Dataflows Gen2 中的快速拷貝
本文會說明 Microsoft Fabric Data Factory 中 Dataflows Gen2 內的快速拷貝功能。 資料流程流有助於擷取和轉換資料。 在 SQL DW 計算引入資料流程擴增後,您便可大規模轉換資料。 然而,必須先擷取您的資料。 透過引入快速拷貝,您可以使用資料流程的簡單體驗擷取數 TB 的資料,但會使用管線複製活動的可調整後端。
在啟用此功能後,資料流程會在資料大小超過特定閾值時自動切換後端,且無須在撰寫資料流程期間變更任何項目。 在重新整理資料流程之後,您可以查看顯示於該處的 [引擎] 類型,以檢查重新整理歷程記錄,了解是否已在執行期間使用快速拷貝。
啟用 需要快速複製 選項后,如果未使用快速複製,則會取消數據流重新整理。 這有助您避免等待重新整理逾時,以繼續操作。 此行為在偵錯工作階段中也有助於使用您的資料來測試資料流程行為,同時縮短等待時間。 您可以在查詢步驟窗格中使用快速拷貝標記,輕鬆檢查是否可使用快速拷貝來執行您的查詢。

必要條件
- 您必須擁有網狀架構容量。
- 針對檔案資料,檔案的格式至少為 100 MB 的 .csv 或 parquet 格式,並儲存在 Azure Data Lake Storage (ADLS) Gen2 或 Blob 儲存體帳戶中。
- 針對包含 Azure SQL DB 和 PostgreSQL 的資料庫,資料來源中會有 500 萬或更多個資料列。
注意
您可以選取 [需要快速拷貝] 設定,略過閾值以強制快速拷貝。
連接器支援
以下 Dataflow Gen2 連接器目前可支援快速拷貝:
- ADLS Gen2
- Blob 儲存體
- Azure SQL DB
- Lakehouse
- PostgreSQL
- 內部部署 SQL Server
- 倉儲
- Oracle
- Snowflake
在連線至檔案來源時,複製活動僅會支援以下數種轉換:
- 合併檔案
- 選取資料行
- 變更資料類型
- 重新命名資料行
- 移除資料行
您仍可透過將擷取和轉換步驟分割為不同的查詢來套用其他轉換。 第一個查詢會真的擷取資料,而第二個查詢會參考其結果,以便使用 DW 計算。 針對 SQL 來源,可支援屬於原生查詢的任何轉換。
當您直接將查詢載入輸出目的地時,目前僅可支援 Lakehouse 目的地。 若您要使用另一個輸出目的地,可以先檢閱及測試查詢,稍後再參考。
如何使用快速拷貝
瀏覽至適當的網狀架構端點。
瀏覽至進階工作區,並建立資料流程 Gen2。
在新資訊流程的 [首頁] 索引標籤上,選取 [選項]:
![螢幕擷取畫面,其中顯示了應在 [首頁] 索引標籤上何處選取 Dataflows Gen2 的 [選項]。](media/dataflows-gen2-fast-copy/options.png)
然後,請在 [選項] 對話方塊上選擇的 [縮放] 索引標籤,然後選取 [允許使用快速拷貝連接器] 核取方塊以開啟快速拷貝。 然後請關閉 [選項] 對話方塊。
![螢幕擷取畫面,其中顯示了應在 [選項] 對話方塊中 [縮放] 索引標籤上的何處啟動快速拷貝。](media/dataflows-gen2-fast-copy/enable-fast-copy.png)
選取 [取得資料],然後選擇 ADLS Gen2 來源,並填寫容器的詳細資料。
使用 [合併檔案] 功能。
![螢幕擷取畫面,其中顯示了預覽資料夾資料視窗,並以顯目提示顯示 [合併] 選項。](media/dataflows-gen2-fast-copy/preview-folder-data.png)
若要確保快速靠背,請僅套用本文連接器支援章節中所列的變換情況。 若您需要套用更多變換,請先儲存資料,稍後再參考查詢內容。 在參考的查詢上執行其他變換。
(選用) 您可透過以滑鼠右鍵按一下查詢內容來選取並啟用該選項,以為查詢內容設定 [需要快速拷貝] 選項。
![螢幕擷取畫面,其中顯示了在查詢右鍵功能表上的何處可選取 [需要快速拷貝] 選項。](media/dataflows-gen2-fast-copy/require-fast-copy.png)
(選用)) 目前,您僅能將 Lakehouse 設定為輸出目的地。 針對任何其他目的地,請檢閱及測試查詢,並稍後在另一個可輸出至任何來源的查詢中參考前一個查詢內容。
檢查快速拷貝標記,以查看是否可以使用快速拷貝來執行您的查詢。 若可以,[引擎] 類型會顯示 CopyActivity。

發佈資料流程。
在重新整理完成後進行檢查,以確認已使用快速拷貝。
![螢幕擷取畫面,其中顯示了預覽資料夾資料視窗,並以顯目提示顯示 [合併] 選項。](media/dataflows-gen2-fast-copy/preview-folder-data.png#lightbox)
如何分割查詢以利用快速複製
若要在使用 Dataflow Gen2 處理大量數據時獲得最佳效能,請使用 Fast Copy 功能,先將數據導入預備環境,然後使用 SQL 數據倉儲進行大規模數據轉換。 此方法可大幅增強端對端效能。
若要實作此作業,快速複製指標可引導您將查詢分割成兩個部分:使用 SQL DW 計算將數據擷取至暫存和大規模轉換。 建議您將查詢評估推送至快速複製,以用來內嵌數據。 當快速複製指標指示無法執行其餘步驟時,您可以啟用中繼站來分割其餘的查詢。
步驟診斷指標
| 指示器 | 圖示 | 描述 |
|---|---|---|
| 此步驟將會使用快速複製 進行評估 | 
|
快速複製指標會告訴您,此步驟的查詢支援快速複製。 |
| 此步驟不支援快速複製 | 
|
快速複製指標會顯示此步驟不支援快速複製。 |
| 查詢中的一個或多個步驟不受快速查詢 的支援 | 
|
快速複製指標會顯示此查詢中的某些步驟支援快速複製,而其他步驟則不支援。 若要優化,請分割查詢:黃色步驟(可能由快速複製支援)和紅色步驟(不支援)。 |
逐步指引
在 Dataflow Gen2 中完成數據轉換邏輯之後,快速複製指標會評估每個步驟,以判斷有多少步驟可以利用快速複製來提升效能。
在下列範例中,最後一個步驟會顯示紅色,表示快速複製不支援具有 Group By 的步驟。 然而,快速複製有可能支持所有顯示為黃色的先前步驟。

目前,如果您直接發佈並執行數據流 Gen2,它將不會使用快速複製引擎來載入您的數據,如下圖所示:
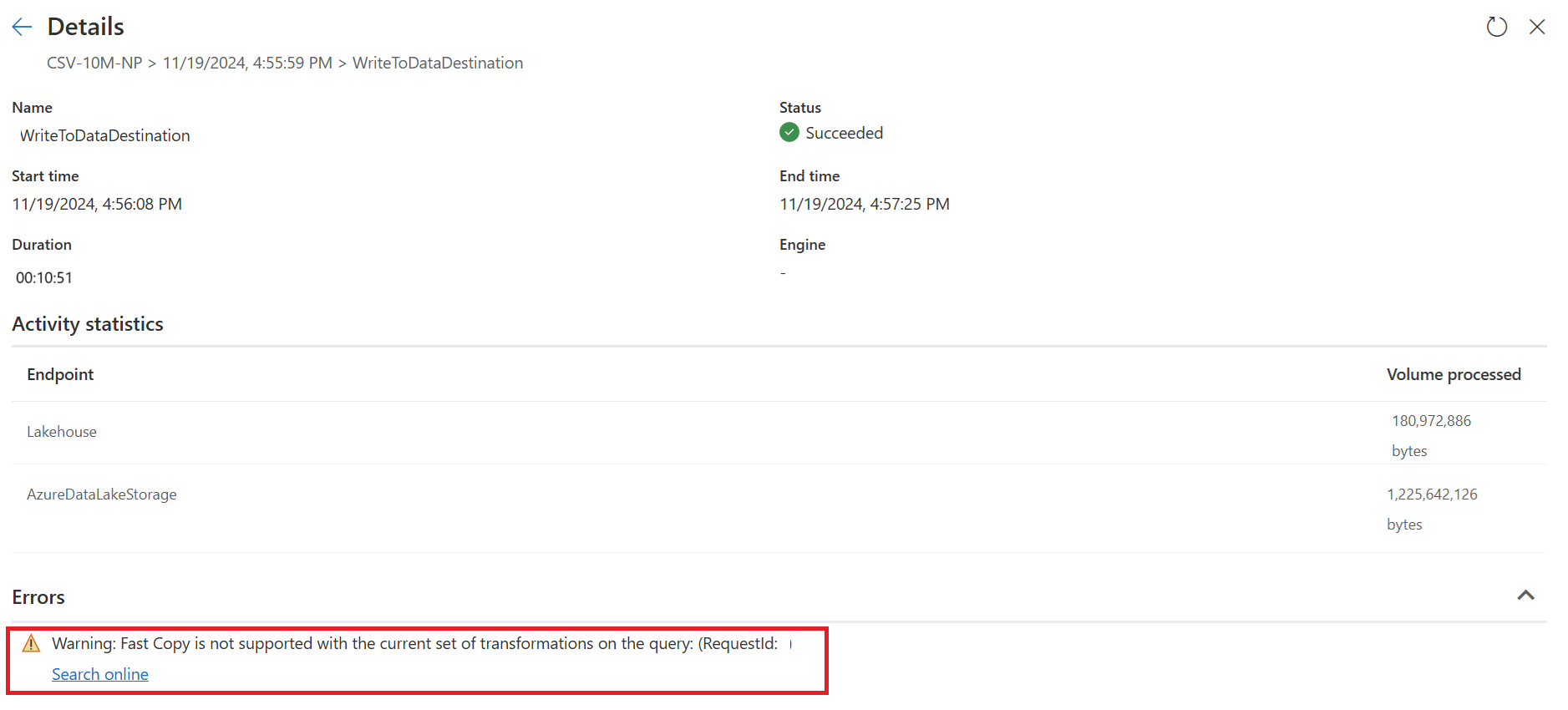
若要使用快速複製引擎並改善數據流 Gen2 的效能,您可以將查詢分割成兩個部分:使用 SQL DW 計算將數據擷取至暫存和大規模轉換,如下所示:
拿掉快速複製不支援的轉換(顯示紅色),以及目的地(如果已定義)。
快速複製指標現在對於剩餘步驟顯示綠色,這表示您的第一個查詢可以利用快速複製來提升效能。
選擇第一個查詢的 [動作],然後選擇 [啟用過渡和參考]。

在新的參考查詢中,讀取了「分組依據」轉換和目的地(如果適用的話)。

發佈並重新整理您的 Dataflow Gen2。 您現在會在 Dataflow Gen2 中看到兩個查詢,整體時間顯著縮短。
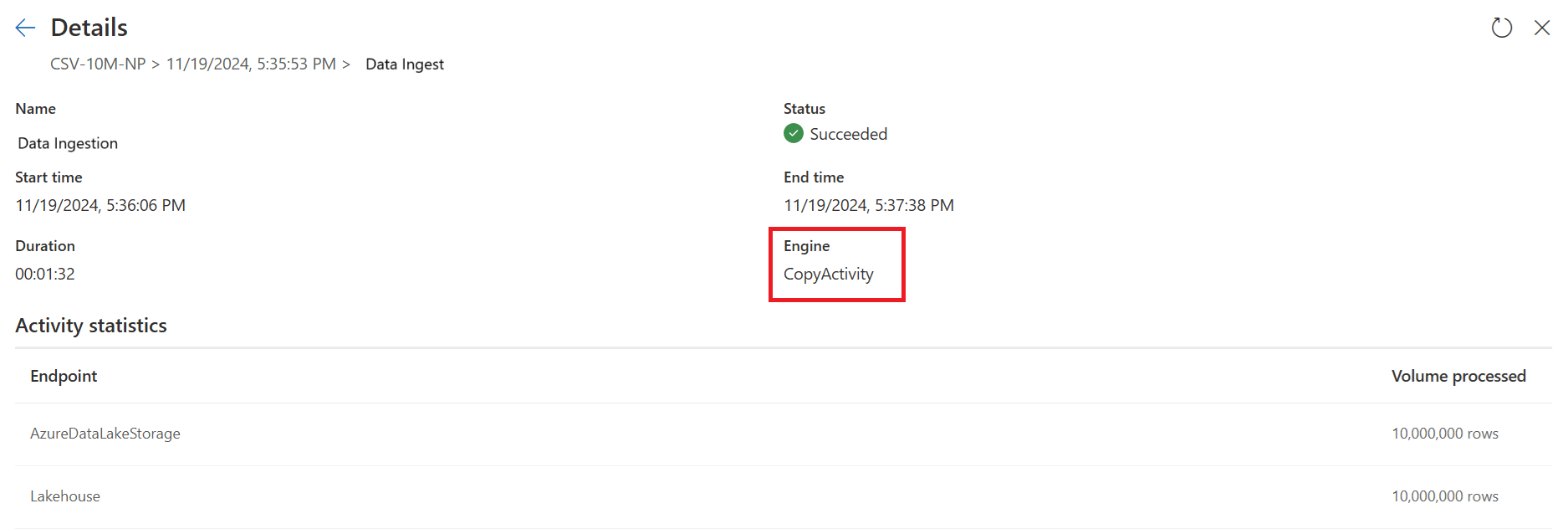
第一個查詢會使用Fast Copy將數據載入至暫存區。
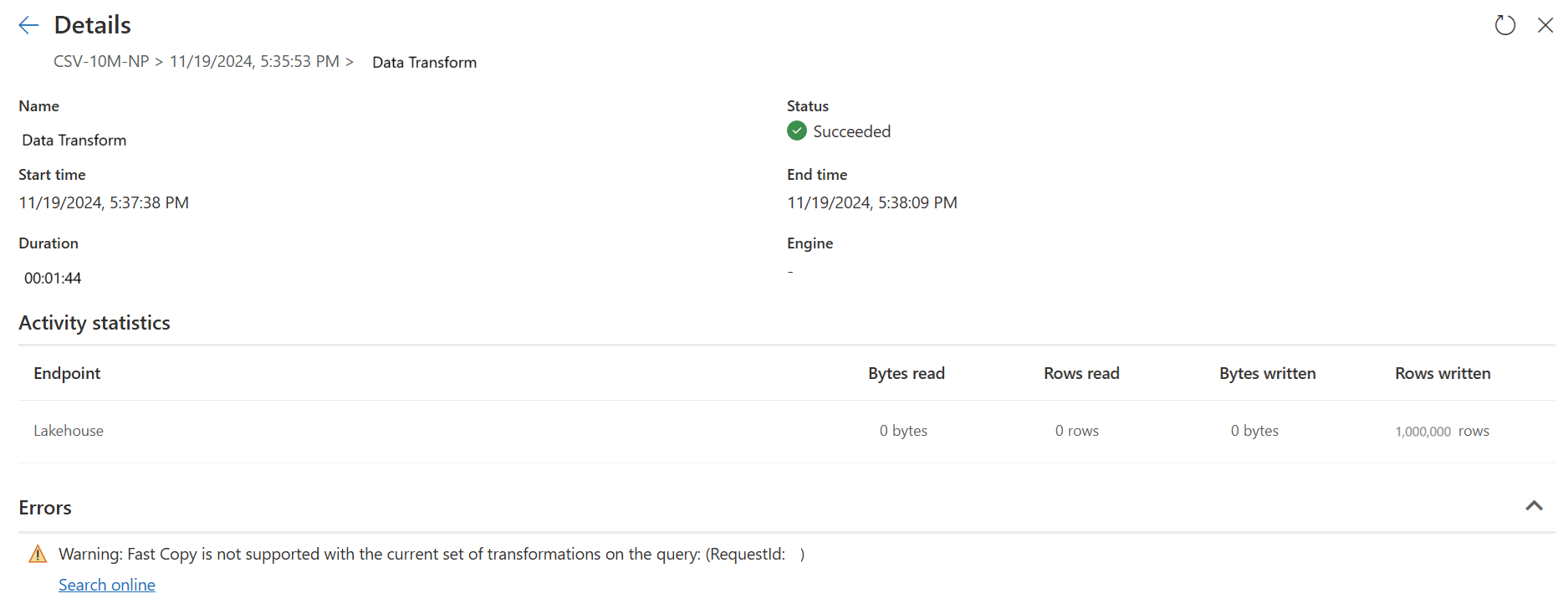
第二個查詢會使用 SQL DW 計算來執行大規模轉換。

第一個查詢:
第二個查詢:
已知的限制
- 若要支援快速拷貝,需有內部部署的資料閘道 3000.214.2 或更新版本。
- 不支援 VNet 閘道。
- 不支援將資料寫入 Lakehouse 中的現有資料表。
- 不支援固定架構。