學習如何在 ML.NET 中使用預訓練的 ONNX 模型來偵測影像中的物體。
從零開始訓練物件偵測模型需要設定數百萬個參數、大量標註訓練資料,以及龐大的運算資源(數百 GPU 小時)。 使用預訓練模型可以讓你縮短訓練流程。
在本教學課程中,您將瞭解如何:
- 了解問題
- 了解什麼是 ONNX,以及它如何與 ML.NET 互動
- 了解模型
- 重複使用預訓練模型
- 用載入模型偵測物件
先決條件
- Visual Studio 2022 或更高版本。
- Microsoft.ML NuGet 套件
- Microsoft.ML.ImageAnalytics NuGet 套件
- Microsoft.ML.OnnxTransformer NuGet Package
- Tiny YOLOv2 預訓練模型
- Netron (選用)
ONNX 物體偵測範例概述
本範例建立了一個 .NET 核心主控台應用程式,利用預訓練的深度學習 ONNX 模型偵測影像中的物件。 這個範例的程式碼可以在 GitHub 上的 dotnet/machinelearning-samples 倉庫 找到。
什麼是物體偵測?
物體偵測是一種電腦視覺問題。 雖然與影像分類密切相關,物體偵測在更細緻的尺度上進行影像分類。 物體偵測同時定位 並 分類影像中的實體。 物體偵測模型通常利用深度學習與神經網路進行訓練。 更多資訊請參見 深度學習與機器學習 。
當影像包含多個不同類型的物件時,使用物件偵測。

物件偵測的一些應用案例包括:
- 自動駕駛車輛
- 機器人學
- 臉部偵測
- 職場安全
- 物件計數
- 活動識別
選擇深度學習模型
深度學習是機器學習的一個子集。 訓練深度學習模型需要大量資料。 資料中的模式由一系列層次表示。 資料中的關係被編碼為包含權重的層之間的連結。 體重越高,關係就越牢固。 這一系列層次與連結統稱為人工神經網路。 網絡層越多,它就越「深」,成為一個深度神經網路。
神經網路有不同類型,最常見的有多層感知器(MLP)、卷積神經網路(CNN)和循環神經網路(RNN)。 最基本的是MLP,它將一組輸入映射到一組輸出。 當資料沒有空間或時間成分時,這種神經網路是有效的。 CNN 利用卷積層來處理資料中包含的空間資訊。 CNN的一個良好應用是影像處理,用以偵測影像區域中是否有特徵(例如,影像中心是否有鼻子?)。 最後,RNN 允許將狀態或記憶體的持久性用於輸入。 RNN 用於時間序列分析,事件的順序與上下文非常重要。
了解模型
物體偵測是一項影像處理任務。 因此,大多數訓練用來解決此問題的深度學習模型都是卷積神經網絡(CNN)。 本教學中使用的模型是 Tiny YOLOv2 模型,這是 Redmon 和 Farhadi 所著論文《YOLO9000: Better, Faster, Stronger》中描述的 YOLOv2 模型的更精簡版本。 Tiny YOLOv2 是用 Pascal VOC 資料集訓練的,由 15 層組成,能預測 20 種不同類別的物件。 由於 Tiny YOLOv2 是原始 YOLOv2 模型的濃縮版,因此在速度與準確度之間做出了取捨。 組成模型的不同層可以用像 Netron 這類工具來視覺化。 檢視模型會產生神經網路所有層間連結的映射,每層會包含該層名稱及相應輸入/輸出的尺寸。 用來描述模型輸入與輸出的資料結構稱為張量。 張量可被視為儲存 N 維資料的容器。 以 Tiny YOLOv2 為例,輸入層名稱為 image ,且預期張量維度為 3 x 416 x 416。 輸出層的名稱為 grid ,並產生一個維度為 125 x 13 x 13的輸出張量。
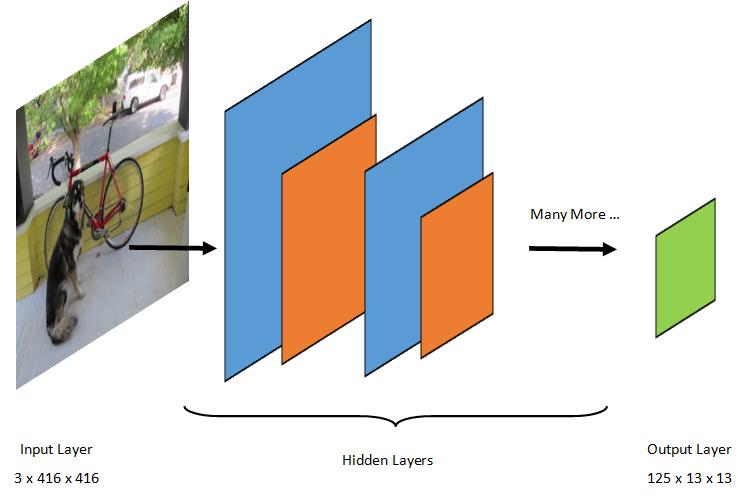
YOLO 模型會拍攝一張影像 3(RGB) x 416px x 416px。 模型會將這些輸入傳遞給不同層次,產生輸出。 輸出將輸入影像分割成 13 x 13 一個格狀,格子中的每個格子由數 125 值組成。
什麼是 ONNX 型號?
開放神經網路交換(ONNX)是一種開源的人工智慧模型格式。 ONNX 支援框架間的互通性。 這表示你可以在許多熱門的機器學習框架(如 PyTorch)中訓練模型,將其轉換成 ONNX 格式,然後在像 ML.NET 這樣的其他框架中使用 ONNX 模型。 欲了解更多,請造訪 ONNX官方網站。

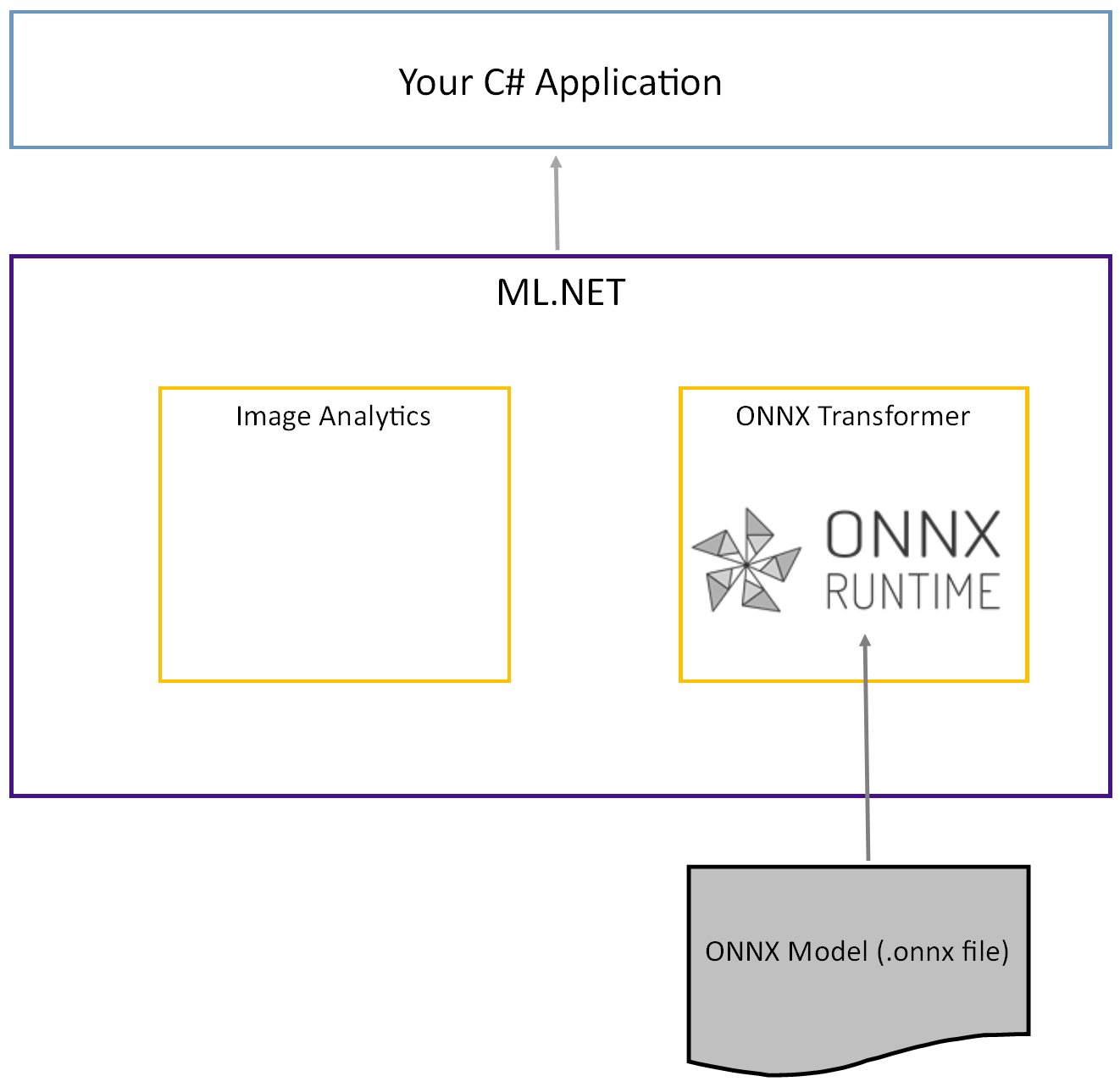
預訓練的 Tiny YOLOv2 模型以 ONNX 格式儲存,這是圖層及所學模式的序列化表示。 在 ML.NET 中,透過 ImageAnalytics 和 OnnxTransformer NuGet 套件實現與 ONNX 的互通性。 該 ImageAnalytics 套件包含一系列轉換,將影像編碼成數值,作為預測或訓練流程的輸入。 該 OnnxTransformer 套件利用 ONNX 執行時載入 ONNX 模型,並根據所提供的輸入進行預測。
設定 .NET 控制台專案
現在你已經大致了解 ONNX 是什麼以及 Tiny YOLOv2 的運作方式,接下來就該開始開發應用程式了。
建立主控台應用程式
建立一個名為「ObjectDetection」的 C# 主控台應用程式 。 按一下 [下一步] 按鈕。
選擇 .NET 8 作為框架。 按下 [建立] 按鈕。
安裝 Microsoft.ML NuGet 套件:
備註
除非另有說明,本範例使用上述 NuGet 套件的最新穩定版本。
- 在解決方案總管中,右鍵點擊您的專案並選擇 「管理 NuGet 套件」。
- 選擇「nuget.org」作為套件來源,選擇瀏覽標籤,搜尋 Microsoft.ML。
- 選取 [安裝] 按鈕。
- 在預覽變更對話框中選擇確定按鈕,若同意上述套件的授權條款,則在授權接受對話框中選擇「我接受」按鈕。
- 重複這些步驟,適用於 Microsoft.Windows.Compatibility、 Microsoft.ML.ImageAnalytics、 Microsoft.ML.OnnxTransformer 和 Microsoft.ML.OnnxRuntime。
準備好你的資料和預訓練模型
下載 Project 資產目錄的壓縮檔 並解壓。
將目錄
assets複製到你的 ObjectDetection 專案目錄中。 這個目錄及其子目錄包含了本教學所需的影像檔(除了 Tiny YOLOv2 模型,你將在下一步下載並新增)。從 ONNX Model Zoo 下載 Tiny YOLOv2 模型。
將檔案複製
model.onnx到你的 ObjectDetection 專案assets\Model目錄,並重新命名為TinyYolo2_model.onnx。 此目錄包含本教學所需的模型。在解決方案總管中,右鍵點擊資產目錄及子目錄中的每個檔案,選擇 屬性。 在 進階中,將 複製到輸出目錄 的值更改為 若較新則複製。
建立類別並定義路徑
打開 Program.cs 檔案,並在檔案頂端新增以下額外 using 指令:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
接著,定義各種資產的路徑。
首先,在
GetAbsolutePath檔案底部建立方法。string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }接著,在指令下方
using建立欄位來儲存資產的位置。var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
在專案中新增一個目錄來儲存輸入資料和預測類別。
在 解決方案總管中,右鍵點擊專案,然後選擇 新增>資料夾。 當新資料夾出現在解決方案總管時,將其命名為「DataStructures」。
在新建立的 DataStructures 目錄中建立你的輸入資料類別。
在 解決方案總管中,右鍵點擊 DataStructures 目錄,然後選擇 新增>項目。
在 新增物品 對話框中,選擇 類別 並將 名稱 欄位改為 ImageNetData.cs。 然後,選取 新增。
ImageNetData.cs檔案會在程式碼編輯器中開啟。 在
using頂部加上以下指令:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;移除現有的類別定義,並將以下類別程式碼
ImageNetData加入 ImageNetData.cs 檔案:public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetData是輸入影像資料類別,並包含以下 String 欄位:-
ImagePath包含影像儲存的路徑。 -
Label包含檔案名稱。
此外,包含
ImageNetData一種ReadFromFile方法,可載入多個儲存在指定路徑中的imageFolder影像檔案,並以物件集合ImageNetData形式回傳。-
在 DataStructures 目錄中建立你的預測類別。
在 解決方案總管中,右鍵點擊 DataStructures 目錄,然後選擇 新增>項目。
在 新增項目 對話框中,選擇 類別 並將 名稱 欄位改為 ImageNetPrediction.cs。 然後,選取 新增。
ImageNetPrediction.cs 檔案會在程式碼編輯器中開啟。 在
using頂部加上以下指令:using Microsoft.ML.Data;移除現有的類別定義,並將以下類別程式碼
ImageNetPrediction加入 ImageNetPrediction.cs 檔案:public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPrediction是預測資料類別,且具有以下float[]欄位:-
PredictedLabels包含影像中偵測到的每個包圍框的維度、物件性分數及類別機率。
-
初始化變數
MLContext 類別是所有 ML.NET 操作的起點,初始化mlContext則會建立一個新的 ML.NET 環境,可在模型建立的工作流程物件間共享。 概念上和 Entity Framework 類似 DBContext 。
在mlContext欄位下方加上以下行,以用新的MLContext實例初始化outputFolder變數。
MLContext mlContext = new MLContext();
建立解析器來後處理模型輸出
模型將影像分割成一個 13 x 13 網格,每個網格為 32px x 32px。 每個格子包含 5 個潛在的物件邊界框。 一個包圍盒包含 25 個元素:
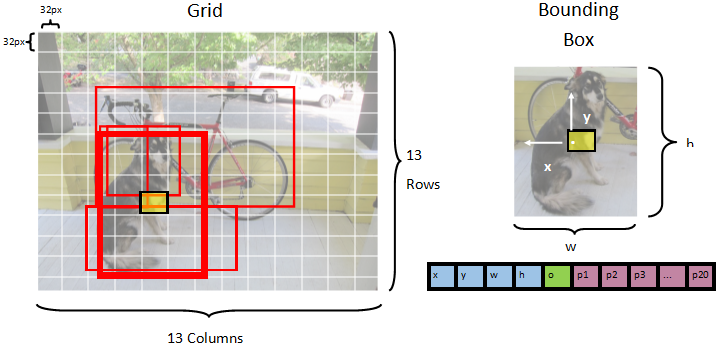
-
x包圍框中心相對於其關聯格子的 x 位置。 -
y也就是包圍盒中心相對於它所關聯格點單元的 y 位置。 -
w邊界框的寬度。 -
h邊界框的高度。 -
o物體存在於包圍框內的信心值,也稱為物體性分數。 -
p1-p20模型預測的20個分類的類別機率。
總計,描述每個 5 個邊界框的 25 個元素組成了每個格子內的 125 個元素。
預訓練 ONNX 模型產生的輸出是一個長度 21125為 的浮點陣列,代表維度為 125 x 13 x 13的張量元素。 為了將模型產生的預測轉換成張量,需要進行一些後處理工作。 為此,建立一組類別來幫助解析輸出。
在你的專案中新增一個目錄來組織解析器類別。
- 在 解決方案總管中,右鍵點擊專案,然後選擇 新增>資料夾。 當新資料夾出現在解決方案總管時,命名為「YoloParser」。
建立邊界框和尺寸
模型輸出的資料包含影像中物件圍界框的座標與尺寸。 建立一個維度的基底類別。
在 解決方案總管中,右鍵點擊 YoloParser 目錄,然後選擇 新增>項目。
在 新增項目 對話框中,選擇 類別 並將 名稱 欄位改為 DimensionsBase.cs。 然後,選取 新增。
DimensionsBase.cs 檔案會在程式碼編輯器中開啟。 移除所有
using指令和現有的類別定義。將以下類別程式碼
DimensionsBase加入 DimensionsBase.cs 檔案:public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBase具有以下float性質:-
X包含物體沿 x 軸的位置。 -
Y包含物體沿 y 軸的位置。 -
Height包含物體的高度。 -
Width包含物件的寬度。
-
接著,為你的邊界框建立一個類別。
在 解決方案總管中,右鍵點擊 YoloParser 目錄,然後選擇 新增>項目。
在 新增項目 對話框中,選擇 類別 並將 名稱 欄位改為 YoloBoundingBox.cs。 然後,選取 新增。
YoloBoundingBox.cs 檔案會在程式碼編輯器中開啟。 在
using頂部加上以下指令:using System.Drawing;在現有類別定義之上,新增一個稱為
BoundingBoxDimensions的類別定義,該類別繼承自DimensionsBase類別,以包含相應邊界框的維度。public class BoundingBoxDimensions : DimensionsBase { }移除現有
YoloBoundingBox的類別定義,並將以下類別程式碼YoloBoundingBox加入 YoloBoundingBox.cs 檔案:public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBox具有下列屬性:-
Dimensions包含包圍盒的尺寸。 -
Label包含在包圍框內偵測到的物件類別。 -
Confidence包含班級的信心。 -
Rect包含包圍盒尺寸的矩形表示。 -
BoxColor包含與繪圖所用類別相關的顏色。
-
建立解析器
現在維度和邊界框的類別已經建立好,接下來是建立解析器的時候了。
在 解決方案總管中,右鍵點擊 YoloParser 目錄,然後選擇 新增>項目。
在 新增項目 對話框中,選擇 類別 並將 名稱 欄位改為 YoloOutputParser.cs。 然後,選取 新增。
YoloOutputParser.cs檔案會在程式碼編輯器中開啟。 在
using頂部新增以下指令:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;在現有
YoloOutputParser的類別定義中,加入一個巢狀類別,包含影像中每個儲存格的維度。 在CellDimensions類別定義的頂部加入從DimensionsBase類別繼承的YoloOutputParser類別的程式碼。class CellDimensions : DimensionsBase { }在類別定義中
YoloOutputParser,加入以下常數與域。public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNT是影像被劃分到格子中的行數。 -
COL_COUNT是影像被劃分成的格子中的欄位數。 -
CHANNEL_COUNT是網格中一個格子所包含的數值總數。 -
BOXES_PER_CELL是儲存格中包圍盒的數量, -
BOX_INFO_FEATURE_COUNT是包含在一個框內的特徵數量(x、y、高度、寬度、信心度)。 -
CLASS_COUNT是每個包圍框中包含的類別預測數量。 -
CELL_WIDTH是影像格中一個格子的寬度。 -
CELL_HEIGHT是影像格子中一個格子的高度。 -
channelStride是當前格子在網格中的起始位置。
當模型做出預測(也稱為評分)時,會將
416px x 416px輸入影像分割成大小為13 x 13的格子網格。 每個儲存格包含 。32px x 32px每個格子內有 5 個邊界框,每個框包含 5 個特徵(x、y、寬度、高度、置信度)。 此外,每個包圍框包含每個類別的機率,在此例中為 20。 因此,每個儲存格包含125個資訊(5個特徵+20個類別機率)。-
以下是所有五個邊界框在 channelStride 之下的錨點清單:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
錨點是預先定義的邊界框的高度與寬度比率。 大多數模型偵測到的物件或類別的比率相似。 這在建立邊界框時非常有用。 與其預測邊界盒,不如計算與預定維度的偏移量,從而減少預測邊界盒所需的計算量。 通常這些錨定比率是根據所用資料集計算的。 在這種情況下,因為資料集已知且數值已預先計算,錨點可以被硬編碼。
接著,定義模型將預測的標籤或類別。 此模型預測 20 個類別,這是原始 YOLOv2 模型預測類別總數的子集。
請將你的標籤列表添加在 anchors 下面。
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
每個職業都有相應的顏色。 請在你的 labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
建立輔助函式
後處理階段包含一系列步驟。 為了幫助這點,可以採用多種輔助方法。
解析器所使用的輔助方法包括:
-
Sigmoid套用 S形體函數,輸出介於 0 到 1 之間的數字。 -
Softmax將輸入向量正規化為機率分布。 -
GetOffset將一維模型輸出中的元素映射到125 x 13 x 13張量中對應的位置。 -
ExtractBoundingBoxes利用此GetOffset方法從模型輸出中提取包圍盒的尺寸。 -
GetConfidence提取模型偵測到物體的信心值,並利用Sigmoid函數將其轉換為百分比。 -
MapBoundingBoxToCell使用包圍盒的尺寸,並將其映射到影像中相應的格子上。 -
ExtractClasses使用GetOffset方法從模型輸出中提取界框的類別預測,並使用Softmax方法將其轉換為機率分布。 -
GetTopResult從預測類別列表中選擇機率最高的類別。 -
IntersectionOverUnion篩選器以較低機率重疊的邊界框。
在你的 清單 classColors下方加入所有輔助方法的程式碼。
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
當你定義好所有輔助方法後,就可以用它們來處理模型輸出。
在方法下方 IntersectionOverUnion ,建立 ParseOutputs 處理模型產生輸出的方法。
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
建立一個清單來存放你的邊界框,並在方法 ParseOutputs 中定義變數。
var boxes = new List<YoloBoundingBox>();
每張影像被劃分為 13 x 13 個網格。 每個單元包含五個邊界框。 在變數下方 boxes ,加入處理每個儲存格所有方塊的程式碼。
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
在最內層迴圈內,計算當前方框在一維模型輸出中的起始位置。
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
就在那個位置,使用該 ExtractBoundingBoxDimensions 方法取得目前包圍框的尺寸。
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
然後,使用該 GetConfidence 方法取得當前邊界框的信心值。
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
接著,使用該 MapBoundingBoxToCell 方法將當前邊界框映射到正在處理的格子。
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
在進一步處理前,請檢查你的信心值是否超過所提供的門檻。 如果沒有,就處理下一個邊界框。
if (confidence < threshold)
continue;
否則,繼續處理輸出。 下一步是利用該 ExtractClasses 方法取得當前邊界盒預測類別的機率分布。
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
接著,使用該 GetTopResult 方法取得目前該盒子中機率最高的類別的值與索引,並計算其分數。
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
再次使用該 , topScore 只保留超過指定閾值的邊界框。
if (topScore < threshold)
continue;
最後,如果目前的邊界框超過閾值,請建立一個新 BoundingBox 物件並將其加入 boxes 清單。
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
當影像中所有儲存格都處理完畢後,回傳清單 boxes 。 在方法 ParseOutputs 的最外層 for 迴圈下方加入以下的 return 陳述。
return boxes;
濾波器重疊盒
現在,所有具有高置信度的邊界框都已從模型輸出中提取出來,接下來需要進行額外的過濾,以移除重疊的框。 請加入一個稱為 FilterBoundingBoxes 該 ParseOutputs 方法的方法:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
在方法 FilterBoundingBoxes 內,先建立一個等於偵測到的方框大小的陣列,並將所有槽位標記為啟用或準備處理。
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
接著,依據置信度以遞減的順序排序包含你邊界框的清單。
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
接著建立一個清單來存放篩選過的結果。
var results = new List<YoloBoundingBox>();
開始處理每個包圍框,逐個遍歷。
for (int i = 0; i < boxes.Count; i++)
{
}
在這個 for 迴圈內,檢查目前的邊界框是否可以被處理。
if (isActiveBoxes[i])
{
}
如果是這樣,將邊界框加入結果清單。 若結果超過需擷取的框數限制,則跳出迴圈。 在 if 陳述式中加入以下程式碼。
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
否則,請查看相鄰的邊界框。 在框框限制勾選下方加入以下代碼。
for (var j = i + 1; j < boxes.Count; j++)
{
}
與第一個方框相同,若相鄰方格處於啟用狀態或準備處理,請使用此 IntersectionOverUnion 方法檢查第一方格與第二方格是否超過指定閾值。 將以下程式碼加入你最內在的 for loop。
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
在檢查相鄰邊界框的最內層 for 迴圈之外,查看是否有任何剩餘的邊界框需要處理。 如果沒有,就跳出外圈。
if (activeCount <= 0)
break;
最後,在方法初始的 for 迴圈 FilterBoundingBoxes 之外,回傳結果:
return results;
太棒了! 現在是時候用這段程式碼和模型來評分了。
使用模型來評分
就像後製一樣,評分過程有幾個步驟。 為了幫助你,可以新增一個類別,將計分邏輯納入你的專案中。
在 解決方案總管中,右鍵點擊專案,然後選擇 新增>項目。
在 新增項目 對話框中,選擇 類別 並將 名稱 欄位改為 OnnxModelScorer.cs。 然後,選取 新增。
OnnxModelScorer.cs檔案會在程式碼編輯器中開啟。 請在
using頂部新增以下指示:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;在類別定義中
OnnxModelScorer,加入以下變數。private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();在其下方,撰寫一個
OnnxModelScorer類別的建構子,用來初始化先前定義的變數。public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }建立建構子後,定義幾個結構體,裡面包含與影像和模型設定相關的變數。 建構一個名為
ImageNetSettings的結構體,以包含模型預期的高度與寬度。public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }接著,建立另一個結構
TinyYoloModelSettings體,包含模型輸入層與輸出層的名稱。 要視覺化模型輸入層和輸出層的名稱,可以使用像 Netron 這樣的工具。public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }接著,建立第一組用於評分的方法。 在你的
LoadModel課堂內建立OnnxModelScorer方法。private ITransformer LoadModel(string modelLocation) { }在方法
LoadModel內,加入以下記錄程式碼。Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET 管線需要在呼叫
Fit方法時,知道要操作的資料模式。 此時將採用類似訓練的流程。 然而,由於沒有實際訓練,使用空IDataView的 是可以接受的。 從空清單建立一個新的IDataView管線。var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());再往下定義流程。 管線將包含四個轉換段。
-
LoadImages將影像載入為點陣圖。 -
ResizeImages將影像重新縮放到指定的大小(此例為416 x 416)。 -
ExtractPixels將影像的像素表示從位圖轉換為數值向量。 -
ApplyOnnxModel載入 ONNX 模型,並用它來評分所提供的資料。
這很重要
只套用可信來源的模型。 套用來自不受信任來源的模型會帶來安全風險。
請在
LoadModel變數下方data的方法中定義你的管線。var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));現在是時候實例化這個模型來計分了。 在管線中呼叫該
Fit方法並回傳以便進一步處理。var model = pipeline.Fit(data); return model;-
模型載入後,即可用於進行預測。 為了促進這個過程,請建立一個稱為 PredictDataUsingModel 方法下方 LoadModel 的方法。
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
在 PredictDataUsingModel內,加入以下記錄程式碼。
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
然後,使用該 Transform 方法對資料進行評分。
IDataView scoredData = model.Transform(testData);
提取預測機率並返回進行後續處理。
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
現在兩個步驟都已設定好,將它們合併成一個方法。 在該 PredictDataUsingModel 方法下方,新增一個稱為 Score的方法。
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
快到了! 現在是時候把這些全部發揮到大作用了。
偵測物體
現在所有設置都完成了,是時候偵測一些物體了。
評分與解析模型的輸出結果
在變數建立 mlContext 後,加入 try-catch 陳述句。
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
在區 try 塊內部開始實作物件偵測邏輯。 首先,將資料載入 IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
接著,建立一個實例 OnnxModelScorer ,用它來評分載入的資料。
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
現在是後製階段。 建立一個實 YoloOutputParser 例,並用它來處理模型輸出。
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
模型輸出處理完成後,就可以在影像上繪製邊界框。
將預測視覺化
模型評分完畢且輸出處理完畢後,必須在影像上繪製包圍框。 為此,請在DrawBoundingBox 中的方法下方GetAbsolutePath加入一個稱為的方法。
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
首先,載入影像,取得方法中的 DrawBoundingBox 高度和寬度尺寸。
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
接著,建立一個 for-each 迴圈,遍歷模型偵測到的每個邊界框。
foreach (var box in filteredBoundingBoxes)
{
}
在 foreach 迴圈內,取得包圍框的尺寸。
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
由於包圍盒的尺寸對應於模型輸入 416 x 416,將包圍盒尺寸縮放至與影像實際大小相符。
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
接著,為每個邊界框的上方文字定義一個範本。 該文本將包含物件在對應邊界框內的類別以及置信度。
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
要在圖像上作畫,先將其轉換成物件 Graphics 。
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
在using程式碼區塊內,調整圖形的Graphics物件設定。
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
再往下設定文字和邊界框的字體和顏色選項。
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
使用FillRectangle方法,在邊界框上方建立一個矩形並填滿,以容納文字。 這有助於讓文字對比並提升可讀性。
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
接著,用 DrawString and DrawRectangle 方法在圖片上畫出文字和邊界框。
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
在 for-each 迴圈之外,新增程式碼將圖片儲存在 outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
為了獲得應用程式執行時預測的額外回饋,可以在LogDetectedObjects檔案中DrawBoundingBox新增一個稱為該方法的方法,將偵測到的物件輸出到主控台。
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
現在你有了輔助方法可以從預測中產生視覺回饋,然後加入一個 for-loop,讓每張評分的圖片都被反覆運算。
for (var i = 0; i < images.Count(); i++)
{
}
在 for 迴圈裡面,取得圖片檔案的名稱以及與其相關的邊界框。
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
然後使用 DrawBoundingBox 方法在圖片上畫出邊界框。
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
最後,使用該 LogDetectedObjects 方法將預測輸出到主控台。
LogDetectedObjects(imageFileName, detectedObjects);
在 try-catch 陳述句後,加入額外邏輯表示程序已停止執行。
Console.WriteLine("========= End of Process..Hit any Key ========");
就是這樣!
Results
按照前面步驟操作後,執行你的主控台應用程式(Ctrl + F5)。 你的結果應該會和以下輸出類似。 您可能會看到警告或處理訊息,但這些訊息已從以下結果中移除,以求清晰。
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
要查看帶有邊界框的圖片,請前往 assets/images/output/ 目錄。 以下是其中一張處理過的影像範例。

祝賀! 你現在成功地透過重用預訓練 ONNX 模型在 ML.NET 中建立了一個物體偵測的機器學習模型。
你可以在 dotnet/machinelearning-samples 資料庫找到這個教學的原始碼。
在本教程中,您將學到如何:
- 了解問題
- 了解什麼是 ONNX,以及它如何與 ML.NET 互動
- 了解模型
- 重複使用預訓練模型
- 用載入模型偵測物件
請參考 機器學習 範例 GitHub 倉庫,探索擴展的物件偵測範例。