔案時發生錯誤 (已達最大錯誤計數)
如果您的查詢失敗,並出現錯誤訊息 error handling external file: Max errors count reached,表示指定的資料行類型與需要載入的資料不符。
若要取得有關錯誤的詳細資訊,以及要查看的資料列和資料行,請將剖析器版本從 2.0 變更為 1.0。
範例
如果您想要使用此查詢 1 查詢 names.csv 檔案,Azure Synapse 無伺服器 SQL 集區會傳回下列錯誤:Error handling external file: 'Max error count reached'. File/External table name: [filepath].例如:
names.csv 檔案包含:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
查詢 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
原因
當剖析器版本從 2.0 版變更為 1.0 版時,錯誤訊息可協助您辨別問題。 新的錯誤訊息現在為 Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
截斷代表您的資料行類型太小,無法容納資料。 此 names.csv 檔案中最長的名字為七個字元。 要使用的對應資料類型應該至少是 VARCHAR(7)。 此行程式碼造成該錯誤:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
據此變更查詢可解決錯誤。 執行偵錯之後,請再次將剖析器版本變更為 2.0,以達到最大效能。
如需何時使用哪個剖析器版本的詳細資訊,請參閱在 Synapse Analytics 中透過無伺服器 SQL 集區使用 OPENROWSET。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
無法大量載入,因為檔案無法開啟
如果在查詢執行期間修改檔案,則會傳回錯誤 Cannot bulk load because the file could not be opened。 您通常可能會收到錯誤,例如 Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
無伺服器 SQL 集區無法在執行查詢時讀取正在修改的檔案。 查詢無法對檔案進行鎖定。 如果您知道修改作業是附加的,您可以嘗試設定下列選項:{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}。
如需詳細資訊,請參閱如何查詢僅限附加的檔案或在僅限附加的檔案上建立資料表。
查詢失敗,因為資料轉換錯誤
您的查詢可能失敗,並出現錯誤訊息 Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath].此訊息表示資料類型不符合資料列編號 n 和資料行 m 的實際資料。
例如,如果您預期資料中只有整數,但第 n 列有字串,您就會收到此錯誤訊息。
若要解決此問題,請檢查檔案和您所選擇的資料類型。 也請檢查您的資料列分隔符號和欄位結束字元設定是否正確。 下列範例顯示如何使用 VARCHAR 作為資料行類型來完成檢查。
如需欄位結束字元、資料列分隔符號和逸出引號字元的詳細資訊,請參閱查詢 CSV 檔案。
範例
如果您想要查詢 names.csv 檔案:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
使用下列查詢:
查詢 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse 無伺服器 SQL 集區會傳回錯誤 Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
您必須瀏覽資料,並做出明智的決策來處理這個問題。 若要查看造成此問題的資料,必須先變更資料類型。 目前使用 VARCHAR(100) 來分析這個問題,而不是使用 SMALLINT 資料類型查詢「識別碼」資料行。
透過此稍加變更過的查詢 2,系統現在可以處理資料,並傳回名稱清單。
查詢 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
您可能會在第五列中看到資料有非預期的識別碼值。 在這種情況下,請務必與資料的商務擁有者保持一致,在避免類似此範例的損毀資料上存有共識。 如果無法在應用層級上執行預防措施,合理大小的 VARCHAR 可能是此處的唯一選項。
提示
盡量讓 VARCHAR() 越短越好。 盡可能避免 VARCHAR(MAX),因為這可能會影響效能。
查詢結果未如預期般顯示
您的查詢可能不會失敗,但您可能會看到未如預期的結果集。 產生的資料行可能是空的,或可能會傳回非預期的資料。 在此案例中,原因可能是未正確選擇資料列分隔符號或欄位結束字元。
若要解決此問題,請以另一種方式來查看資料並變更這些設定。 偵錯此查詢很簡單,如下列範例所示。
範例
如果您想要使用查詢 1 中的查詢來查詢 names.csv 檔案,Azure Synapse 無伺服器 SQL 集區傳回的結果看起來會很奇怪:
在 names.csv 中:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
在 Firstname 資料行中似乎沒有任何值。 而是所有值最後都在 ID 資料行中。 這些值之間以逗號分隔。 此問題是由這行程式碼所造成,因為必須選擇逗號來取代分號符號做為欄位結束字元:
FIELDTERMINATOR =';',
變更這單一字元便可解決此問題:
FIELDTERMINATOR =',',
查詢 2 所建立的結果集現在看起來如同預期:
查詢 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
傳回:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
資料行類型與外部資料類型不相容
如果您的查詢失敗,並出現錯誤訊息 Column [column-name] of type [type-name] is not compatible with external data type […],,可能是因為 PARQUET 資料類型對應到不正確的 SQL 資料類型。
例如,如果您 Parquet 檔案的價格欄具有浮點數 (例如 12.89),但您卻嘗試將其對應到 INT,便會收到此錯誤訊息。
若要解決此問題,請檢查檔案和您所選擇的資料類型。 此對應表有助於選擇正確的 SQL 資料類型。 最佳做法是指定僅針對會解析成 VARCHAR 資料類型的資料行執行對應。 盡可能避免 VARCHAR,以提升查詢效能。
範例
如果您想要使用此查詢 1 查詢 taxi-data.parquet 檔案,Azure Synapse 無伺服器 SQL 集區會傳回下列錯誤:
taxi-data.parquet 檔案包含:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
查詢 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
這則錯誤訊息會告訴您資料類型不相容,同時並建議使用 FLOAT,而非 INT。 此行程式碼造成該錯誤:
SumTripDistance INT,
透過此稍加變更過的查詢 2,系統現在可以處理資料,並顯示完整的三個資料行:
查詢 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
分散式處理模式不支援查詢所參考的物件
錯誤 The query references an object that is not supported in distributed processing mode 表示您使用的物件或函式無法在查詢 Azure 儲存體或 Azure Cosmos DB 分析儲存體中的資料時使用。
在查詢儲存在 Azure Data Lake 或 Azure Cosmos DB 分析儲存體中的資料時,某些物件 (例如系統檢視) 和函式無法使用。 請避免使用以下查詢:聯結具有系統檢視表的外部資料、載入暫存資料表中的外部資料,或使用一些安全性或中繼資料函式篩選外部資料。
WaitIOCompletion 呼叫失敗
錯誤訊息 WaitIOCompletion call failed 表示查詢在等候 I/O 作業從遠端儲存體 (Azure Data Lake) 中讀取資料完成時失敗。
錯誤訊息具有下列模式:Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
確定您的儲存體位於與無伺服器 SQL 集區相同的區域中。 檢查儲存體計量,並確認儲存層上沒有其他工作負載 (例如上傳新檔案),若有可能會讓 I/O 要求飽和。
HRESULT 欄位包含結果碼。 下列錯誤碼是最常見的錯誤碼,其中包含可能的解決方案。
此錯誤碼表示來源檔案不在儲存體中。
為何發生此錯誤碼的原因:
- 另一個應用程式已刪除該檔案。
- 在此常見案例朱,查詢執行開始,其會列舉檔案並找到檔案。 之後,在查詢執行期間刪除了某個檔案。 例如,可能是透過 Databricks、Spark 或 Azure Data Factory 來刪除。 查詢失敗,因為找不到檔案。
- Delta 格式也可能發生此問題。 查詢可能會在重試後成功,因為有新版資料表,而且不會重新查詢刪除的檔案。
- 快取無效的執行計畫。
- 暫時的緩解措施為執行命令
DBCC FREEPROCCACHE。 如果問題持續發生,請建立支援票證。
- 暫時的緩解措施為執行命令
「NOT」附近語法不正確
錯誤 Incorrect syntax near 'NOT' 表示有一些外部資料表的資料行在資料行定義中包含 NOT NULL 條件約束。
- 請更新資料表,從資料行定義中移除 NOT NULL。
- 此錯誤有時也會暫時與從 CETAS 陳述式建立的資料表一同出現。 如果問題未解決,您可以嘗試卸除並重新建立外部資料表。
分割資料行傳回 NULL 值
如果您的查詢傳回 NULL 值,而不是分割資料行或找不到資料分割資料行,則您有幾個可行的疑難排解步驟:
- 如果您使用資料表來查詢分割資料集,請注意資料表不支援資料分割。 以分割的視圖取代資料表。
- 如果您搭配使用已分割視圖與 OPENROWSET,使用 FILEPATH () 函式來查詢已分割檔案,請確認您在位置中正確地指定萬用字元模式,並且使用適當索引來參考萬用字元。
- 如果您直接在分割資料夾中查詢檔案,請注意,資料分割資料行並不是檔案資料行的一部分。 分割值會放在資料夾路徑中,而不是放在檔案中。 基於這個理由,檔案不會包含資料分割值。
針對資料行類型 DATETIME2 插入要批次處理的值失敗
錯誤 Inserting value to batch for column type DATETIME2 failed 表示無伺服器集區無法讀取基礎檔案中的日期值。 儲存在 Parquet 或 Delta Lake 檔案中的日期時間值無法以 DATETIME2 資料行表示。
使用 Spark 檢查檔案中的最小值,並檢查是否有些日期小於 0001-01-03。 如果您使用 Spark 2.4 版 (不支援的執行階段版本) 或仍使用舊版日期時間儲存格式的更新版 Spark 儲存檔案,則之前使用儒略曆 (Julian calendar) 寫入的日期時間值會與無伺服器 SQL 集區中使用的前西曆 (proleptic Gregorian calendar) 不一致。
用來在 Parquet (在某些 Spark 版本中) 寫入值的儒略曆和在無伺服器 SQL 集區使用的西曆 之間,可能會有 2 天的差異。 此差異可能會導致轉換成負值的無效日期值。
請嘗試使用 Spark 來更新這些值,因為這些值會在 SQL 中視為不正確的日期值。 下列範例示範如何在 Delta Lake 中將 SQL 日期範圍以外的值更新為 NULL:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
這項變更會移除無法表示的值。 其他日期值可能已正確載入,但呈現不正確,因為儒略曆和西曆之間仍有差異。 如果您使用的是 Spark 3.0 或較舊版本,則甚至是 1900-01-01 之前的日期也可能會發生非預期的日期移位。
請考慮移轉至 Spark 3.1 或更新版本,然後切換至前西曆。 最新版 Spark 預設使用的前西曆會與無伺服器 SQL 集區中使用的日曆一致。 請以較新的 Spark 版本重新載入舊版資料,並使用下列設定來修正日期:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
查詢失敗,因為拓撲變更或計算容器失敗
此錯誤可能表示在無伺服器 SQL 集區中發生某個內部程序問題。 提出支援票證,包括可協助 Azure 支援團隊調查問題的所有必要詳細資料。
描述與一般工作負載相比後可能屬於異常的任何項目。 例如,可能有大量的並行要求或特殊工作負載或查詢在發生此錯誤之前開始執行。
萬用字元展開逾時
如查詢資料夾和多個檔案一節中所述,無伺服器 SQL 集區支援使用萬用字元讀取多個檔案/資料夾。 每個查詢的最大限制為 10 個萬用字元。 您必須知道使用這項功能有其代價。 無伺服器集區需要時間列出符合萬用字元的所有檔案。 這會導致延遲,而且如果您嘗試查詢的檔案數目很高,此延遲可能會增加。 在此情況下,您可能會遇到下列錯誤:
"Wildcard expansion timed out after X seconds."
您可以執行數個風險降低步驟來避免此錯誤:
- 套用無伺服器 SQL 集區的最佳做法中所述的最佳做法。
- 將檔案壓縮成較大的檔案,以嘗試減少您嘗試查詢的檔案數目。 請嘗試將您的檔案大小保持在 100 MB 以上。
- 確定盡可能在分割資料行上使用篩選。
- 如果您使用差異檔案格式,請使用 Spark 中的最佳化寫入功能。 這可減少需要讀取和處理的資料量,進而提升查詢效能。 在 Apache Spark 上使用最佳化寫入說明如何使用最佳化寫入。
- 若要有效地對分割資料行上的隱含篩選進行硬式編碼來避免某些最上層萬用字元,請使用動態 SQL。
使用自動推斷結構描述時遺漏資料行
您可以透過省略 WITH 子句來輕鬆地查詢檔案,無需了解或指定結構描述。 在此情況下,系統會從檔案推斷資料行名稱和資料類型。 請記住,如果您要一次讀取檔案數目,則會從第一個檔案服務推斷架構從記憶體取得。 這可能表示會省略某些預期的資料行,全部是因為服務用來定義架構的檔案不包含這些資料行。 若要明確指定結構描述,請使用 OPENROWSET WITH 子句。 如果您指定結構描述 (透過使用外部資料表或 OPENROWSET WITH 子句),則會使用預設 lax 路徑模式。 這表示某些檔案中不存在的資料行會以 NULL 傳回 (代表這些檔案的資料列)。 若要了解如何使用路徑模式,請參閱下列文件和範例。
組態
無伺服器 SQL 集區可讓您使用 T-SQL 設定資料庫物件。 有一些限制:
- 您無法在
master和lakehouse或 Spark 資料庫中建立物件 - 您必須擁有主要金鑰才能建立認證。
- 您必須具有參考物件中所用資料的權限。
無法建立資料庫
如果您收到錯誤 CREATE DATABASE failed. User database limit has been already reached.,表示您建立的資料庫數目已達一個工作區可支援的上限。 如需詳細資訊,請參閱條件約束。
- 如果您需要分隔物件,請使用資料庫中的結構描述。
- 如果您需要參考 Azure Data Lake 儲存體,請建立將在無伺服器 SQL 集區中同步的 lakehouse 資料庫或 Spark 資料庫。
建立或改變資料表失敗,因為資料列大小下限超過允許的資料表資料列大小上限 8060 個位元組
任何資料表的每個資料列大小最多可達 8 KB (不包括非資料列 VARCHAR(MAX)/VARBINARY(MAX) 資料)。 如果您建立一個資料表,其中資料列中資料格的總大小超過 8060 個位元組,您會收到下列錯誤:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
如果您所建立 Spark 資料表的資料行大小超過 8060 個位元組,Lake 資料庫中也可能會發生此錯誤,而且無伺服器 SQL 集區無法建立參考 Spark 資料表資料的資料表。
若要降低風險,請避免使用 CHAR(N) 等固定大小類型,並以可變大小 VARCHAR(N) 類型取代之,或減少 CHAR(N) 的大小。 請參閱 SQL Server 中的 8 KB 資料列群組限制。
在資料庫中建立主要金鑰或在工作階段中開啟主要金鑰,然後再執行此操作
如果您的查詢失敗,並出現錯誤訊息 Please create a master key in the database or open the master key in the session before performing this operation.,表示您的使用者資料庫目前無法存取主要金鑰。
最有可能的情況是,您已建立新的使用者資料庫,但尚未建立主要金鑰。
若要解決此問題,請使用下列查詢建立主要金鑰:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
注意
以不同的祕密取代此處的 'strongpasswordhere'。
master 資料庫不支援 CREATE 陳述式
如果您的查詢失敗,並出現錯誤訊息 Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.,表示無伺服器 SQL 集區中的 master 資料庫不支援建立下列項目:
- 外部資料表。
- 外部資料來源。
- 資料庫範圍認證。
- 外部檔案格式。
以下是解決方案:
建立使用者資料庫:
CREATE DATABASE <DATABASE_NAME>在 <DATABASE_NAME> 的內容中執行 CREATE 陳述式 (先前在
master資料庫這麼做會失敗)。以下是建立外部檔案格式的範例:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
無法建立 Microsoft Entra 登入或使用者
如果您嘗試在資料庫中建立新的 Microsoft Entra 登入或使用者時收到錯誤,請檢查您用來連線到資料庫的登入。 嘗試建立新 Microsoft Entra 使用者的登入必須擁有存取 Microsoft Entra 網域的權限,並檢查使用者是否存在。 請注意:
- SQL 登入沒有此權限,因此如果您使用 SQL 驗證,則一律會收到此錯誤。
- 如果您使用 Microsoft Entra 登入來建立新的登入,請檢查您是否有權存取 Microsoft Entra 網域。
Azure Cosmos DB
無伺服器 SQL 集區可讓您使用 OPENROWSET 函式查詢 Azure Cosmos DB 分析儲存體。 請確認您的 Azure Cosmos DB 容器具有分析儲存體。 請確認您已正確地指定帳戶、資料庫和容器名稱。 此外,請確認您的 Azure Cosmos DB 帳戶金鑰有效。 如需詳細資訊,請參閱必要條件。
無法使用 OPENROWSET 函式查詢 Azure Cosmos DB
如果您無法連線到您的 Azure Cosmos DB 帳戶,請參閱必要條件。 下表列出可能的錯誤和疑難排解動作。
| 錯誤 | 根本原因 |
|---|---|
| 語法錯誤: - OPENROWSET 附近的語法不正確。- ... 不是可辨識的 BULK OPENROWSET 提供者選項。- ... 附近的語法不正確。 |
可能的根本原因: - 未使用 Azure Cosmos DB 作為第一個參數。 - 使用字串常值,而不是第三個參數中的識別碼。 - 未指定第三個參數 (容器名稱)。 |
| Azure Cosmos DB 連接字串中發生錯誤。 | - 未指定帳戶、資料庫或金鑰。 - 連接字串中有無法辨識的選項。 - 分號 ( ;) 放置於連接字串的結尾。 |
| 解析 Azure Cosmos DB 路徑失敗,並出現「帳戶名稱不正確」或「資料庫名稱不正確」的錯誤。 | 找不到指定的帳號名稱、資料庫名稱或容器,或者尚未對指定的集合啟用分析儲存體。 |
| 解析 Azure Cosmos DB 路徑失敗,並出現「不正確的秘密值」或「秘密為 Null 或空白」的錯誤。 | 帳戶金鑰無效或遺失。 |
讀取 Azure Cosmos DB 字串類型時,會傳回 UTF-8 定序警告
如果 OPENROWSET 資料行定序沒有 UTF-8 編碼,則無伺服器 SQL 集區會傳回編譯時間警告。 您可以使用下列 T-SQL 陳述式,輕鬆地變更目前資料庫中執行的所有 OPENROWSET 函式預設定序:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
使用字串述詞篩選您的資料時,Latin1_General_100_BIN2_UTF8 定序可提供最佳效能。
Azure Cosmos DB 分析儲存體中有遺漏的資料列
OPENROWSET 函式可能不會傳回 Azure Cosmos DB 中的某些項目。 請注意:
- 交易和分析儲存體之間會存在同步處理延遲。 您在 Azure Cosmos DB 交易儲存體中輸入的文件,可能會在 2 至 3 分鐘後出現在分析儲存體中。
- 文件可能違反某些結構描述條件約束。
查詢會傳回某些 Azure Cosmos DB 項目中的 NULL 值
在下列情況中,Azure Synapse SQL 會傳回 NULL,而不是您在交易儲存體中看到的值:
- 交易和分析儲存體之間會存在同步處理延遲。 您在 Azure Cosmos DB 交易儲存體中輸入的值,可能會在 2 - 3 分鐘後出現在分析儲存體中。
- WITH 子句中可能有錯誤的資料行名稱或路徑運算式。 在 WITH 子句中的資料行名稱 (或資料行類型之後的路徑運算式) 必須符合 Azure Cosmos DB 集合中的屬性名稱。 比較會區分大小寫。 例如,
productCode和ProductCode是不同的屬性。 請確認資料行名稱完全符合 Azure Cosmos DB 的屬性名稱。 - 屬性可能因為違反了某些結構描述條件約束而無法移至分析儲存體,例如超過 1,000 個屬性或超過 127 個巢狀層級。
- 如果您使用明確定義的結構描述表示法,交易儲存體中的值可能會有錯誤的類型。 明確定義的結構描述會藉由取樣文件來鎖定每個屬性的類型。 在交易儲存體中加入的任何不符合類型的值都會視為錯誤的值,而且不會移轉至分析儲存體。
- 如果您使用完全精確度的結構描述表示法,請確認您是在屬性名稱後面加上類型尾碼,例如
$.price.int64。 如果您沒有看到參考路徑的值,則可能會儲存在不同的類型路徑下,例如$.price.float64。 如需詳細資訊,請參閱在完全精確度結構描述中查詢 Azure Cosmos DB 集合。
資料行與外部資料類型不相容
如果 WITH 子句中指定的資料行類型與 Azure Cosmos DB 容器中的類型不符,則會傳回錯誤 Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'.。 請依 Azure Cosmos DB 到 SQL 的類型對應一節中所述,嘗試變更資料行類型,或使用 VARCHAR 類型。
解析:Azure Cosmos DB 路徑失敗並出現錯誤
如果您收到錯誤 Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'.,請檢查您是否在 Azure Cosmos DB 中使用了私人端點。 若要允許無伺服器 SQL 集區存取具有私人端點的分析儲存體,您必須為 Azure Cosmos DB 分析儲存體設定私人端點。
Azure Cosmos DB 效能問題
如果您遇到一些非預期的效能問題,請確認您已套用最佳做法,例如:
- 請確定您已將用戶端應用程式、無伺服器集區和 Azure Cosmos DB 分析儲存體放在相同的區域中。
- 請確認您使用的是具有最佳資料類型的 WITH 子句。
- 使用字串述詞篩選您的資料時,請確認您使用的是 Latin1_General_100_BIN2_UTF8 定序。
- 如果您有可能已快取的重複查詢,請嘗試使用 CETAS 將查詢結果儲存在 Azure Data Lake Storage 中。
Delta Lake
您可能會在無伺服器 SQL 集區的 Delta Lake 支援中遇到一些限制:
- 請確認您參考的是 OPENROWSET 函式或外部資料表位置中的根 Delta Lake 資料夾。
- 根資料夾必須有一個名為
_delta_log的子資料夾。 如果沒有_delta_log資料夾,查詢就會失敗。 如果看不到該資料夾,表示您參考的是純 Parquet 檔案,其必須使用 Apache Spark 集區轉換為 Delta Lake。 - 請勿指定萬用字元用來描述資料分割結構描述。 Delta Lake 查詢會自動識別 Delta Lake 分割。
- 根資料夾必須有一個名為
- 在 Apache Spark 集區中建立的 Delta Lake 資料表會自動在無伺服器 SQL 集區中使用,但結構描述不會更新 (公開預覽限制)。 如果您使用 Spark 集區在 Delta 資料表中新增資料行,則不會在無伺服器 SQL 集區資料庫中顯示變更。
- 外部資料表不支援資料分割。 使用 Delta Lake 資料夾上的分割視圖,以使用分割刪除。 請參閱本文稍後的已知問題和因應措施。
- 無伺服器 SQL 集區不支援時間移動查詢。 使用 Synapse Analytics 中的 Apache Spark 集區來讀取歷程記錄資料。
- 無伺服器 SQL 集區不支援更新 Delta Lake 檔案。 您可以使用無伺服器 SQL 集區來查詢最新版本的 Delta Lake。 使用 Synapse Analytics 中的 Apache Spark 集區來更新 Delta Lake。
- 您無法使用 CETAS 命令,將查詢結果以 Delta Lake 格式儲存到儲存體。 CETAS 命令僅支援 Parquet 和 CSV 作為輸出格式。
- Synapse Analytics 中的無伺服器 SQL 集區與 Delta 讀取器第 1 版相容。
- Synapse Analytics 中的無伺服器 SQL 集區不支援具有 BLOOM 篩選器的資料集。 無伺服器 SQL 集區會忽略 BLOOM 篩選器。
- 專用 SQL 集區無法支援 Delta Lake。 請確定您使用無伺服器 SQL 集區查詢 Delta Lake 檔案。
- 如需無伺服器 SQL 集區已知問題的詳細資訊,請參閱 Azure Synapse Analytics 已知問題。
無伺服器支援 Delta 1.0 版
無伺服器 SQL 集區只會讀取 Delta Lake 1.0 版。 無伺服器 SQL 集區是具有層級 1 的 Delta 讀取器,不支援下列功能:
- 已忽略資料行對應 - 無伺服器 SQL 集區會傳回原始資料行名稱。
- 已忽略刪除向量,並會傳回已刪除/已更新的舊版資料列 (可能是錯誤的結果)。
- 不支援下列 Delta Lake 功能:V2 檢查點、不含時區的時間戳記、VACUUM 通訊協定檢查
已忽略刪除向量
如果您的 Delta Lake 資料表設定為使用 Delta 寫入器第 7 版,則會將已刪除的資料列和已更新的舊版資料列儲存在刪除向量 (DV) 中。 由於無伺服器 SQL 集區具有 Delta 讀取器層級 1,因此在讀取不支援的 Delta Lake 版本時會忽略刪除向量,並可能產生錯誤的結果。
不支援 Delta 資料表中的資料行重新命名
無伺服器 SQL 集區不支援使用已重新命名的資料行來查詢 Delta Lake 資料表。 無伺服器 SQL 集區無法從已重新命名的資料行讀取資料。
Delta 資料表中的資料行值為 NULL
如果您使用需要 Delta 讀取器第 2 版或更新版本的 Delta 資料集,並使用第 1 版不支援的功能 (例如重新命名資料行、卸除資料行或資料行對應),則可能不會顯示參考資料行中的值。
JSON 文字未適當格式化
此錯誤表示無伺服器 SQL 集區無法讀取 Delta Lake 的交易記錄。 您將可能看到下列錯誤:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
請確認您的 Delta Lake 資料集未損毀。 請確認您可以使用 Azure Synapse 中的 Apache Spark 集區讀取 Delta Lake 資料夾的內容。 如此一來,您便可確保 _delta_log 檔案未損毀。
因應措施
嘗試使用 Apache Spark 集區在 Delta Lake 資料集上建立檢查點,然後重新執行查詢。 檢查點將會彙總交易 JSON 記錄檔,且可能會解決此問題。
如果資料集有效,請建立支援票證並提供詳細資訊:
- 請勿進行任何變更,例如新增或移除資料行或最佳化資料表,因為此作業可能會變更 Delta Lake 交易記錄檔的狀態。
- 將
_delta_log資料夾的內容複製到新的空白資料夾。 請勿複製.parquet data檔案。 - 嘗試讀取您在新資料夾中複製的內容,並確認您收到相同的錯誤。
- 將複製的
_delta_log檔案內容傳送至 Azure 支援。
現在您可以搭配 Spark 集區繼續使用 Delta Lake 資料夾。 如果系統允許您共用此資訊,則可將複製的資料提供給 Microsoft 支援服務。 Azure 小組將調查 delta_log 檔案的內容,並提供可能錯誤和因應措施的詳細資訊。
解決差異記錄失敗
下列錯誤表示無伺服器 SQL 集區無法解析 Delta 記錄:Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder.最常見的原因是 _delta_log 資料夾中的 last_checkpoint_file 因為 Spark 3.3 中新增的 checkpointSchema 欄位而大於 200 個位元組。
有兩個選項可用於避開此錯誤:
- 在 Spark 筆記本中修改適當的組態並產生新的檢查點,以便重新建立
last_checkpoint_file。 如果您使用 Azure Databricks,則組態修改如下:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - 降級至 Spark 3.2.1。
我們的工程小組目前正在處理 Spark 3.3 的完整支援。
在 Spark 中建立的 Delta 資料表未在無伺服器集區中顯示
注意
在 Spark 中建立之 Delta 資料表的複寫功能仍處於公開預覽狀態。
如果您在 Spark 中建立 Delta 資料表,而且該資料表未在無伺服器 SQL 集區中顯示,請檢查以下各項:
- 等候一段時間 (通常是 30 秒),因為同步 Spark 資料表出現延遲。
- 如果資料表在一段時間後未出現在無伺服器 SQL 集區中,請檢查 Spark Delta 資料表的結構描述。 無法使用具有複雜類型或無伺服器中不支援類型的 Spark 資料表。 請嘗試在 Lake 資料庫中建立具有相同結構描述的 Spark Parquet 資料表,並檢查該資料表是否會出現在無伺服器 SQL 集區中。
- 檢查工作區受控識別是否可存取資料表所參考的 Delta Lake 資料夾。 無伺服器 SQL 集區會使用工作區受控識別從儲存體取得資料表資料行資訊,以建立資料表。
Lake 資料庫
使用 Spark 或 Synapse 設計工具建立的 Lake 資料庫資料表,將會自動在無伺服器 SQL 集區中提供查詢。 您可以使用無伺服器 SQL 集區來查詢使用 Spark 集區建立的 Parquet、CSV 和 Delta Lake 資料表,並將其他結構描述、檢視表、程序、資料表值函式,以及 db_datareader 角色中的 Microsoft Entra 使用者新增至 Lake 資料庫。 本節會列出可能遇到的問題。
在 Spark 中建立的資料表無法在無伺服器集區中使用
建立的資料表可能無法立即在無伺服器 SQL 集區中使用。
- 資料表需要一些時間才可在無伺服器集區中使用。 在 Spark 中建立資料表之後,可能需要等候 5-10 分鐘,才能在無伺服器 SQL 集區中看到該資料表。
- 只有參考 Parquet、CSV 和 Delta 格式的資料表可在無伺服器 SQL 集區中使用。 無法使用其他資料表類型。
- 包含某些不支援資料行類型的資料表將無法在無伺服器 SQL 集區中使用。
- 存取 Lake 資料庫中的 Delta Lake 資料表目前處於公開預覽階段。 檢查本節或 Delta Lake 區段中所列的其他問題。
在 Spark 中建立的外部資料表在無伺服器集區中顯示非預期的結果
可能是因為來源 Spark 外部資料表與無伺服器集區上複寫的外部資料表不符。 如果用來建立 Spark 外部資料表的檔案沒有副檔名,就可能發生此情況。 若要取得適當的結果,請確定所有檔案都有副檔名 (例如 .parquet)。
作業不適用於複寫的資料庫
如果您嘗試修改 Lake 資料庫、建立外部資料表、外部資料來源、資料庫範圍認證或 Lake 資料庫中的其他物件,就會傳回此錯誤。 這些物件只能在 SQL 資料庫上建立。
Lake 資料庫會複寫自 Apache Spark 集區,並由 Apache Spark 管理。 因此,您無法按照在 SQL Database 中使用 T-SQL 語言的方式建立物件。
Lake 資料庫只允許下列作業:
- 在
dbo以外的結構描述中,建立、卸除或改變檢視、程序和內嵌資料表值函式 (iTVF)。 - 從 Microsoft Entra ID 建立和卸除資料庫使用者。
- 從
db_datareader結構描述新增或移除資料庫使用者。
Lake 資料庫不允許其他作業。
注意
如果您要在 dbo 結構描述中建立檢視、程序或函式 (或省略結構描述,並使用通常為 dbo 的預設結構描述),您將會收到錯誤訊息。
無伺服器 SQL 集區中無法使用 Lake 資料庫中的差異資料表
請確定您的工作區受控識別在包含 Delta 資料夾的 ADLS 儲存體上具有讀取權限。 無伺服器 SQL 集區會從放在 ADLS 中的 Delta 記錄讀取 Delta Lake 資料表結構描述,並使用工作區受控識別來存取 Delta 交易記錄。
請嘗試在一些參考 Azure Data Lake 儲存體的 SQL Database 中使用受控識別認證來設定資料來源,並嘗試使用受控識別根據資料來源建立外部資料表,以確認具有受控識別的資料表可以存取您的儲存體。
Lake 資料庫中的差異資料表在 Spark 和無伺服器集區中沒有相同的結構描述
無伺服器 SQL 集區可讓您存取使用 Spark 或 Synapse 設計工具在 Lake 資料庫中建立的 Parquet、CSV 和 Delta 資料表。 存取 Delta 資料表仍處於公開預覽狀態,目前無伺服器會在建立時同步處理 Delta 資料表與 Spark,但如果稍後在 Spark 中使用 ALTER TABLE 陳述式新增資料行,則不會更新結構描述。
這是公開預覽限制。 請卸除並重新建立 Spark 中的 Delta 資料表 (如果可能),而不是改變資料表來解決此問題。
效能
無伺服器 SQL 集區會根據資料集大小和查詢複雜度,將資源指派給查詢。 您無法變更或限制提供給查詢的資源。 在某些情況下,您可能會遇到非預期的查詢效能降低,您可能必須找出根本原因。
查詢持續時間太長
如果您有查詢持續時間超過 30 分鐘的查詢,查詢將結果傳回給用戶端的速度會過於緩慢。 無伺服器 SQL 集區有 30 分鐘的執行限制。 任何多出的時間都是耗費在結果串流上。 請嘗試下列解決方法:
- 如果您使用 Synapse Studio,請嘗試以其他應用程式 (例如 SQL Server Management Studio 或 Azure Data Studio) 重現問題。
- 如果您在使用 SQL Server Management Studio、Azure Data Studio、Power BI 或某些其他應用程式執行查詢時變慢,請檢查網路問題和最佳做法。
- 將查詢放在 CETAS 命令中,並測量查詢持續時間。 CETAS 命令會將結果儲存至 Azure Data Lake Storage,且不會相依於用戶端連線。 如果 CETAS 命令完成的速度比原始查詢快,請檢查用戶端與無伺服器 SQL 集區之間的網路頻寬。
使用 Synapse Studio 執行查詢的速度很慢
如果您使用 Synapse Studio,請嘗試使用桌面用戶端,例如 SQL Server Management Studio 或 Azure Data Studio。 Synapse Studio 是使用 HTTP 通訊協定連線到無伺服器 SQL 集區的網頁用戶端,通常比 SQL Server Management Studio 或 Azure Data Studio 中使用的原生 SQL 連線慢。
使用應用程式執行時查詢速度很慢
如果您遇到查詢執行緩慢的問題,請檢查下列問題:
- 請確定用戶端應用程式是與無伺服器 SQL 集區端點共置。 跨區域執行查詢可能會造成結果集的額外延遲和串流緩慢。
- 請確認您沒有可能導致結果集串流緩慢的網路問題
- 請確認用戶端應用程式有足夠的資源 (例如,未使用 100% CPU)。
- 請確認儲存體帳戶或 Azure Cosmos DB 分析儲存體位於與無伺服器 SQL 端點相同的區域中。
請參閱共置資源的最佳做法。
查詢持續時間的變化很大
如果您執行相同的查詢並觀察到查詢持續時間上的差異,有幾個原因可能會導致此行為:
- 檢查這是否為第一次執行查詢。 第一次執行查詢時,會收集建立方案所需的統計資料。 統計資料是藉由掃描基礎檔案來收集,而且可能會增加查詢持續時間。 在 Synapse Studio 中,您會在 SQL 要求清單中看到系統先執行「全域統計資料建立」查詢後,才會執行您的查詢。
- 統計資料可能會在一段時間後過期。 您可能會發現,因為無伺服器集區必須定期掃描並重新建立統計資料,而對效能產生影響。 您可能會在 SQL 要求清單中看到系統先執行另一個「全域統計資料建立」查詢後,才會執行您的查詢。
- 在查詢執行持續時間變長時,請檢查相同的端點上是否執行某些工作負載。 無伺服器 SQL 端點會將資源平均配置給平行執行的所有查詢,因此查詢可能會延遲。
連線
無伺服器 SQL 集區可讓您使用 TDS 通訊協定和使用 T-SQL 語言進行連線,以查詢資料。 大部分可連線到 SQL 伺服器或 Azure SQL 資料庫的工具,也可以連線到無伺服器 SQL 集區。
SQL 集區正在準備中
無伺服器 SQL 集區在長時間閒置後會停用。 啟用動作會在接下來的第一個活動時自動發生,例如第一次連線嘗試。 啟用程序所需的時間可能會比單一連線嘗試間隔長,因此會顯示錯誤訊息。 重新嘗試連線應該可以解決此問題。
最佳做法是,對於支援的用戶端,使用 ConnectionRetryCount 和 ConnectRetryInterval 連接字串關鍵字來控制重新連線的行為。
如果錯誤訊息持續發生,請透過 Azure 入口網站提出支援票證。
無法從 Synapse Studio 連線
請參閱 Synapse Studio 區段。
無法從工具連線到 Azure Synapse 集區
某些工具可能沒有讓您用來連線到 Azure Synapse 無伺服器 SQL 集區的明確選項。 請使用要用來連線到 SQL Server 或 SQL 資料庫的選項。 連線對話方塊不需要標示為「Synapse」,因為無伺服器 SQL 集區會使用與 SQL Server 或 SQL Database 相同的通訊協定。
即使工具可讓您只輸入邏輯伺服器名稱和預先定義 database.windows.net 網域,也請在 Azure Synapse 工作區名稱後面加上 -ondemand 尾碼和 database.windows.net 網域。
安全性
請確認使用者具有存取資料庫的權限、執行命令的權限,以及存取 Azure Data Lake 或 Azure Cosmos DB 儲存體的權限。
無法存取 Azure Cosmos DB 帳戶
您必須使用唯讀 Azure Cosmos DB 金鑰來存取分析儲存體,因此請確認其尚未過期或尚未重新產生。
如果您收到「解析 Azure Cosmos DB 路徑失敗並出現錯誤」的錯誤,請確定您已設定防火牆。
無法存取 lakehouse 或 Spark 資料庫
如果使用者無法存取 lakehouse 或 Spark 資料庫,則使用者可能沒有存取和讀取資料庫的權限。 具有 CONTROL SERVER 權限的使用者應該擁有所有資料庫的完整存取權限。 如果權限受限,您可以嘗試使用 CONNECT ANY DATABASE and SELECT ALL USER SECURABLES。
SQL 使用者無法存取 Dataverse 資料表
Dataverse 資料表會使用呼叫端的 Microsoft Entra 身分來存取儲存體。 具有高層級權限的 SQL 使用者可能會嘗試從資料表中選取資料,但資料表無法存取 Dataverse 資料。 不支援此案例。
當 SPI 在建立角色指派時,Microsoft Entra 服務主體登入失敗
如果您想要使用另一個服務主體識別碼 (SPI) 建立 SPI 或 Microsoft Entra 應用程式的角色指派,或者您已建立一個角色指派但無法登入,則您可能會收到下列錯誤:Login error: Login failed for user '<token-identified principal>'.
針對服務主體,您應該使用應用程式識別碼作為安全性識別碼 (SID) 來建立登入,而不是使用物件識別碼。 服務主體具有已知的限制,該限制會導致 Azure Synapse 在另一個 SPI 或應用程式建立角色指派時,無法從 Microsoft Graph 擷取應用程式識別碼。
解決方案 1
請移至 Azure 入口網站>[Synapse Studio]>[管理]>[存取控制],並以手動方式為所需的服務主體新增 Synapse 管理員或 Synapse SQL 管理員。
解決方案 2
您必須使用 SQL 程式碼手動建立適當的登入:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
解決方案 3
您也可以使用 PowerShell 設定服務主體 Azure Synapse 管理員。 您必須安裝 Az.Synapse 模組。
解決方案是使用 Cmdlet New-AzSynapseRoleAssignment 與 -ObjectId "parameter"。 在該參數欄位中,使用工作區管理員 Azure 服務主體認證來提供應用程式識別碼,而不是物件識別碼。
PowerShell 指令碼:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
驗證
連線到無伺服器 SQL 端點,並確認已建立具有 SID (上一個範例中的 app_id_to_add_as_admin) 的外部登入:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
或者,嘗試使用設定的管理員應用程式,在無伺服器 SQL 端點上登入。
限制
某些一般系統條件約束可能會影響您的工作負載:
| 屬性 | 限制 |
|---|---|
| 每個訂用帳戶的 Azure Synapse 工作區數目上限 | 請參閱限制。 |
| 每個無伺服器集區的資料庫數目上限 | 100 (不包括已從 Apache Spark 集區同步的資料庫)。 |
| 已從 Apache Spark 集區同步的資料庫數目上限 | 不受限制。 |
| 每個資料庫的資料庫物件數目上限 | 資料庫中所有物件數的總和不得超過 2,147,483,647。 請參閱 SQL Server 資料庫引擎中的限制。 |
| 最大識別碼長度 (字元數) | 128。請參閱 SQL Server 資料庫引擎中的限制。 |
| 查詢持續時間上限 | 30 分鐘 |
| 結果集的大小上限 | 最多 400 GB (並行查詢之間共用)。 |
| 並行上限 | 沒有限制,視查詢複雜度和掃描的資料量而定。 一個無伺服器 SQL 集區可以同時處理執行輕量型查詢的 1,000 個作用中工作階段。 如果查詢更複雜或掃描大量資料,則數字會下降,因此在這種情況下,請考慮減少並行,並在可能的情況下在更長的時間內執行查詢。 |
| 外部資料表名稱的大小上限 | 100 個字元。 |
無法在無伺服器 SQL 集區中建立資料庫
無伺服器 SQL 集區有限制,而且每個工作區無法建立超過 100 個以上的資料庫。 如果您需要分隔物件並加以隔離,請使用結構描述。
如果您收到錯誤 CREATE DATABASE failed. User database limit has been already reached,表示您建立的資料庫數目已達一個工作區可支援的上限。
您不需要使用個別的資料庫來隔離不同租用戶的資料。 所有資料都會儲存在外部的資料湖和 Azure Cosmos DB。 中繼資料 (例如資料表、視圖、函式定義) 可以使用結構描述成功隔離。 以結構描述為基礎的隔離也會在 Spark 中使用,其資料庫和結構描述的概念相同。
下一步
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應