事件
3月31日 下午11時 - 4月2日 下午11時
最終Microsoft Fabric、Power BI、SQL 和 AI 社群主導的活動。 2025 年 3 月 31 日至 4 月 2 日。
立即註冊適用於:✅ Microsoft Fabric 中的 SQL 分析端點和倉儲
從 Lakehouse 擷取資料是關鍵的輸入/輸出 (IO) 作業,對查詢效能具有重大影響。 網狀架構數據倉儲採用精簡的存取模式,以增強從記憶體讀取的數據,並提升查詢執行速度。 此外,它會利用本機快取,以智慧方式將遠端存放讀取的需求降到最低。
快取是一種技術,可藉由減少 IO 作業來改善資料處理應用程式的效能。 快取會將經常存取的資料和中繼資料儲存在較快的儲存體層中,例如本機記憶體或本機 SSD 磁碟,以便直接從快取更快速地處理後續要求。 如果查詢先前已存取特定資料集,則任何後續查詢都會直接從記憶體內部快取擷取該資料。 相較於從遠端存放擷取資料,這種方法大幅降低 IO 延遲,因為相較於從遠端存放擷取資料,本機記憶體作業的速度更快。
快取對使用者完全透明。 不論原點為何,無論是倉儲資料表、OneLake 快捷方式,還是參考非 Azure 服務的 OneLake 快捷方式,查詢都會快取其存取的所有資料。
本文稍後會說明兩種類型的快取:
當查詢從儲存體存取和擷取資料時,它會執行轉換程序,將原檔案格式中的資料轉碼為記憶體內部快取中高度最佳化的結構。

快取中的資料會以針對分析查詢最佳化的壓縮單欄式格式來組織。 每個資料行都會儲存在一起,與其他資料行分開,以進行更好的壓縮,因為類似的資料值會儲存在一起,從而降低磁碟使用量。 當查詢需要在彙總或篩選等特定資料行上執行作業時,引擎可以更高效地運作,因為它不需要處理來自其他資料行的不必要資料。
此外,此單欄式儲存體也有利於平行處理,可大幅加快大型資料集的查詢執行速度。 引擎可利用現代多核心處理器的優勢,同時在多個資料行上執行作業。
這種方法特別適用於分析工作負載,其中查詢牽涉到掃描大量資料來執行彙總、篩選和其他資料操作。
某些資料集太大,無法在記憶體內部快取內容納。 為了維持這些資料集的快速查詢效能,倉儲會利用磁碟空間作為記憶體內部快取的補充延伸模組。 載入記憶體內部快取的任何資訊也會序列化為 SSD 快取。
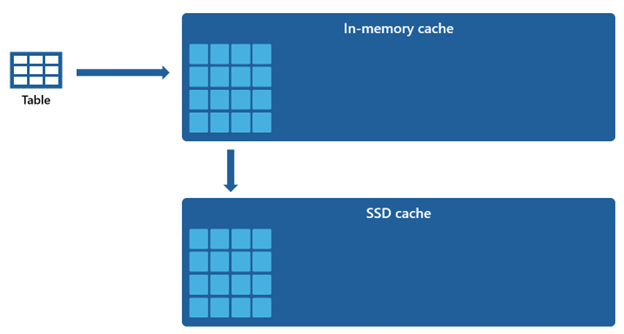
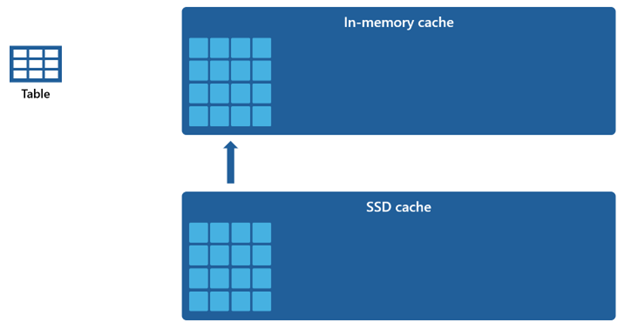
假設記憶體內部快取的容量比 SSD 快取還小,從記憶體內部快取中移除的資料會在 SSD 快取中保留較長時間。 當後續查詢請求此資料時,資料會從 SSD 快取擷取至記憶體內部快取,速度遠比從遠端存放擷取快得多,最終為您提供更一致的查詢效能。
快取會持續保持作用中狀態,並在背景中順暢地運作,無需您的介入。 不需要停用快取,因為這樣做必然會導致查詢效能明顯下降。
快取機制是由 Microsoft Fabric 本身協調及維持,而且不提供使用者手動清除快取的功能。
完整快取交易一致性可確保對儲存體中資料所做的任何修改,例如透過資料操作語言 (DML) 作業,在一開始載入記憶體內部快取之後,將會產生一致的資料。
當快取觸達其容量閾值,且第一次讀取新的資料時,將會從快取中移除長時間未使用的物件。 制定此程序的目的是為新資料的湧入建立空間,並維護最佳的快取使用率策略。
事件
3月31日 下午11時 - 4月2日 下午11時
最終Microsoft Fabric、Power BI、SQL 和 AI 社群主導的活動。 2025 年 3 月 31 日至 4 月 2 日。
立即註冊