Power Query 功能,例如 模糊合併、 叢集值和 模糊群組 ,會使用相同的機制來運作為模糊比對。
本文介紹了許多場景,這些場景演示瞭如何利用模糊匹配的選項,目的是使“模糊”變得清晰。
備註
雖然叢集值選項僅適用於 Power Query Online,但本節中顯示的機制也適用於模糊合併和模糊群組。
調整相似性臨界值
套用模糊比對演算法的最佳案例是,當直欄中的所有文字字串只包含需要比較的字串,而沒有額外的元件時。 例如,與 進行Apples比較會產生4ppl3s比與 Apples比較更高的My favorite fruit, by far, is Apples. I simply love them!相似性分數。
因為第二個字串中的單字 Apples 只是整個文字字串的一小部分,所以這種比較會產生較低的相似性分數。
例如,下列資料集包含只有一個問題的調查問卷的回應:「你最喜歡的水果是什麼?」
| 水果 |
|---|
| 藍莓 |
| 藍色漿果簡直是最好的 |
| 草莓 |
| 草莓 = <3 |
| Apples |
| 'sples |
| 4人3秒 |
| 香蕉 |
| 最喜歡的水果是香蕉 |
| 巴納斯 |
| 到目前為止,我最喜歡的水果是蘋果。 我簡直喜歡他們! |
該調查提供了一個文本框來輸入值,並且沒有驗證。
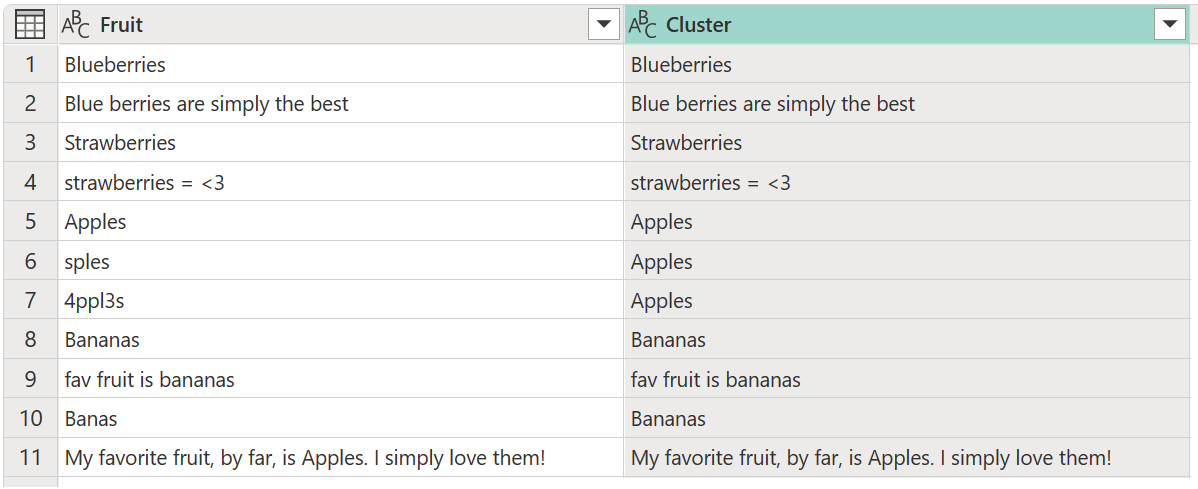
現在您的任務是對值進行聚類。 若要執行該工作,請將上一個水果表載入 Power Query,選取資料行,然後在功能區的 [新增資料行] 索引標籤中選取 [叢集值] 選項。
![]()
叢集 值 對話方塊隨即出現,您可以在其中指定新資料行的名稱。 將此新資料行命名為 [叢集] ,然後選取 [確定]。
![選取 [水果] 欄後叢集值對話方塊的螢幕擷取畫面。新的資料行名稱欄位會設定為叢集。](media/fuzzy-matching/cluster-values-default-window.png)
根據預設,Power Query 會使用 0.8 (或 80%的相似性臨界值。 最小值 0.00 會導致具有任何相似程度的所有值彼此匹配,而最大值 1.00 只允許完全匹配。 模糊的「完全匹配」可能會忽略大小寫、詞序和標點符號等差異。 上一個作業的結果會產生下表,其中包含新的 叢集資料 行。
叢集完成時,不會提供所有資料列的預期結果。 第二 (2) 列仍具有值 Blue berries are simply the best,但應該叢集為 Blueberries,且文字字串 Strawberries = <3、 fav fruit is bananas和 My favorite fruit, by far, is Apples. I simply love them!也會發生類似的情況。
若要判斷造成此叢集的原因,請按兩下「套用的步驟」面板中的「叢集值」,以帶回「叢集值」對話方塊。 在此對話方塊中,展開 模糊叢集選項。 啟用 [顯示相似性分數] 選項,然後選取 [確定]。
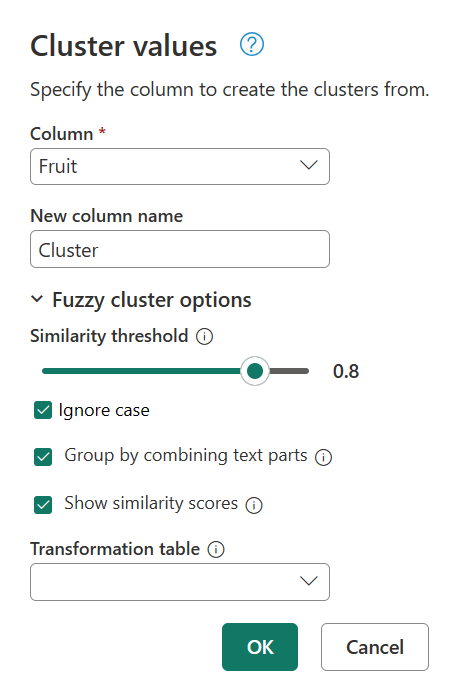
啟用 顯示相似性分數 選項會在表格中建立新欄。 此直欄會顯示已定義叢集與原始值之間的確切相似性分數。

仔細檢查後,Power Query 在文字字串 Blue berries are simply the best、Strawberries = <3 和 fav fruit is bananasMy favorite fruit, by far, is Apples. I simply love them!的相似性閾值中找不到任何其他值。
按兩下「套用的步驟」面板中的「叢集值」,再次返回「叢集值」對話方塊。 將 [相似性臨界值 ] 從 0.8 變更為 0.6,然後選取 [ 確定]。
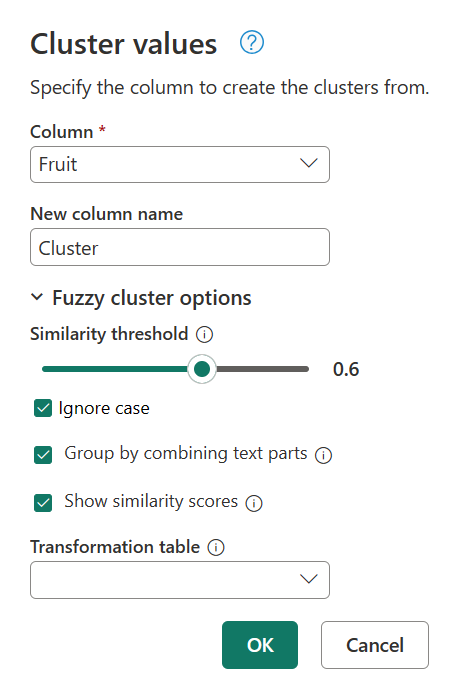
此變更可讓您更接近您要尋找的結果,但文字字串 My favorite fruit, by far, is Apples. I simply love them!除外。 當您將 相似性閾值 從 0.8 變更為 0.6 時,Power Query 現在能夠使用相似度分數從 0.6 一直到 1 的值。
![將相似性臨界值定義為 0.6 並在 [叢集] 欄中指派新值後的資料表螢幕擷取畫面。](media/fuzzy-matching/values-with-show-similarity-score-60.png#lightbox)
備註
Power Query 一律會使用最接近閾值的值來定義叢集。 臨界值會定義可接受的相似性分數下限,以將值指派給叢集。
您可以將 相似性分數 從 0.6 變更為較低的數字,直到取得所需的結果為止,再試一次。 在此情況下,請將 「相似性」分數 變更為 0.5。 此變更會產生您預期的確切結果,文字字串 My favorite fruit, by far, is Apples. I simply love them! 現在已指派給叢集 Apples。

備註
目前,只有 Power Query Online 中的 叢集值 功能會提供具有相似性分數的新資料行。
轉換表格的特殊考量
轉換表格可協助您在執行模糊比對演算法之前,將資料行中的值對應至新值。
如何使用轉換表的一些範例:
這很重要
使用轉換表格時,轉換表格中值的相似性分數上限為 0.95。 此刻意的 0.05 懲罰,是為了區分這類資料行的原始值不等於轉換發生以來所比較的值。
對於您先想要對應值,然後執行模糊比對而不造成 0.05 懲罰的案例,建議您取代資料行中的值,然後執行模糊比對。