Data Factory in Microsoft Fabric 中的 Parquet格式
本文概述如何在 Microsoft Fabric 的 Data Factory 資料管線中設定 Parquet 格式。
支援的功能
下列活動和連接器支援 Parquet 格式做為來源和目的地。
| 類別 | 連接器/活動 |
|---|---|
| 支援的連接器 | Amazon S3 |
| Amazon S3 相容 | |
| Azure Blob 儲存體 | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 \(部分機器翻譯\) | |
| Azure 檔案 | |
| 檔案系統 | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse 檔案 | |
| Oracle 雲端儲存空間 | |
| SFTP | |
| 支援的活動 | 複製活動(來源/目的地) |
| 查閱活動 | |
| GetMetadata 活動 | |
| 刪除活動 |
複製活動中的 Parquet 格式
若要設定 Parquet 格式,請在資料管線複製活動的來源或目的地中選擇您的連線,然後在 [檔案格式] 下拉式清單中選取 [Parquet]。 選取 [設定 ] 以進一步設定此格式。
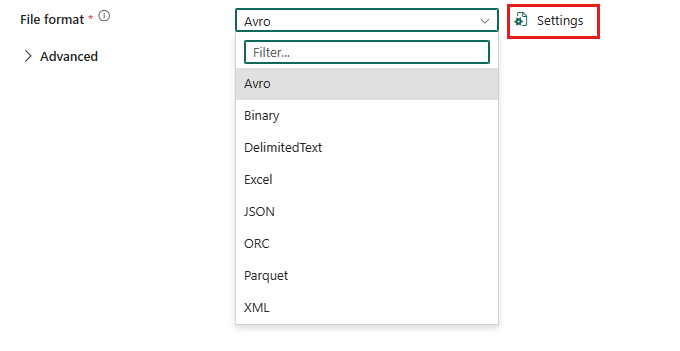
Parquet 格式作為來源
選取 [檔案格式] 區段中的 [設定] 之後,快顯 [檔案格式設定] 對話框中會顯示下列屬性。
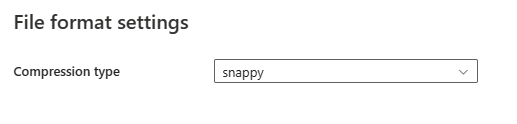
- 壓縮類型:選擇用來讀取下拉式清單中的 Parquet 檔案的壓縮編解碼器。 您可以選擇 None、gzip (.gz)、snappy、lzo、Brotli (.br)、Zstandard、lz4、lz4frame、bzip2 (.bz2) 或 lz4hadoop。
Parquet 格式為目的地
選取 [ 設定] 之後,快顯 [檔案格式設定 ] 對話框中會顯示下列屬性。
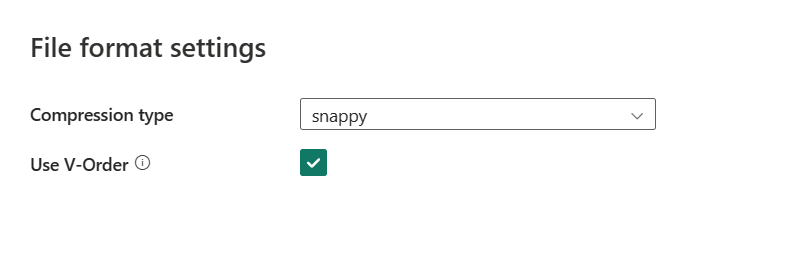
壓縮類型:選擇用來寫入下拉式清單中的 Parquet 檔案的壓縮編解碼器。 您可以選擇 None、gzip (.gz)、snappy、lzo、Brotli (.br)、Zstandard、lz4、lz4frame、bzip2 (.bz2) 或 lz4hadoop。
使用 V 順序:啟用 parquet 檔案格式的寫入時間優化。 如需詳細資訊,請參閱 Delta Lake 資料表最佳化和 V 順序。 預設會啟用此功能。
在 [目的地] 索引標籤的 [進階設定] 底下,會顯示下列 Parquet 格式相關屬性。
- 每個檔案的資料列數上限:當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列數上限。 指定您想要為每個檔案寫入的最大資料列。
- 檔名前置詞:適用於設定每個檔案的資料列上限時。 當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式:
<fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。
資料表摘要
Parquet 作為來源
使用 Parquet 格式時,複製活動 [來源 ] 區段支援下列屬性。
| 名稱 | 描述: | 值 | 必要 | JSON 腳本屬性 |
|---|---|---|---|---|
| 檔案格式 | 選取要使用的檔案格式。 | Parquet | Yes | type (在 datasetSettings 下):Parquet |
| 壓縮類型 | 用來讀取 Parquet 檔案的壓縮編解碼器。 | 從下列項目中選擇: None gzip (.gz) snappy lzo 布羅特利 (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet 作為目的地
使用 Parquet 格式時,複製活動 目的地 區段支援下列屬性。
| 名稱 | 描述: | 值 | 必要 | JSON 腳本屬性 |
|---|---|---|---|---|
| 檔案格式 | 選取要使用的檔案格式。 | Parquet | Yes | type (在 datasetSettings 下):Parquet |
| 使用 V-Order | parquet 檔格式的寫入時間優化。 | 已選取或未選取 | No | enableVertiParquet |
| 壓縮類型 | 用來寫入 Parquet 檔案的壓縮編解碼器。 | 從下列項目中選擇: None gzip (.gz) snappy lzo 布羅特利 (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| 每個檔案的最大資料列 | 當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列上限。 指定您想要為每個檔案寫入的最大資料列。 | <每個檔案的資料列數上限> | No | maxRowsPerFile |
| 檔名前置詞 | 適用於設定 每個檔案 的資料列上限時。 當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式:<fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。 |
<您的檔名前置詞> | No | fileNamePrefix |