適用於:✅Microsoft Fabric 的資料工程和資料科學
當您從 Azure 入口網站建立 Microsoft Fabric 時,它會自動新增至與用來創建容量的訂用帳戶相關聯的 Fabric 租戶。 透過 Microsoft Fabric 中的簡化設定,不需要將容量連結至 Fabric 租用戶。 因為新建立的容量將會列在 [管理員設定] 窗格中。 此組態可讓管理員更快速地開始設定其企業分析小組的容量。
若要變更容量中的「資料工程/科學設定」,您必須具有該容量的管理員角色。 若要深入了解可以在容量中指派給使用者的角色,請參閱<容量中的角色>。
使用下列步驟來管理 Microsoft Fabric 容量的 [資料工程師/科學設定]:
選取 [設定] 選項,開啟 Fabric 帳戶的設定窗格。 選取 [治理與深入解析] 區段下的 管理入口網站。
![螢幕擷取畫面,其中顯示選取 [管理入口網站] 設定的位置。](media/capacity-settings-management/admin-portal.png)
選擇 [ 容量設定 ] 選項以展開功能表,然後選取 [ 網狀架構容量 ] 索引標籤。在這裡,您應該會看到您在租使用者中建立的容量。 選擇要設定的容量。
![顯示選取 [容量設定的位置] 的螢幕快照。](media/capacity-settings-management/capacity-settings.png)
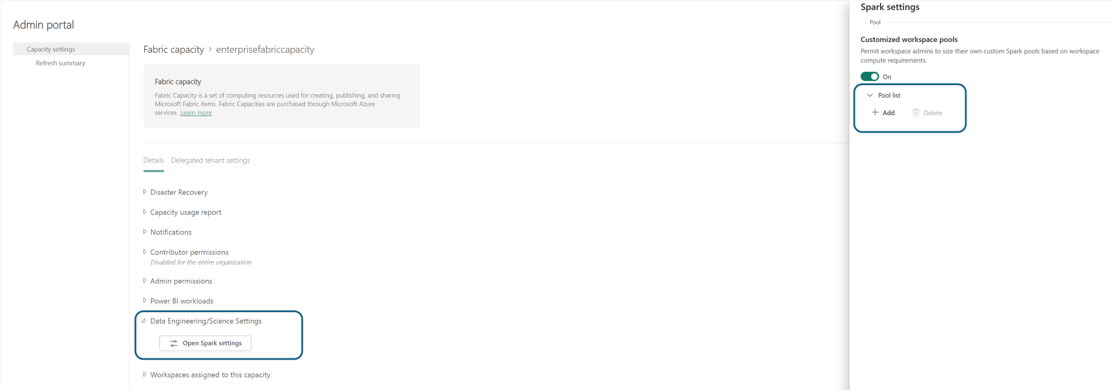
您瀏覽至容量詳細資料窗格,您可以在其中檢視容量的使用方式和其他系統管理控制項。 瀏覽至 [資料工程師/科學設定] 區段,然後選取 [開啟 Spark 計算]。 設定下列參數:
注意
至少應連結一個工作區至 Fabric Capacity,以便從 Fabric Capacity 管理入口網站探索數據工程/科學設定。
管理員控制:停用入門集區
容量管理員現在可以選擇在連結至容量的工作區之間 停用入門集區使用量 。 停用時,使用者和工作區系統管理員將不再將入門集區視為計算選項。 相反地,他們必須使用由容量管理員明確建立和管理的自定義集區。
此功能提供計算使用量的集中式治理,確保更嚴格地控制計算大小、成本和排程行為。
小提示
此設定特別適用於想要標準化計算模式的大型組織,並避免透過預設入門集區任意取用。
系統管理控制:作業層級爆發性開關
Microsoft Fabric 支援 Spark VCores 的 3×突增,讓單一作業可暫時使用比基底容量更多的計算核心。 這可藉由允許完整容量使用率,改善活動高載期間的作業效能。
身為容量管理員,您現在可以使用系統管理入口網站中提供的 「停用作業層級高載」 參數來控制此行為:
位置:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark Compute行為:
- 已啟用 (預設值):單一Spark作業可以取用完整的高載限制(最多3×Spark虛擬核心)。
- 停用狀態:個別 Spark 作業會限制在基底容量分配,保持並行處理並防止壟斷。
注意
只有在 Fabric 容量上執行 Spark 作業時才能使用此開關。 如果已啟用 自動調整計費 選項,則會自動停用此參數,因為:
- 自動調整計費遵循 純隨用隨付模型。
- 沒有平滑視窗可允許使用量高載,並在24小時內加以平衡。
- 高載是保留容量的功能,而不是隨選自動調整計算。
使用案例和範例
| 情境 | 設定 | 行為 |
|---|---|---|
| 繁重的 ETL 工作負載 | 突發功能已啟用(預設值) | 作業可以使用整個突發容量(例如 F64 中的 384 個 Spark VCores)。 |
| 多使用者互動式筆記本 | 已停用高載 | 作業使用限制 (例如 F64 中的 128 個 Spark VCore),可以提升並行能力。 |
| 自動調整計費已啟用 | 爆裂控制 無法使用 | 所有 Spark 用量都依需求計費;不會超出基本容量使用。 |
小提示
使用此開關來 優化輸送量或並行處理:
- 保持大型作業和管線的突發功能啟用。
- 在具有許多使用者的互動式或共用環境中停用它。
Microsoft Fabric 中適用於數據工程和數據科學的容量集區
在Spark設定的 [ 集區清單 ] 區段中,按兩下 [ 新增 ] 以建立網狀架構容量的 自定義集 區。
您已導航至集區建立頁面,您可以在此進行以下操作:
- 指定 集區名稱
- 選取 [節點系列 ] 和 [ 節點大小]
- 設定 最小和最大節點
- 啟用/停用 執行程序自動調整 和 動態配置
![螢幕擷取畫面,其中顯示 [管理入口網站] 設定中的 [集區建立] 區段。](media/capacity-settings-management/capacity-pools-creation.png)
選取 [建立] 以儲存您的設定。
![螢幕擷取畫面,其中顯示儲存在 [管理入口網站] 設定中的容量池。](media/capacity-settings-management/capacity-settings-pool-creation.png)

注意
容量層級自定義集區的啟動延遲為 2-3 分鐘。 如需更快速的 Spark 工作階段啟動 (<5 秒),請在啟用時使用入門集區。
建立之後,容量池就可供下列專案使用:
- 工作區設定中的 [ 資源池選擇 ] 下拉式清單
- 工作區中的 [環境計算設定 ] 頁面
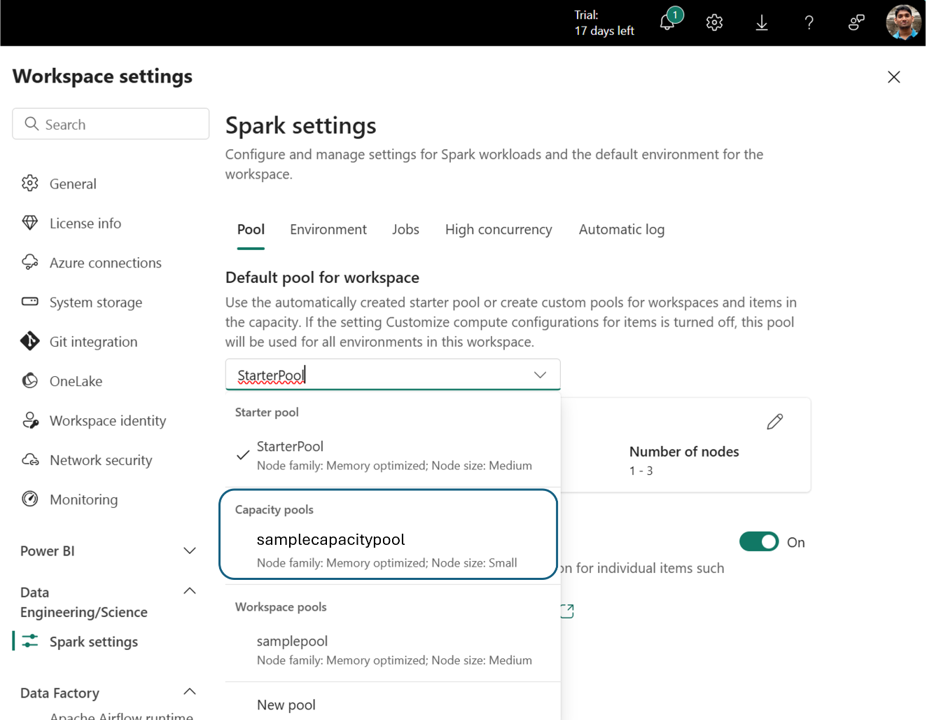
![顯示 [環境設定] 中所列容量集區的螢幕快照。](media/capacity-settings-management/capacity-pools-environment-compute-options.png)
這可啟用集中式計算控管。 系統管理員可以建立標準化的集區,並選擇性地 停用工作區層級自定義,防止工作區中的系統管理員修改集區設定或建立自己的集區。