傳回指定分割區內目前內容的唯一順位,依指定順序排序。 如果找不到相符專案,則rownumber為空白。
語法
ROWNUMBER ( [<relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
參數
| 詞彙 | 定義 |
|---|---|
relation |
(選擇性) 傳回輸出資料列的來源資料表運算式。 如果在視覺計算中使用,此參數會接受視覺圖形中的座標軸。
如果指定, orderBy 和 partitionBy 中的所有數據行都必須來自它。
如果省略:必須明確指定 - orderBy。- 所有 orderBy 和 partitionBy 資料行都必須完整且來自單一數據表。
- 預設為 ALLSELECTED 和 orderBy中的所有數據行 partitionBy()。 |
orderBy |
(選擇性)ORDERBY() 子句,其中包含定義每個分割區排序方式的數據行。
如果省略:必須明確指定 - relation。
- 預設會依尚未在 relation中指定之 partitionBy 中的每個數據行排序。 |
blanks |
(選擇性)列舉,定義排序 relation 或 axis時如何處理空白值。
支援的值為:
注意,當 blanks 函式中的 ORDERBY 參數和空白同時指定個別表達式時, 個別 orderBy 表達式會優先處理相關的 orderBy 表達式,而未指定 blanks 的 orderBy 表達式則會接受父函式上的 blanks 參數。 |
partitionBy |
(選擇性) PARTITIONBY() 子句,其中包含定義分割方式 relation 的數據行。 如果省略,則會將 relation 視為單一分割區。 |
matchBy |
(選擇性) MATCHBY() 子句,其中包含定義如何比對數據及識別目前數據列的數據行。 |
reset |
(選擇性)僅適用於視覺計算。 指出計算是否重設,以及視覺圖形數據行階層的哪個層級。 接受的值包括:目前視覺圖形中數據行的欄位參考、NONE(預設值)、LOWESTPARENT、HIGHESTPARENT或整數。 行為取決於整數符號:- 如果零或省略,則計算不會重設。 相當於 NONE。
- 如果為正數,整數會識別從最高、與粒紋無關的數據行。 HIGHESTPARENT 相當於1。
- 如果為負數,整數會識別從最低開始的數據行,相對於目前的粒紋。 LOWESTPARENT 相當於 -1。 |
傳回值
目前內容的數據列編號。
備註
每個 orderBy、partitionBy和 matchBy 數據行都必須有對應的外部值,以下列行為協助定義要操作的目前數據列:
- 如果只有一個對應的外部數據行,則會使用其值。
- 如果沒有對應的外部資料列,則:
-
ROWNUMBER 會先判斷沒有對應外部數據行的所有
orderBy、partitionBy和matchBy數據行。 - 針對 ROWNUMBER 父內容中這些數據行之現有值的每個組合,會評估 ROWNUMBER 並傳回一個數據列。
- ROWNUMBER的最終輸出是這些數據列的聯集。
-
ROWNUMBER 會先判斷沒有對應外部數據行的所有
- 如果有多個對應的外部數據行,則會傳回錯誤。
如果 matchBy 存在,則 ROWNUMBER 會嘗試使用 matchBy 中的數據行,並 partitionBy 來想出目前的數據列。
如果 orderBy 與 partitionBy 中指定的資料列無法唯一識別 relation中的每個資料列,則:
- ROWNUMBER 會嘗試尋找唯一識別每個數據列所需的最少額外數據行數目。
- 如果可以找到這類數據行,ROWNUMBER 將會
- 嘗試尋找唯一識別每個數據列所需的最少額外數據行數目。
- 自動將這些新數據行附加至
orderBy子句。 - 使用這個新的 orderBy 數據行集來排序每個分割區。
- 如果找不到這類數據行,且函式會在運行時間偵測到系結,則會傳回錯誤。
reset 只能用於視覺計算,而且不能與 orderBy 或 partitionBy搭配使用。 如果 reset 存在,則可以指定 axis,但無法指定 relation。
如果的值 reset 是絕對值(也就是正整數或 HIGHESTPARENT 字段參考),而且計算是在階層中目標層級或高於目標層級進行評估,則計算會針對每個個別元素重設。 也就是說,函式會在只包含該特定元素的數據分割內進行評估。
範例 1 - 計算結果列
下列 DAX 查詢:
EVALUATE
ADDCOLUMNS(
'DimGeography',
"UniqueRank",
ROWNUMBER(
'DimGeography',
ORDERBY(
'DimGeography'[StateProvinceName], desc,
'DimGeography'[City], asc),
PARTITIONBY(
'DimGeography'[EnglishCountryRegionName])))
ORDER BY [EnglishCountryRegionName] asc, [StateProvinceName] desc, [City] asc
傳回數據表,依其 StateProvinceName 和 City,以相同的 EnglishCountryRegionName 來唯一排名每個地理位置。
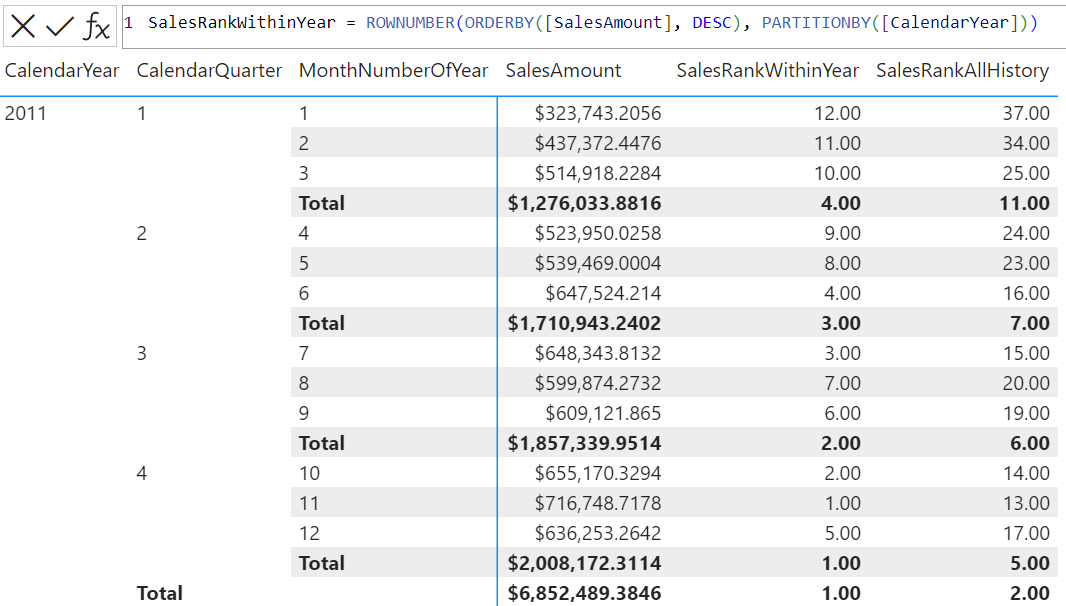
範例 2 - 視覺計算
下列視覺計算 DAX 查詢:
SalesRankWithinYear = ROWNUMBER(ORDERBY([SalesAmount], DESC), PARTITIONBY([CalendarYear]))
SalesRankAllHistory = ROWNUMBER(ORDERBY([SalesAmount], DESC))
建立兩個數據行,依每個月的總銷售額排定每個月,這兩個數據行都是在每年內,以及整個歷程記錄。
下列螢幕快照顯示視覺化矩陣和第一個視覺計算表示式: