在 Power Query 中,您可以將資料行轉換成屬性值組,其中數據行會變成數據列。
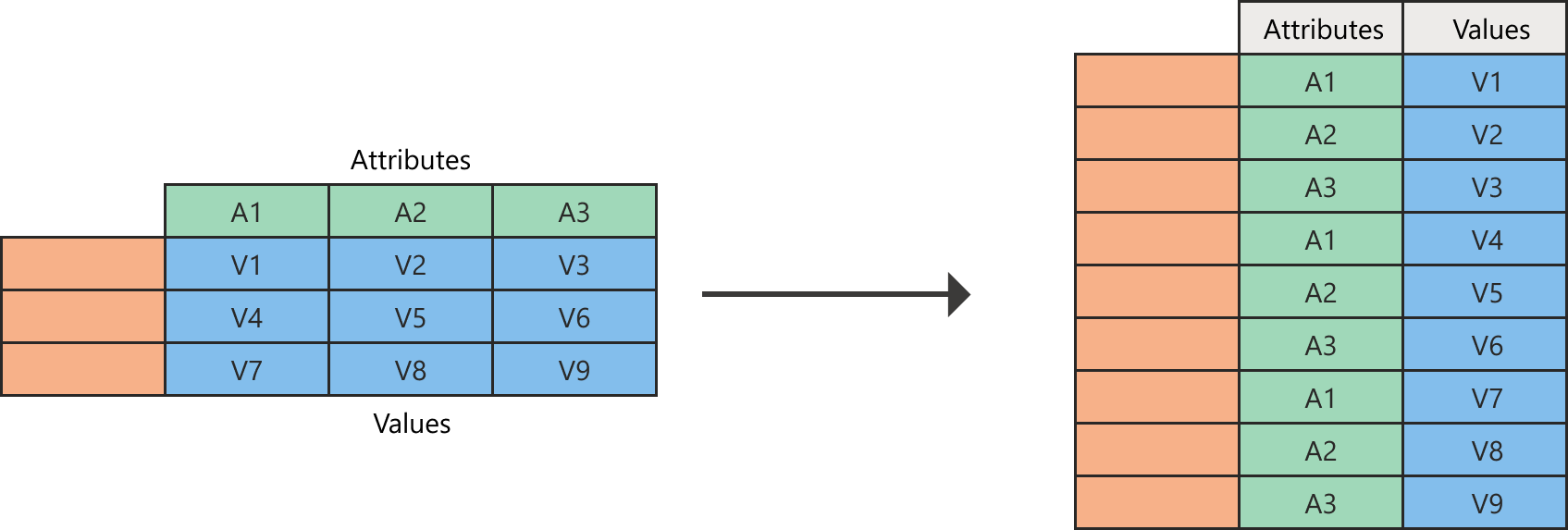
顯示左側資料表的空白資料欄和資料列,以及屬性值 A1、A2 和 A3 作為資料欄標頭的圖表。 在此表格中,A1 資料行包含 V1、V4 和 V7 的值。 A2 資料行包含 V2、V5 和 V8 值。 A3 資料列包含 V3、V6 和 V9 的值。 將欄位進行取消樞紐操作後,圖表右側的表格會包含空白的欄和行。 Attributes 資料欄也包含九列,其中 A1、A2 和 A3 各重複三次。 最後,Values 資料行包含 V1 到 V9 的值。
例如,假設有如下的數據表,其中國家/地區數據列和日期數據行會建立值的矩陣,因此很難以可調整的方式分析數據。
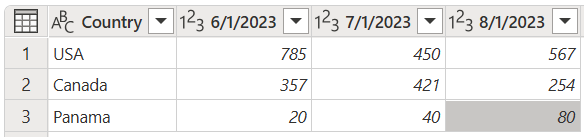
數據表的螢幕快照,其中包含 Text 數據類型中設定的 Country 數據行,以及日期為 2023 年 6 月 1 日、2023 年 7 月 1 日和 2023 年 8 月 1 日設定為整數數據類型的三個數據行。 Country 列在第 1 行包含美國,第 2 行包含加拿大,第 3 行包含巴拿馬。
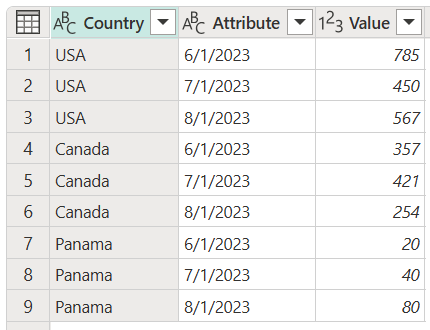
相反地,您可以將數據表轉換成具有未樞紐化的列的數據表,如以下圖像所示。 在已轉換的數據表中,比較容易使用日期做為屬性來篩選。
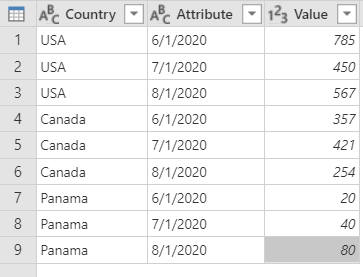
數據表的螢幕快照,其中包含一個設為文字資料類型的國家列、一個設為文字資料類型的屬性列,以及一個設為整數資料類型的值列。 Country 數據行包含美國的前三個數據列、接下來三個數據列中的加拿大,最後三個數據列包含巴拿馬。 [屬性] 欄位在第一、第四和第七行包含 2023 年 6 月 1 日的日期。 2023 年 7 月 1 日日期會出現在第二、第五和第八列。 最後,在2023年8月1日的第三個、第六個和第九個數據列中找到。
關鍵在於此轉換中,您的數據表中有一組日期,他們應該全部放在同一個欄中。 每個日期和國家/地區的個別值都應該在不同的數據行中,有效地建立屬性值組。
Power Query 一律會使用兩個數據行來建立屬性值組:
- 屬性:已解除透視的列標題名稱。
- 值:這些值位於未透視的欄標題下方。
使用者介面中有多個位置,您可以在其中找到 反透視數據行。 您可以在您想要取消樞紐分析的列上按下滑鼠右鍵,也可以從功能區中的 轉換 索引標籤選取命令。
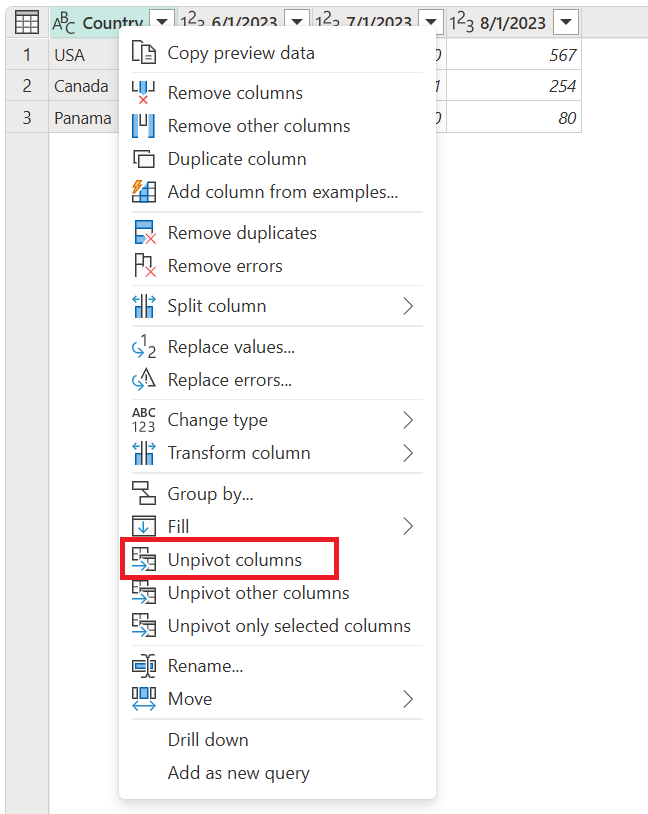
![[轉換] 索引標籤上 [取消樞紐欄] 命令的螢幕擷圖。](media/unpivot-column/unpivot-transform-tab.png)
有三種方法可以將資料表的欄位反透視:
- 取消列旋轉
- 取消樞紐分析表的其他欄
- 僅取消樞紐選取的數據行
取消樞紐欄位
針對先前所述的案例,您必須先選取想要取消透視的欄位。 您可以在選取Ctrl的同時,依需求選擇多個資料行。 在此案例中,您想要選取除名為 Country 的欄位以外的所有欄位。 選取數據行之後,以滑鼠右鍵按下任何選取的數據行,然後選取 [取消樞紐數據行]。
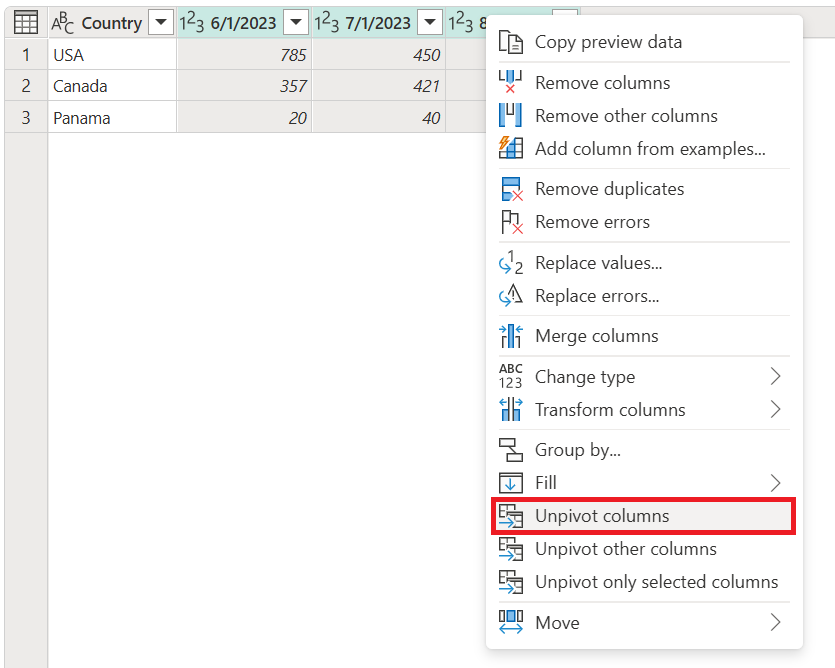
數據表的螢幕快照,其中已選取 2023 年 6 月 1 日、2023 年 7 月 1 日和 2023 年 8 月 1 日的數據行,以及快捷方式功能表中選取的 [取消樞紐數據行] 命令。
該作業的結果會產生下圖所示的結果。

特殊考慮
從先前步驟建立查詢之後,假設您的初始數據表會更新為類似下列螢幕快照。
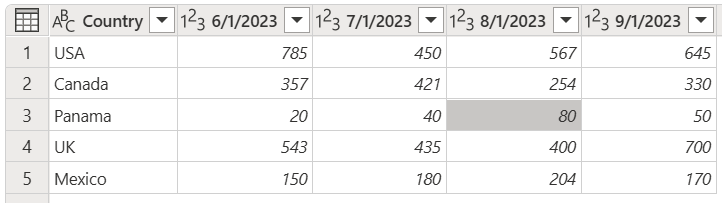
具有相同原始國家/地區的表格螢幕快照,包含2023年6月1日、2023年7月1日、2023年8月1日的日期欄,並添加了2023年9月1日日期欄。 Country 數據行仍然包含美國、加拿大和巴拿馬的值,但也已將英國新增至第四列,墨西哥則新增至第五列。
請注意,您正在新增 2023 年 9 月 1 日日期的新數據行(2023 年 9 月 1 日),以及英國和墨西哥國家/地區兩個新數據列。
如果您重新整理查詢,請注意作業是在更新的數據行上完成,但不會影響原本未選取的數據行(在此範例中為國家/地區)。 此行為表示您新增至源數據表的任何新數據行也會取消擷取。
下圖顯示使用新更新的源數據表重新整理之後,查詢的外觀。
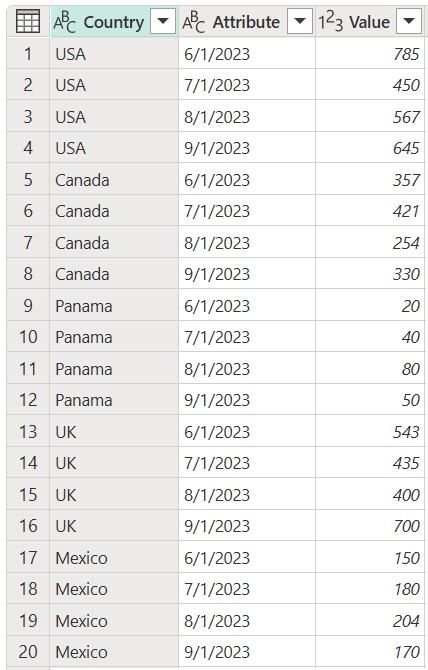
[國家/地區]、[屬性] 和 [值] 資料行的數據表螢幕快照。 Country 數據行的前四個數據列包含 USA、第二個四個數據列包含加拿大、第三個四個數據列包含巴拿馬、第四個四個數據列包含英國,而第五個四個數據列包含墨西哥。 [屬性] 欄位的前四行包含 2023 年 6 月 1 日、2023 年 7 月 1 日和 2023 年 8 月的日期,這些日期會在每個國家/地區重複出現。
取消旋轉其他欄位
您也可以選取您不想取消透視的欄,並取消表格中其餘欄的透視。 此操作為 反透視其他數據行 的用武之地。
![已選取 [國家/地區] 資料行快捷方式功能表以及強調 [取消樞紐其他數據行] 命令的數據表螢幕快照。](media/unpivot-column/unpivot-other-columns.png)
該作業的結果會產生與您從 Unpivot 資料行取得的結果完全相同。
數據表的螢幕快照,其中包含一個設為文字資料類型的國家列、一個設為文字資料類型的屬性列,以及一個設為整數資料類型的值列。 Country 數據行包含美國的前三個數據列、接下來三個數據列中的加拿大,最後三個數據列包含巴拿馬。 [屬性] 欄位在第一、第四和第七行包含 2023 年 6 月 1 日的日期。 2023 年 7 月 1 日日期在第二、第五和第八列。 2023 年 8 月 1 日日期會出現在第三、第六和第九個數據列。
備註
此轉換對於具有未知數據行數目的查詢而言非常重要。 此操作會將您的數據表中所有欄位解除樞紐,但您所選取的欄位除外。 如果案例的數據源在重新整理中取得新的日期數據行,則此轉換類型是理想的解決方案,因為這些新數據行會挑選並取消擷取。
特殊考慮
類似於 反透視欄位 作業,如果重新整理查詢並從數據來源中獲取更多數據,則會反透視所有欄位,除了先前選取的欄位。
為了說明此程式,假設您有類似下圖中的新數據表。
表格的螢幕擷取畫面,其包含「國家」、2023 年 6 月 1 日、2023 年 7 月 1 日、2023 年 8 月 1 日和 2023 年 9 月 1 日等欄,所有欄位均設定為 Text 數據類型。 Country 欄包含美國、加拿大、巴拿馬、英國和墨西哥,從上到下。
您可以選取 國家 欄,然後選取 取消旋轉其他欄,這會產生下列結果。
[國家/地區]、[屬性] 和 [值] 資料行的數據表螢幕快照。 Country 和 Attribute 資料行會設定為 Text 數據類型。 Value 資料行會設定為 [整數] 值數據類型。 Country 數據行的前四個數據列包含 USA、第二個四個數據列包含加拿大、第三個四個數據列包含巴拿馬、第四個四個數據列包含英國,而第五個四個數據列包含墨西哥。 屬性欄包含 2023 年 6 月 1 日、2023 年 7 月 1 日、2023 年 8 月 1 日和 2023 年 9 月 1 日,這四個日期在每個國家/地區的前四行中重複。
僅轉置選取的欄位
最後一個選項的目的是只取消數據表中的特定數據行。 此選項對於您處理數據源中未知資料行數目的案例而言很重要。 它可讓您只取消樞紐選取的數據行。
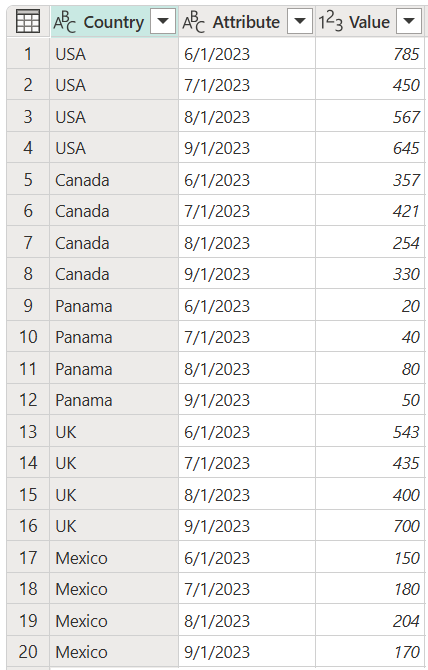
若要執行這項作業,請選取要反樞紐分析的欄,在此範例中為Country以外的所有欄。 然後以滑鼠右鍵按下您選取的任何欄位,然後選取 僅旋轉選取的欄位。
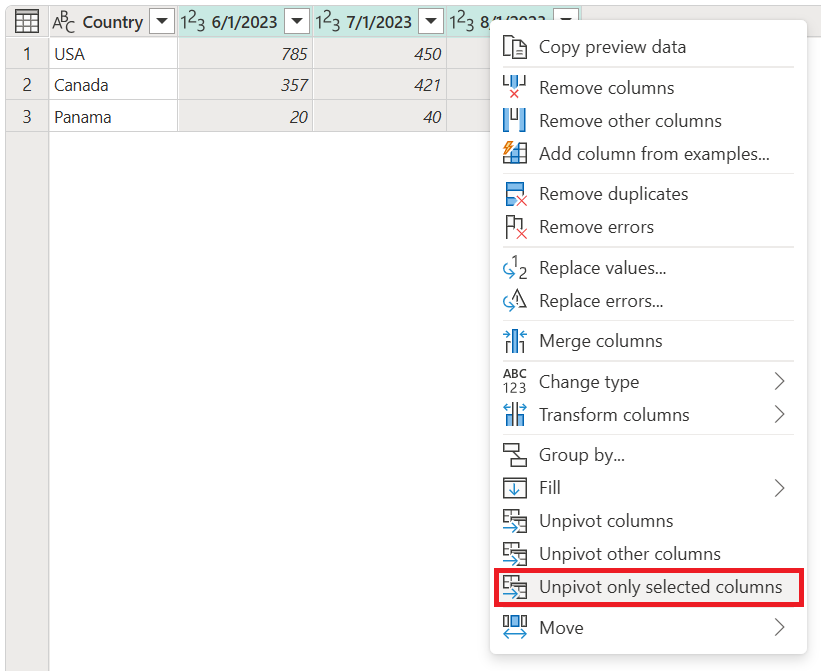
請注意此作業如何產生與先前範例相同的輸出。
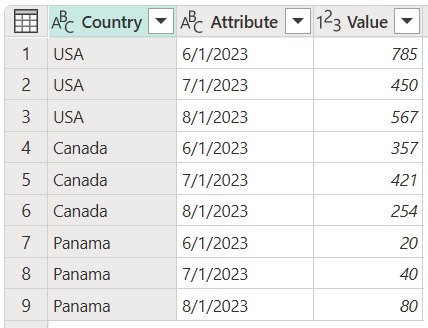
數據表的螢幕快照,其中包含一個設為文字資料類型的國家列、一個設為文字資料類型的屬性列,以及一個設為整數資料類型的值列。 Country 數據行包含美國的前三個數據列、接下來三個數據列中的加拿大,最後三個數據列包含巴拿馬。 [屬性] 欄位在第一、第四和第七行包含 2023 年 6 月 1 日的日期。 2023 年 7 月 1 日日期在第二、第五和第八列。 2023 年 8 月 1 日日期會出現在第三、第六和第九個數據列。
特殊考慮
重新整理之後,如果我們的源數據表變更為有新的 9/1/2020 數據行,以及英國和墨西哥的新數據列,則查詢的輸出與先前的範例不同。 假設在重新整理之後,我們的源數據表會變更為下圖中的數據表。
查詢的輸出看起來像下圖。
![[僅將選擇的欄位取消樞紐] 已更新最終表格的螢幕截圖。](media/unpivot-column/unpivot-only-selected-columns-updated-final-table.png)
這看起來會如此,是因為非旋轉操作只套用了於 2020 年 6 月 1 日、2020 年 7 月 1 日 和 2020 年 8 月 1 日 的欄位,所以標題為 2020 年 9 月 1 日 的欄位保持不變。