使用 XMLA 端點進行進階累加式重新整理和實時數據
具有啟用讀取/寫入作業之 XMLA 端點的 進階版 容量中的語意模型,允許透過工具、腳本和 API 支援進行更進階的重新整理、數據分割管理和元數據部署。 此外,透過 XMLA 端點的重新整理作業不限於 每天 48 次重新整理,而且不會強加排程的 重新整理時間限制 。
資料分割
看不到語意模型數據表分割區,且無法使用Power BI Desktop或 Power BI 服務 來管理。 對於指派給 進階版 容量的工作區中的模型,您可以使用 SQL Server Management Studio (SSMS)之類的工具來管理分割區,方法是使用開放原始碼表格式編輯器、使用表格式模型腳本語言 (TMSL) 編寫腳本,並以程式設計方式使用表格式物件模型 (TOM)。
當您第一次將模型發佈至 Power BI 服務 時,新模型中的每個數據表都有一個分割區。 對於沒有累加式重新整理原則的數據表,除非已套用篩選,否則一個數據分割會包含該數據表的所有數據列。 對於具有累加式重新整理原則的數據表,只有一個初始分割區存在,因為Power BI尚未套用原則。 當您根據 RangeStart 和 RangeEnd 參數定義數據表的日期/時間範圍篩選,以及 Power Query 編輯器 中套用的任何其他篩選時,您可以在 Power BI Desktop 中設定初始數據分割。 此初始數據分割只包含符合篩選準則的數據列。
當您執行第一次重新整理作業時,沒有累加式重新整理原則的數據表會重新整理該數據表預設單一分割區中包含的所有數據列。 對於具有累加式重新整理原則的數據表,會自動建立重新整理和歷程記錄數據分割,並根據每個數據列的日期/時間載入數據列。 如果累加式重新整理原則包含即時取得數據,Power BI 也會將 DirectQuery 分割區新增至數據表。
此第一次重新整理作業可能需要相當長的時間,視需要從數據源載入的數據量而定。 模型的複雜性也可能是一個重要因素,因為重新整理作業必須執行更多處理和重新計算。 這項作業可以啟動。 如需詳細資訊,請參閱 防止初始完整重新整理逾時。
分割區會針對 和 依期間數據粒度來建立和命名:年、季、月和日。 最新的數據分割,重新整理分割區,包含您在原則中指定的重新整理期間中的數據列。 歷程記錄分割區會依重新整理期間的完整期間包含數據列。 如果已啟用即時,DirectQuery 數據分割會挑選重新整理期間結束日期之後所發生的任何數據變更。 重新整理和歷程記錄數據分割的數據粒度取決於您在定義原則時所選擇的重新整理和歷程記錄(存放區)期間。
例如,如果今天的日期是 2021 年 2 月 2 日,而 數據源的 FactInternetSales 數據表包含數據列,則如果我們的原則指定包含實時變更、重新整理過去一天重新整理期間中的數據列,以及將數據列儲存在過去三年的歷程記錄期間。 然後使用第一次重新整理作業,未來會針對變更建立 DirectQuery 分割區、針對今天的數據列建立新的匯入分割區、針對昨天建立歷程記錄數據分割、2021 年 2 月 1 日整日期間。 過去一個月期間(2021 年 1 月)會建立歷史分割區、針對上一年期間 (2020 年) 建立歷史分割區,並建立 2019 年和 2018 年全年期間的歷史分割區。 不會建立整個季度數據分割,因為我們尚未完成 2021 年第一個完整季。
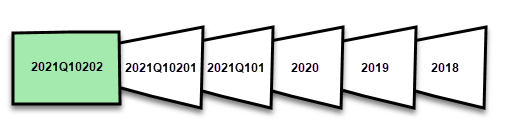
每次重新整理作業時,只會重新整理重新整理期間分割區,並更新 DirectQuery 數據分割的日期篩選條件,只包含目前重新整理期間之後發生的變更。 系統會針對在更新重新整理期間內具有新日期/時間的新數據列建立新的重新整理數據分割,而重新整理期間內已有日期/時間的現有數據列會使用更新重新整理。 不再重新整理日期/時間超過重新整理期間的數據列。
當整個期間關閉時,分割區會合併。 例如,如果在原則中指定了一天重新整理期間和三年的歷史存放區期間,則當月的第一天,前一個月的所有日分割都會合併成月份分割區。 在新季度的第一天,所有前三個月的分割區都會合併成四分之一數據分割。 在新年的第一天,前四個季度數據分割都會合併成一年分割區。
模型一律會保留整個歷程記錄存放區期間的數據分割,以及整個期間的數據分割在目前的重新整理期間。 在此範例中,2018年、2019年、2020 年,以及 2021Q101 個月期間、2021Q10201 天期間和目前日期重新整理期間分割的數據分割中會保留整整三年的歷史數據。 因為此範例會保留三 年的歷程記錄數據,因此 2018 分割區會保留到 2022 年 1 月 1 日的第一次重新整理為止。
使用 Power BI 累加式重新整理和即時數據,服務會根據原則為您處理數據分割管理。 雖然服務可以為您處理所有分割區管理,但透過 XMLA 端點使用工具,您可以選擇性地個別、循序或平行地重新整理分割區。
使用 SQL Server Management Studio 重新整理管理
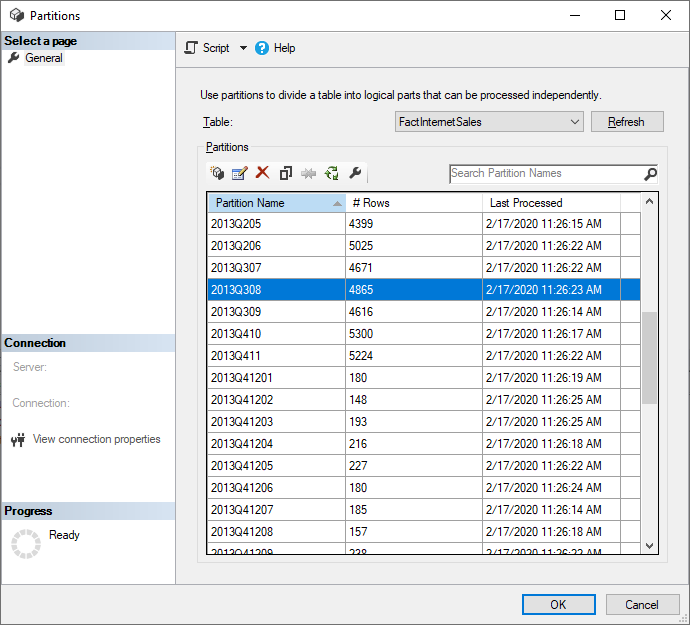
SQL Server Management Studio (SSMS) 可用來檢視和管理累加式重新整理原則應用程式所建立的數據分割。 例如,藉由使用 SSMS,您可以重新整理不在累加式重新整理期間內的特定歷程數據分割,以執行備份的更新,而不需要重新整理所有歷程記錄數據。 在啟動載入以累加方式新增/重新整理歷程記錄數據分割,以批次方式載入大型模型的歷程記錄數據時,也可以使用 SSMS。
覆寫累加式重新整理行為
使用 SSMS,您也可以更充分掌控如何使用表格式模型腳本語言和表格式物件模型來叫用重新整理。 例如,在 SSMS 的 物件總管 中,以滑鼠右鍵按單擊數據表,然後選取 [處理資料表] 選單選項,然後選取 [腳本] 按鈕以產生TMSL重新整理命令。
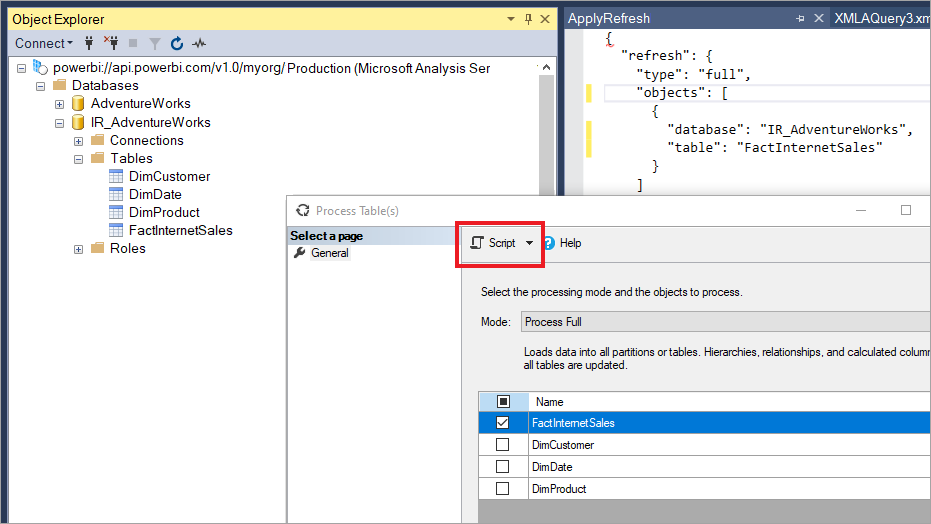
這些參數可以搭配TMSL重新整理命令使用,以覆寫預設累加式重新整理行為:
applyRefreshPolicy。 如果數據表已定義累加式重新整理原則,
applyRefreshPolicy則判斷是否已套用原則。 如果未套用原則,進程完整作業會讓分割區定義保持不變,而且數據表中的所有分割區都會完全重新整理。 預設值為 True。effectiveDate。 如果套用累加式重新整理原則,它必須知道目前的日期,以判斷累加式重新整理和歷程記錄週期的輪流視窗範圍。 參數
effectiveDate可讓您覆寫目前的日期。 此參數適用於測試、示範和商務案例,例如,數據在過去或未來以累加方式重新整理到日期,例如未來預算。 預設值為目前的日期。
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
若要深入瞭解如何使用TMSL覆寫默認累加式重新整理行為,請參閱 Refresh命令。
確保最佳效能
每次重新整理作業時,Power BI 服務 可能會將初始化查詢傳送至每個累加式重新整理數據分割的數據源。 您可以藉由確保下列設定來減少初始化查詢數目,以改善累加式重新整理效能:
- 您為 設定累加式重新整理的數據表應該會從單一數據源取得數據。 如果數據表從多個數據源取得數據,則服務針對每個重新整理作業所傳送的查詢數目乘以數據源數目,可能會降低重新整理效能。 請確定累加式重新整理數據表的查詢適用於單一數據源。
- 針對同時累加式重新整理匯入數據分割和使用直接查詢的實時數據的解決方案, 所有分割 區都必須從單一數據源查詢數據。
- 如果您的安全性需求允許,請將 [數據源隱私權等級] 設定為 [組織] 或 [公用]。 根據預設,隱私權層級為 Private,不過此層級可以防止數據與其他雲端來源交換。 若要設定隱私權層級,請選取 [更多選項] 功能表,然後選擇 [設定> 數據源認證>編輯>認證 此數據源的隱私權層級設定。 如果在發佈至服務之前,Power BI Desktop 模型中已設定隱私權等級,則不會在發佈時傳送至服務。 您必須在服務中的語意模型設定中加以設定。 若要深入瞭解,請參閱 隱私權層級。
- 如果使用內部部署數據閘道,請務必使用 3000.77.3 版或更高版本。
防止初始完整重新整理時逾時
發佈至 Power BI 服務 之後,模型的初始完整重新整理作業會建立累加式重新整理數據表的數據分割、載入,以及處理累加式重新整理原則中定義之整個期間的歷史數據。 對於載入和處理大量數據的某些模型,初始重新整理作業所花費的時間量可能會超過服務所加加的重新整理時間限制或數據源所加加的查詢時間限制。
啟動載入初始重新整理作業可讓服務建立累加式重新整理數據表的數據分割物件,但不會將歷程記錄數據載入到任何數據分割中。 SSMS 接著會用來選擇性地處理分割區。 根據每個分割區要載入的數據量,您可以循序處理每個分割區,或以小型批次處理,以減少一或多個分割區造成逾時的可能性。 下列方法適用於任何數據源。
套用重新整理原則
開放原始碼 表格式編輯器 2 工具提供簡單的方法來啟動初始重新整理作業。 使用從 Power BI Desktop 為其定義的累加式重新整理原則發佈模型至服務之後,請使用讀取/寫入模式中的 XMLA 端點連接到模型。 在累加式重新整理數據表上執行 套用重新整理原則 。 僅套用原則時,會建立分割區,但不會將數據載入其中。 然後與 SSMS 連線,以循序或批次方式重新整理分割區,以載入和處理數據。 如需詳細資訊,請參閱 表格式編輯器檔中的累加式重新 整理。
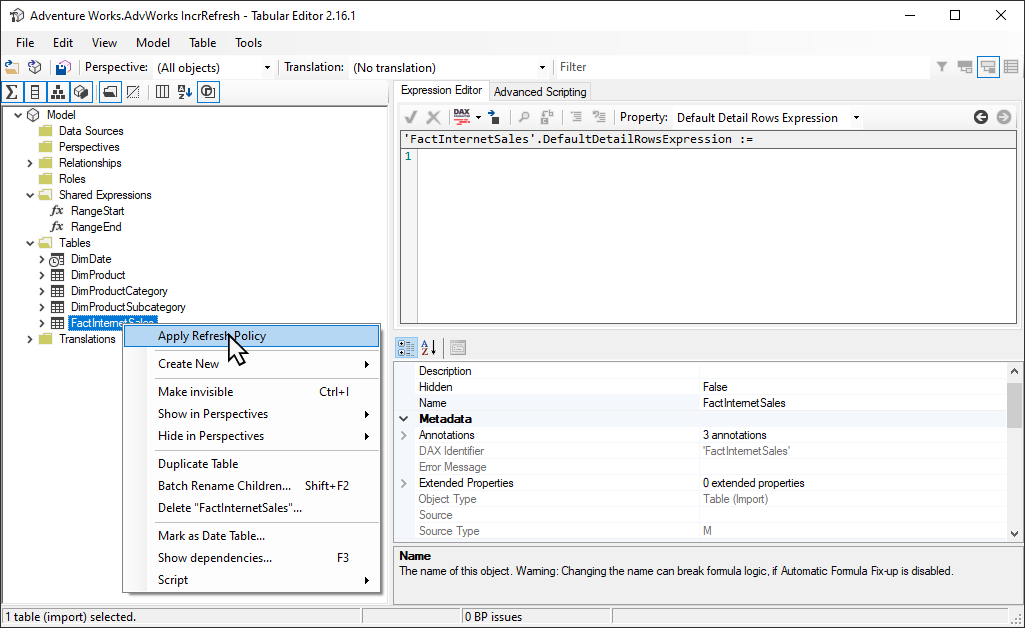
空白數據分割的 Power Query 篩選
在將模型發佈至服務之前,在 Power Query 編輯器 中,將另一個篩選新增至ProductKey數據行,以篩選出0以外的任何值,或從 FactInternetSales 資料表篩選出所有數據。
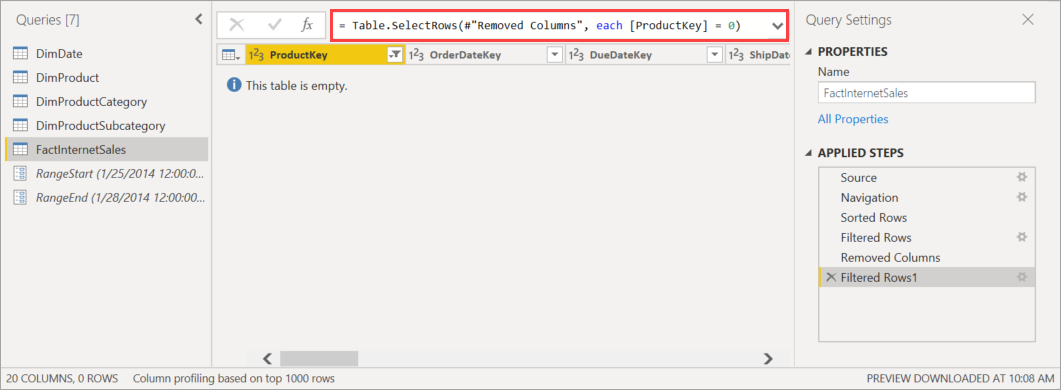
在 Power Query 編輯器 中選取 [關閉和套用] 之後,定義累加式重新整理原則,然後儲存模型,模型就會發佈至服務。 從服務中,初始重新整理作業會在模型上執行。 FactInternetSales 數據表的數據分割會根據原則建立,但不會載入和處理任何數據,因為所有數據都會篩選掉。
初始重新整理作業完成之後,回到 Power Query 編輯器,就會移除數據行的其他ProductKey篩選。 在 Power Query 編輯器 中選取 [關閉及套用] 並儲存模型之後,不會再次發佈模型。 如果再次發佈模型,它會覆寫累加式重新整理原則設定,並在從服務執行後續重新整理作業時強制重新整理模型的完整重新整理。 相反地,只使用應用程式生命週期管理 (ALM) 工具組執行元數據部署,以從模型移除數據行上的ProductKey篩選。 接著,SSMS 可用來選擇性地處理分割區。 當所有分割區都已完整處理時,它必須包含所有分割區的進程重新計算,從 SSMS,從服務重新整理模型上的後續重新整理作業只會重新整理累加式重新整理數據分割。
若要深入瞭解如何處理 SSMS 中的數據表和數據分割,請參閱處理資料庫、數據表或分割區(Analysis Services)。 若要深入瞭解如何使用TMSL處理模型、數據表和數據分割,請參閱Refresh命令 (TMSL)。
用於偵測數據變更的自定義查詢
TMSL 和 TOM 可用來覆寫偵測到的數據變更行為。 此方法不僅可以用來避免在記憶體內部快取中保存上次更新數據行,還可以啟用透過擷取、轉換和載入 (ETL) 進程準備組態或指令表的案例,只標記需要重新整理的數據分割。 這個方法可以建立更有效率的累加式重新整理程式,而不論數據更新發生多久前,只會重新整理所需的期間。
pollingExpression是輕量型 M 運算式或另一個 M 查詢的名稱。 它必須傳回純量值,而且會針對每個分割區執行。 如果傳回的值與上次發生累加式重新整理時的值不同,分割區會標示為完整處理。
下列範例涵蓋過去期間所有 120 個月的備份變更。 指定120個月而不是10年表示數據壓縮可能不太有效率,但避免重新整理整個歷史年份,當一個月足以進行備份變更時,這會更昂貴。
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
僅限元數據部署
將新版本的 .pbix 檔案從 Power BI Desktop 發佈至工作區時,如果已有相同名稱的模型存在,系統會提示您取代現有的模型。
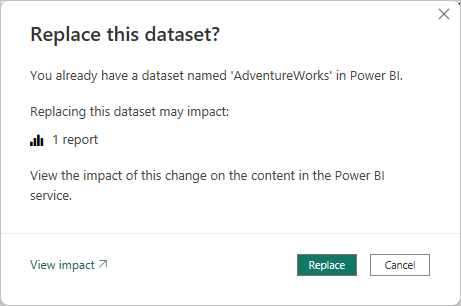
在某些情況下,您可能不想取代模型,特別是使用累加式重新整理。 Power BI Desktop 中的模型可能比 Power BI 服務 中的模型小得多。 如果 Power BI 服務 中的模型已套用累加式重新整理原則,則如果取代模型,可能會遺失數年的歷史數據。 重新整理所有歷程記錄數據可能需要數小時的時間,並導致使用者的系統停機。
相反地,最好只執行元數據部署,以允許部署新的物件,而不會遺失歷程記錄數據。 例如,如果您已新增一些量值,您就只能部署新的量值,而不需要重新整理數據,節省時間。
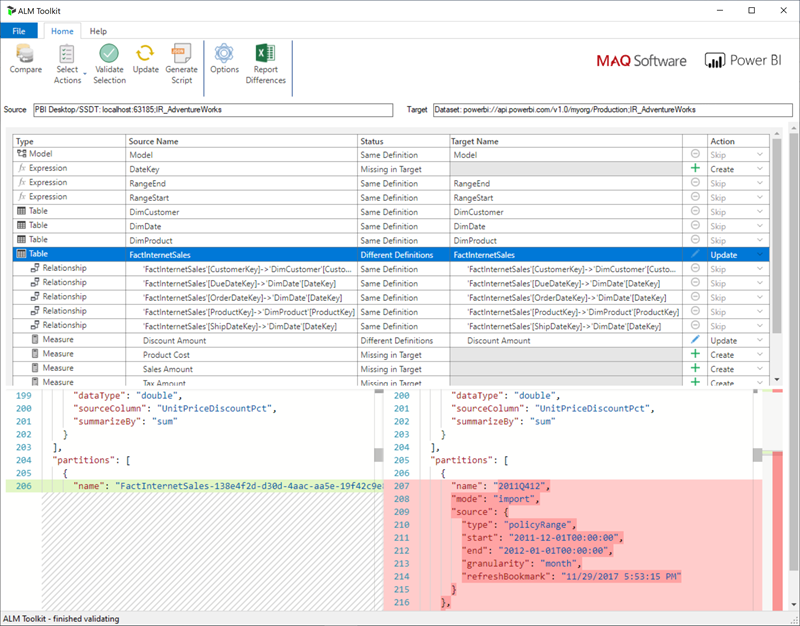
針對指派給已針對 XMLA 端點讀取/寫入所設定之 進階版 容量的工作區,相容工具只會啟用元數據部署。 例如,ALM 工具組是Power BI模型的架構差異工具,只能用來執行元數據的部署。
從 Analysis Services Git 存放庫下載並安裝最新版的 ALM 工具組。 使用 ALM 工具組的逐步指引並未包含在 Microsoft 檔中。 [說明] 功能區提供 ALM 工具組文件連結和支援性資訊。 若要執行僅限元數據部署,請執行比較並選取執行中的Power BI Desktop實例作為來源,並將 Power BI 服務中的現有模型選取為目標。 請考慮顯示的差異,並使用累加式重新整理分割區略過數據表更新,或使用 [ 選項 ] 對話方塊來保留資料表更新的數據分割。 驗證選取專案,以確保目標模型的完整性,然後更新。
以程序設計方式新增累加式重新整理原則和實時數據
您也可以使用TMSL和 TOM,透過 XMLA 端點將累加式重新整理原則新增至現有的模型。
注意
若要避免相容性問題,請確定您使用最新版的 Analysis Services 用戶端連結庫。 例如,若要使用混合式原則,版本必須是 19.27.1.8 或更高版本。
此程式包含下列步驟:
確定目標模型具有所需的最低相容性層級。 在 SSMS 中,以滑鼠右鍵按兩下 [模型名稱]>[屬性>相容性層級]。 若要增加相容性層級,請使用 createOrReplace TMSL 腳本,或檢查下列 TOM 範例程式代碼以取得範例。
a. Import policy - 1550 b. Hybrid policy - 1565將
RangeStart和RangeEnd參數新增至模型表達式。 如有必要,也新增函式,將日期/時間值轉換為日期索引鍵。RefreshPolicy使用所需的封存(滾動視窗)和累加式重新整理期間,以及根據 和RangeEnd參數篩選目標數據表RangeStart的來源表達式,定義物件。 根據您的實時數據需求,將重新整理原則模式設定為 [匯 入] 或 [混合式 ]。 混合式會導致 Power BI 將 DirectQuery 分割區新增至數據表,從上次重新整理時間之後發生的數據源擷取最新的變更。將重新整理原則新增至數據表並執行完整重新整理,讓 Power BI 根據您的需求分割數據表。
下列程式代碼範例示範如何使用 TOM 執行先前的步驟。 如果您想要依原樣使用此範例,則必須有 AdventureWorksDW 資料庫的複本,並將 FactInternetSales 數據表匯入模型。 程式代碼範例假設 RangeStart 和 RangeEnd 參數和 DateKey 函式不存在於模型中。 只要匯入 FactInternetSales 數據表,並將模型發佈至 Power BI 上的工作區 進階版。 然後更新 workspaceUrl ,讓程式代碼範例可以連線到您的模型。 視需要更新任何其他程式碼行。
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}