這很重要
這項功能目前處於預覽階段。
Fabric Runtime 與 Microsoft Fabric 生態系統進行無縫整合,為由 Apache Spark 驅動的資料工程與資料科學專案提供穩健環境。
本文介紹 Fabric Runtime 2.0 公開預覽版,這是為 Microsoft Fabric 大數據運算設計的最新執行環境。 它突顯了使本次版本成為可擴展分析與先進工作負載重要進展的關鍵功能與元件。
Fabric Runtime 2.0 包含以下元件與升級,旨在提升您的資料處理能力:
- Apache Spark 4.1
- 作業系統:Azure Linux 3.0 (Mariner 3.0)
- 爪哇:21
- Scala:2.13
- Python:3.13
- 三角洲湖:4.2
- R:4.5.2
這很重要
Microsoft Fabric 團隊正在推出 Microsoft Fabric Runtime 2.0 的更新。 作為本次更新的一部分,Python 升級為使用 Environment artifacts 搭配 python 和 wheel 函式庫的客戶引入了一項重大變更。 客戶在執行 Notebook 或 Spark Job Definition(SJD)時會看到兩個錯誤訊息之一:
- 錯誤:警告:1 項淘汰警告(自 2.13.0 起);如需詳細資料,請啟用
:setting -deprecation或:replay -deprecation。來源:SparkCoreService。 - 「LibraryManagementError」:「已偵測到對基礎 Spark Python 環境的升級。 請重新發布環境。|UserError"
必須行動
重新發佈您的環境(包括函式庫)。 為此,移除所有函式庫、發佈環境、重新新增所有函式庫,然後再次發佈。 此過程會利用更新後的 Python 執行環境重建環境,並解決此問題。
小提示
Fabric Runtime 2.0 支援原生 執行引擎(Native Execution Engine),能大幅提升效能且不需額外成本。 你可以在環境層啟用原生執行引擎,讓所有工作和筆記本自動繼承增強的效能能力。
啟用運行環境 2.0
你可以在工作區層級或環境項目層級啟用 Runtime 2.0。 使用 workspace 設定,將 Runtime 2.0 作為你工作區中所有 Spark 工作負載的預設值。 或者,你可以用 Runtime 2.0 建立一個環境項目,用於特定筆記本或 Spark 工作定義,這樣會覆蓋工作區的預設值。
在 Workspace 設定中啟用 Runtime 2.0
要將 Runtime 2.0 設為整個工作區的預設:
請前往 Fabric 工作區內的 Workspace 設定 頁面。
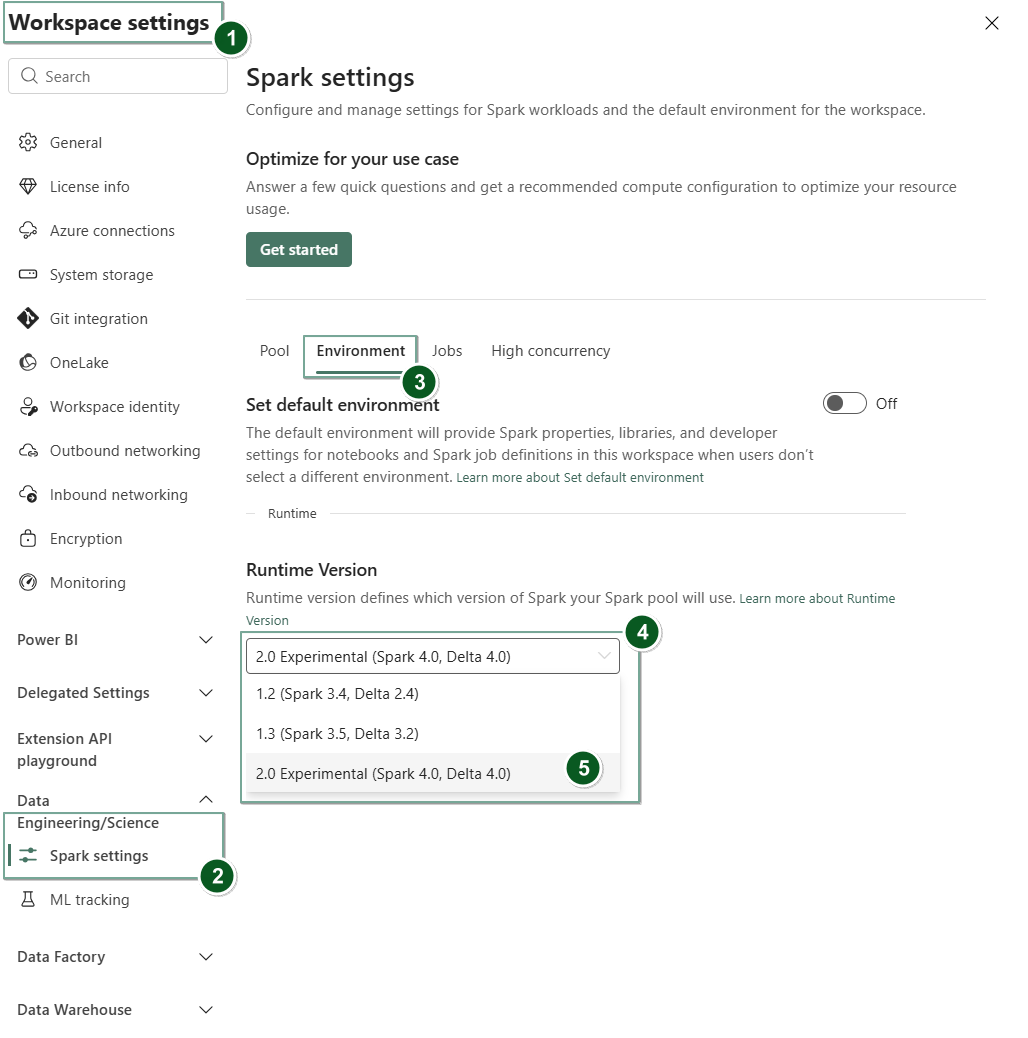
選擇 資料工程/科學 標籤,然後選擇 Spark 設定。
選取環境索引標籤。
在 執行時版本 下拉選單中,選擇 2.0 公開預覽(Spark 4.1、Delta 4.2), 並儲存你的變更。
你的工作區的預設運行時環境設定為 Runtime 2.0。

在環境項目中啟用執行時 2.0
要使用 Runtime 2.0 搭配特定的筆記本或 Spark 工作定義:
建立一個新的環境項目或開啟一個現有的環境項目。
在執行時下拉選單中,選擇 2.0 公開預覽(Spark 4.1、Delta 4.2),儲存並發佈你的變更。
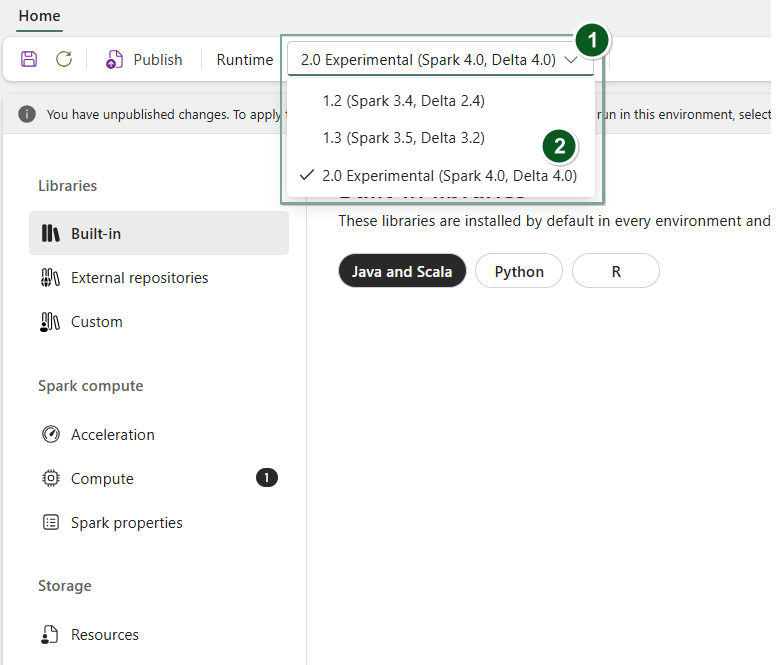
接著,你可以將這個 環境 項目與 你的筆記本 或 Spark 工作定義一起使用。

你現在可以開始嘗試 Fabric Runtime 2.0(Spark 4.1 和 Delta Lake 4.2)引入的最新改進與功能。
公開預覽
Fabric Runtime 2.0 公開預覽階段讓你能使用來自 Spark 4.1 和 Delta Lake 4.2 的新功能與 API。 預覽版讓你能立即使用最新的 Spark 和 Delta 強化功能,並確保你能順利準備並過渡到像是較新的 Java、Scala 和 Python 版本等增強與改進的變更。
小提示
如需最新資訊、變更的詳細清單,以及 Fabric 執行時間的特定版本資訊,請檢查並訂閱 Spark 執行階段版本和更新。
重點摘要
效能與執行引擎的提升
Fabric Runtime 2.0 包含 原生執行引擎(Native Execution Engine),相較開源 Spark 有顯著的效能提升。 該引擎利用向量化處理加速 Spark 對湖屋基礎設施的查詢,且不需修改程式碼。
執行環境 2.0 的主要效能特性:
- 最高快六倍:基準測試顯示在 TPC-DS 工作負載上,效能比開源 Spark 快六倍。
- 向量化 CSV 解析:原生執行引擎包含向量化 CSV 解析器,加速 CSV 的擷取與查詢工作負載。 未來更新計畫提供向量化 JSON 解析與 Spark 結構化串流支援。
要啟用原生執行引擎,請參見 Fabric Data Engineering 的原生執行引擎。
Apache Spark 4.1
Apache Spark 4.0 作為 4.x 系列的首個版本,標誌著一個重要的里程碑,體現了充滿活力的開源社群共同努力。 Fabric Runtime 2.0 現在運行於 Apache Spark 4.1,該版本在此基礎上進行額外改進。
在此版本中,Spark SQL 大幅擴充了強大的新功能,旨在提升 SQL 工作負載的表現力與多樣性,例如 VARIANT 資料型別支援、SQL 使用者定義函式、會話變數、管道語法及字串排序。 PySpark 持續致力於功能廣度與整體開發體驗,帶來原生繪圖 API、新的 Python 資料來源 API、對 Python UDTF 的支援,以及 PySpark UDF 的統一剖析,並有許多其他改進。 結構化串流隨著關鍵新增功能而演進,提供更強的控制與易於除錯,特別是引入了 Arbitrary State API v2,以提供更靈活的狀態管理,以及 State Data Source,使除錯更為便利。
你可以在這裡查看完整清單和詳細變更:
備註
在 Spark 4.x 中,SparkR 已被棄用,未來版本可能會被移除。
三角洲湖 4.2
Delta Lake 4.2 在先前的 Delta Lake 版本基礎上,持續致力於讓 Delta Lake 能跨平台互通、更易操作且效能提升。 它包含強大的新功能、效能優化,以及為開放資料湖屋未來打造的基礎強化。
有關 Delta Lake 3.3、4.0、4.1 和 4.2 引入的完整清單及詳細變更,請參見:
資料配置與優化
Runtime 2.0 支援 Delta 資料表的資料佈局與優化功能:
- Z 排序:依指定欄位組織 Delta 表格檔案中的資料,以提升篩選查詢的查詢效能。
- 液態聚類:一種靈活的聚類方式,能自動優化資料配置,無需人工維護。
- 平行 Delta 快照載入:原生執行引擎平行載入 Delta 表格快照,縮短大型資料表的查詢啟動時間。
這很重要
Delta Lake 4.2 的專屬功能仍屬實驗性質,僅適用於 Spark 體驗,如筆記本和 Spark 工作定義。 如果你需要在多個 Microsoft Fabric 工作負載中使用相同的 Delta Lake 資料表,就不要啟用那些功能。 欲了解哪些協定版本與功能在所有 Microsoft Fabric 體驗中相容,請參閱 Delta Lake 表格格式互通性。
執行時 2.0 中的運算管理
執行時 2.0 支援以下運算管理功能:
- 資源配置檔:配置 Spark 會話的預先定義資源配置,以符合工作負載需求並控制成本。
- 自訂即時池(預覽):建立專用且預先預熱的 Spark 池,以減少會話啟動時間。 自訂的即時群組在預覽版中可用於 Runtime 2.0 工作負載。
限制與備註
- Delta Lake 4.x 的專屬功能是實驗性質,僅適用於 Spark 經驗,例如筆記本和 Spark 工作定義。 如果你需要在多個 Fabric 工作負載中使用相同的 Delta Lake 表格,就不要啟用那些功能。 欲了解更多資訊,請參閱 Delta Lake 表格格式互通性。
- Runtime 2.0 目前為公開預覽版。 部分功能與 API 可能會在正式上市前變更。
- Fabric Spark 的 VS Code 擴充套件支援 Runtime 2.0 用於筆記本與 Spark 工作定義的開發。