Microsoft Fabric 資料工程師和資料科學體驗可在完全受控的 Spark 計算平台上運作。 此平台的旨在提供一流的速度和效率。 其中包含入門集區和自訂集區。
Fabric 環境包含組態集合,包括 Spark 計算屬性,您可以在將 Spark 會話附加至筆記本和 Spark 作業之後,用來設定 Spark 工作階段。 透過環境,可以使用彈性方式來自訂執行 Spark 工作的計算組態。
設定參數
身為工作區系統管理員,您可以啟用或停用計算自定義。
在 [ 工作區設定] 窗格中,選取 [數據工程/科學 ] 區段。
在 [集區] 索引標籤上,將 自訂項目計算配置 切換為 開啟。
您也可以啟用此設定,委派成員和參與者,以變更 Fabric 環境中的預設會話層級計算組態。
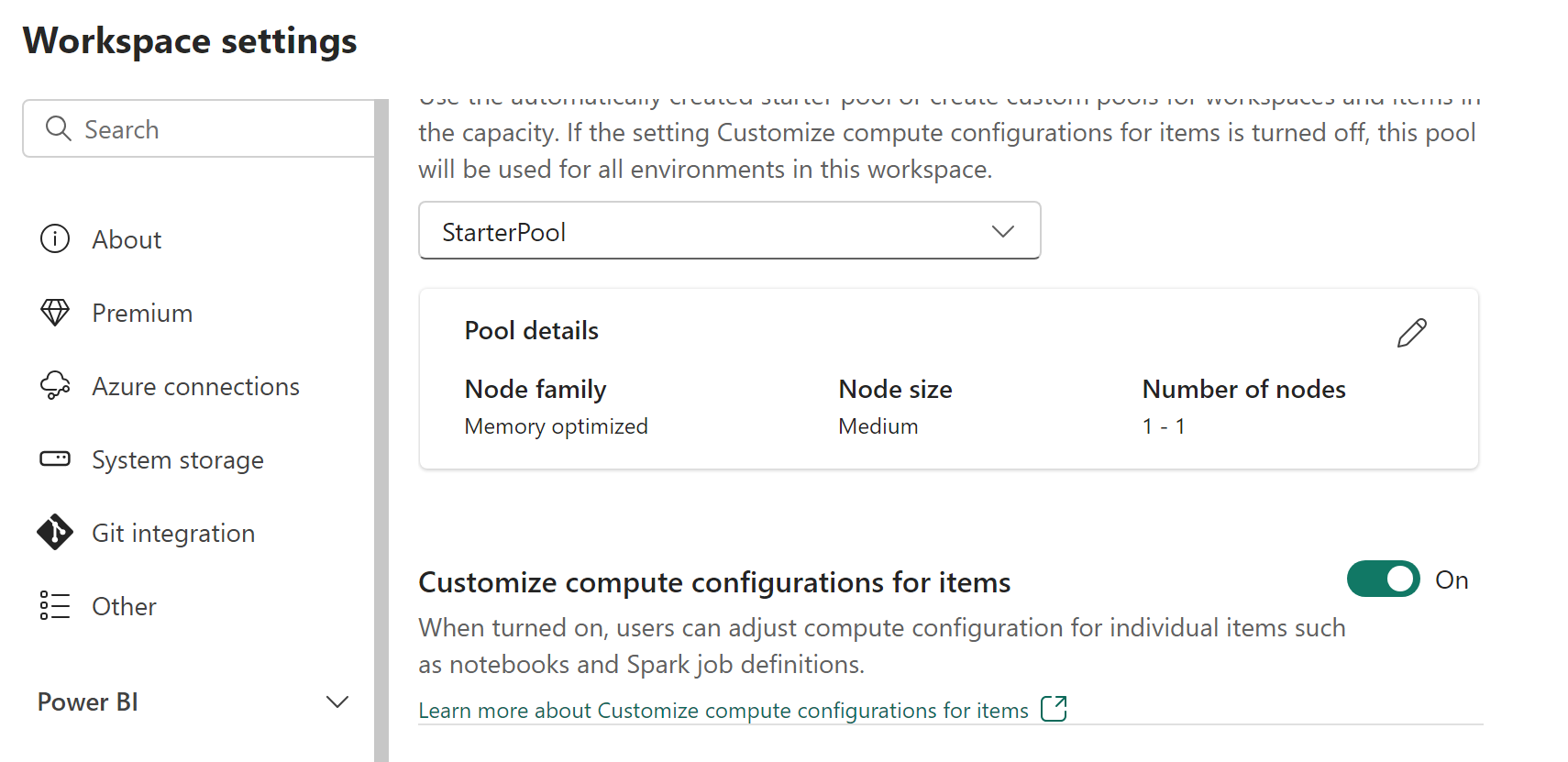
如果您在 [ 工作區設定 ] 窗格上停用此選項,則會停用環境的 [計算 ] 區段。 工作區的預設集區計算組態會用於執行 Spark 作業。

自定義環境中的會話層級計算屬性
作為使用者,您可以從 Fabric 工作區內可用的集區清單中選擇一個集區以用於環境。 Fabric 工作區管理員會建立預設入門集區和自訂集區。
![螢幕擷取畫面,顯示在環境 [計算] 區段中選取集區的位置。](media/environment-introduction/environment-pool-selection.png#lightbox)
在 [計算] 區段中選取集區之後,可以在所選集區的節點大小和限制範圍內調整執行程式的核心和記憶體。 如需Spark計算大小及其核心或記憶體選項的詳細資訊,請參閱 Fabric 中的Spark計算。 使用 [計算 ] 區段來設定Spark工作階段層級屬性,根據工作負載需求自定義執行程式記憶體和核心。 透過 spark.conf.set 控制應用層級參數所設定的Spark屬性與環境變數無關。
例如,假設您想要選取具有大型節點大小的自定義集區,也就是 16 個 Spark 虛擬核心,作為環境集區。
在 [ 計算 ] 區段的 [ 環境集區] 下,使用 Spark驅動程式核心 下拉式清單,根據您的作業層級需求選擇 4、 8或 16。
若要將記憶體配置給驅動程式和執行程式,請在 [Spark 執行程式記憶體] 下選取 28 g、 56 g 或 112 g。 所有專案都在大型節點記憶體限制的範圍內。
![螢幕擷取畫面,顯示在環境 [計算] 區段中選取核心數目的位置。](media/environment-introduction/env-cores-selection.png)
![螢幕擷取畫面,顯示在環境 [計算] 區段中選取核心數目的位置。](media/environment-introduction/env-cores-selection.png#lightbox)