Power Automate Process Mining 可讓您選擇直接從 Azure Data Lake Storage Gen2 儲存和讀取事件記錄檔資料。 此功能可透過直接連線至您的儲存帳戶來簡化擷取、轉換、載入 (ETL) 管理。
此功能目前支援擷取下列各項:
表格
-
Delta 資料表
- Fabric Lakehouse 中的單一 Delta 資料表。
檔案和資料夾
-
CSV
- 單一 CSV 檔案。
- 包含多個有相同結構之 CSV 檔案的資料夾。 擷取所有檔案。
-
Parquet
- 單一 Parquet 檔案。
- 包含多個有相同結構之 Parquet 檔案的資料夾。 擷取所有檔案。
-
Delta-parquet
- 包含 Delta-parquet 結構的資料夾。
必要條件
Data Lake Storage 帳戶必須是 Gen2。 您可以從 Azure 入口網站查看此資訊。 不支援 Azure Data Lake Gen1 storage 帳戶。
Data Lake Storage 帳戶必須啟用階層命名空間。
在儲存帳戶層級中,必須將擁有者角色指派給負責該環境初始容器設定的使用者,以便後續同一環境中的其他使用者能夠正常使用。 這些使用者連接到同一容器,並且必須具有以下指派:
- 已指派儲存體 Blob 資料讀者或儲存體 Blob 資料參與者角色
- 至少已指派 Azure Resource Manager 讀取者角色。
應為您的儲存體帳戶建立資源共用 (CORS) 規則,以便與 Power Automate Process Mining 共用。
允許的來源必須是設定為
https://make.powerautomate.com和https://make.powerapps.com。允許的方法必須包括:
get、options、put、post。允許的標頭應盡量靈活。 建議您將它們定義為
*。顯示標頭應盡量靈活。 建議您將它們定義為
*。最長時數應盡可能靈活。 建議使用
86400。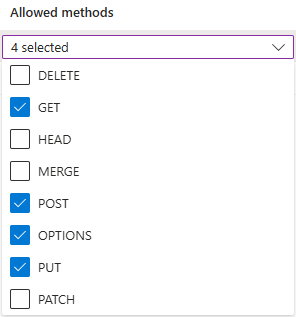
Data Lake Storage 中的 CSV 資料應符合下列 CSV 檔案格式需求:
- 壓縮類型:無
- 資料行分隔符號:逗號 (,)
- 資料列分隔符號:預設與編碼。 例如,預設 (\r、\n 或 \r\n)
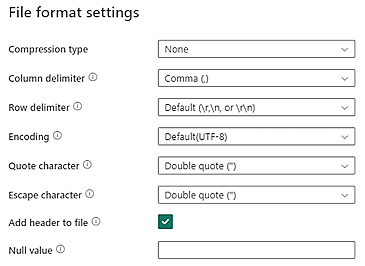
所有資料都必須是最終事件記錄檔格式,並符合資料要求中所列的要求。 資料應準備好對應至程序挖掘結構描述。 擷取後就無法進行資料轉換。
標題行的大小 (寬度) 目前限制為 1 MB。
重要
請確定 CSV 檔案中所示的時間戳記符合 ISO 8601 標準格式 (例如 YYYY-MM-DD HH:MM:SS.sss 或 YYYY-MM-DDTHH:MM:SS.sss)。
連線至 Azure Data Lake Storage
在左側瀏覽窗格中,選取 Process Mining>由此開始。
在程序名稱欄位中輸入您的程序名稱。
在資料來源標題底下,選取匯入資料> Azure Data Lake>繼續。

在連線設定畫面上,從下拉式選單中選取您的訂閱識別碼、資源群組、儲存體帳戶和容器。
選取包含事件記錄檔資料的檔案或資料夾。
您可以選取單一檔案或包含多個檔案的資料夾。 所有檔案都必須有相同的標頭和格式。
選取下一步。
在對應資料畫面中,將您的資料對應至所需的結構描述。
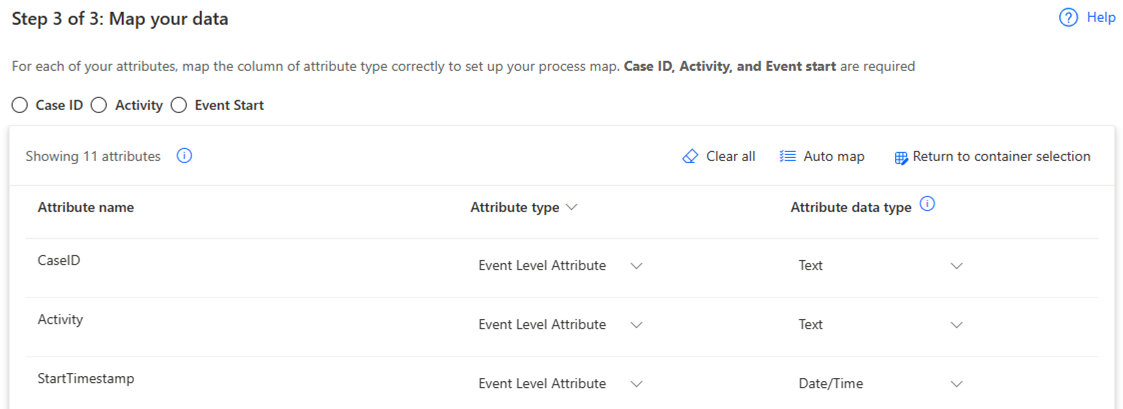
選取儲存並分析來完成連線。
定義累加式資料重新整理設定
您可以透過完整或累加式重新整理,重新整理從 Azure Data Lake 引入的程序。 雖然沒有保留原則,但您可以使用下列其中一種方法以累加方式來擷取資料:
如果您在上一節中選取了單一檔案,請將更多資料附加到所選檔案。
如果您在上一節中選取了資料夾,請將增量檔案新增至所選資料夾。
重要
當您將累加檔案新增至所選資料夾或子資料夾時,請務必使用日期命名檔案來指示累加順序,例如 YYYMMDD.csv 或 YYYYMMDDHHMMSS.csv。
若要重新整理程序:
前往程序的詳細資料頁面。
選取重新整理設定。
在排程重新整理畫面上,完成下列步驟:
- 開啟讓您的資料保持最新狀態切換開關。
- 在重新整理資料間隔下拉式清單中,選取重新整理的頻率。
- 在開始欄位中,選取重新整理的日期與時間。
- 開啟累加式重新整理切換開關。