本文說明如何在 Microsoft Fabric 中為您的分析工作負載建立自訂 Apache Spark 集區。 Apache Spark 集區可讓您根據需求建立量身打造的運算環境,從而獲得最佳效能和資源使用。
指定自動調整的最小和最大節點。 系統會隨著任務的運算需求變更而取得和淘汰節點,因此擴展效率高且效能改善。 Spark 集區會自動調整執行程式的數目,因此您不需要手動設定它們。 系統會根據資料量和任務運算需求變更執行程式計數,因此您可以專注於工作負載,而不是效能調整和資源管理。
小提示
當您設定 Spark 集區時,節點大小是由 容量單位 (CU) 決定,代表指派給每個節點的計算容量。 如需節點大小和CU的詳細資訊、請參閱本指南中的 節點大小選項 一節。
先決條件
若要建立自訂 Spark 集區,請確定您具有工作區的系統管理員存取權。 容量管理員會在容量管理員設定的 Spark 計算區段中啟用自訂工作區集區選項。 如需詳細資訊,請參閱 網狀架構容量的 Spark 計算設定。
建立自定義Spark集區
若要建立或管理與您的工作區相關聯的 Spark 集區:
移至您的工作區,然後選取 [ 工作區設定]。
選取 [資料工程/科學] 選項以展開功能表,然後選取 [Spark 設定]。

選取 [ 新增集區] 選項。 在 [ 建立集區] 畫面中,為您的Spark集區命名。 此外,選擇 [節點系列],並根據工作負載的計算需求,從可用的大小 (Small、Medium、Large、X-Large 和 XX-Large) 中選取節點大小。
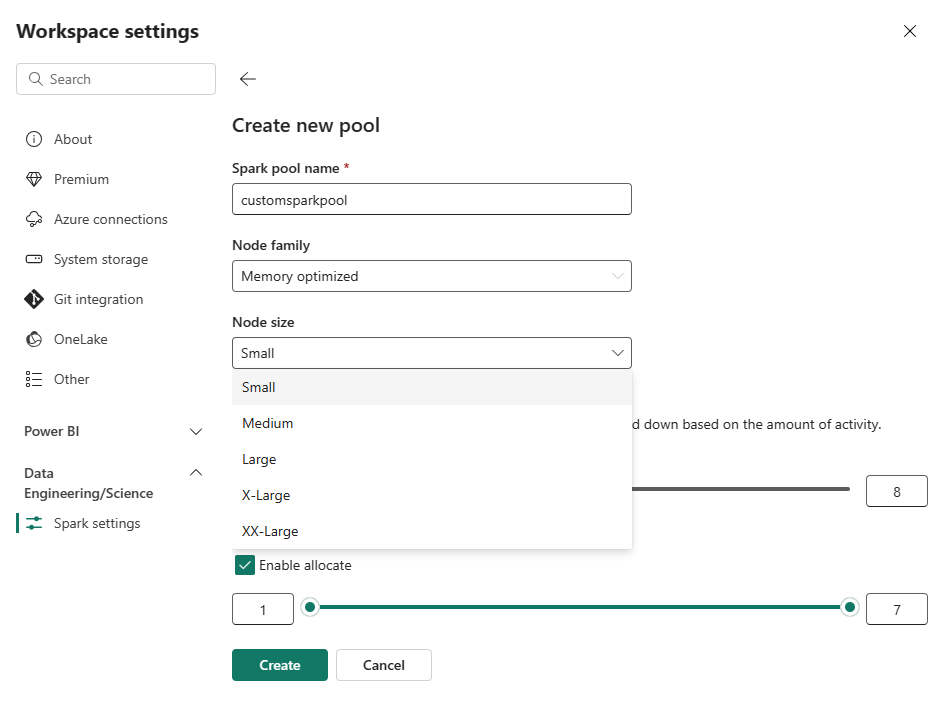
您可以將自訂集區的最小節點組態設為 1。 因為 Fabric Spark 為具有單一節點的叢集提供可復原的可用性,因此您不必擔心作業失敗、在失敗期間遺失會話,或針對較小的 Spark 作業過度支付計算資源的費用。
您可以啟用或停用自訂 Spark 集區的自動調整(autoscaling)。 啟用自動調整時,集區會以動態方式取得新的節點,以達到使用者指定的最大節點限制,然後在作業執行后淘汰它們。 此功能會根據作業需求調整資源,以確保更好的效能。 您可以調整節點的大小,以符合在網狀架構容量 SKU 中購買的容量單位。
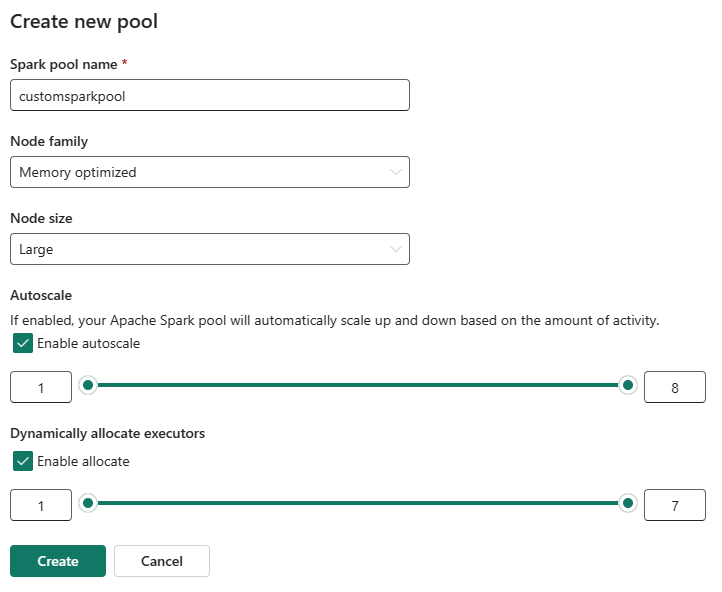
您可以使用滑桿來調整執行程序的數目。 每個執行程式都是一個 Spark 進程,它會執行工作,並將數據存放在記憶體中。 增加執行程式可以改善平行處理原則,但也會增加叢集的大小和啟動時間。 您也可以選擇為 Spark 集區啟用動態執行程式配置,這會自動決定使用者指定上限內的最佳執行程式數目。 這項功能會根據數據量調整執行程式數目,進而改善效能和資源使用率。



這些自訂集區的預設自動暫停持續時間為閒置期間到期後 2 分鐘。 達到自動暫停持續時間之後,會話將過期,叢集將被釋放。 系統會根據使用自定義 Spark 集區的節點數目和持續時間,向您收取費用。
備註
Microsoft Fabric 中的自訂 Spark 集區目前支援 200 個節點上限。 設定自動調整或設定手動節點計數時,請確定您的最小值和最大值保持在此限制內。 超過此限制會導致在集區建立或更新期間發生驗證錯誤。
節點大小選項
當您設定自訂 Spark 集區時,您可以從下列節點大小中進行選擇:
| 節點大小 | 容量單位(CU) | 記憶體 (GB) | 說明 |
|---|---|---|---|
| 小 | 4 | 32 | 適用於輕量級開發和測試工作。 |
| 中等 | 8 | 64 | 適用於一般工作負載和一般作業。 |
| 大型 | 16 | 128 | 適用於記憶體密集型工作或大型資料處理作業。 |
| X-Large | 32 | 256 | 適用於需要大量資源的最嚴苛的 Spark 工作負載。 |
備註
Microsoft Fabric Spark 集區中的容量單位 (CU) 代表指派給每個節點的計算容量,而不是實際耗用量。 容量單位與 VCore (虛擬核心) 不同,VCore (虛擬核心) 用於 SQL 型 Azure 資源。 CU 是 Fabric 中 Spark 集區的標準術語,而 VCore 則更常見於 SQL 集區。 調整節點大小時,請使用 CU 來判斷 Spark 工作負載的指派容量。
相關內容
- 若要深入了解,請參閱 Apache Spark 公開文件。
- 開始使用 Microsoft Fabric 中的 Spark 工作區系統管理設定。