適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
MICROSOFT SQL Server 2019 巨量數據叢集已淘汰。 SQL Server 2019 巨量數據叢集的支援已於 2025 年 2 月 28 日結束。 如需詳細資訊,請參閱 Microsoft SQL Server 平臺上的公告部落格文章和巨量數據選項。
SQL Server 提供 Azure Data Studio 的擴充功能,其中包含部署筆記本。 部署筆記本包含可在 Azure Data Studio 中用來建立 SQL Server 巨量數據叢集的文件和程式代碼。
一開始實作為開放原始碼專案, 筆記本 已實作至 Azure Data Studio。 您可以將 Markdown 用於文字儲存格中的文字,並使用可用的核心之一在程式碼儲存格中撰寫程式碼。
您可以使用筆記本來部署 SQL Server 巨量數據叢集。
Prerequisites
需要下列必要條件,才能同時啟動筆記本:
- 已安裝最新版的 Azure Data Studio 內部版本
除了上述專案外,部署巨量數據叢集也需要:
啟動筆記本
啟動 Azure Data Studio。
在 [ 連線] 索引標籤上,選取省略號 (...),然後選取 [部署 SQL Server...]。
從部署選項中,選取 [SQL Server 巨量數據叢集]。
從 [部署目標] 的 [ 選項] 底下,選取 [新增 Azure Kubernetes 叢集 ] 或 [ 現有的 Azure Kubernetes Service 叢集]。
接受隱私權和授權條款。
此對話框也會檢查主機上是否有所選 SQL 部署類型所需的工具。 在工具檢查成功之前,不會啟用 [ 選取 ] 按鈕。
選取 [選擇] 按鈕。 此動作會啟動部署體驗。
設定部署組態範本
您可以遵循下列指示來自訂部署設定的設定。
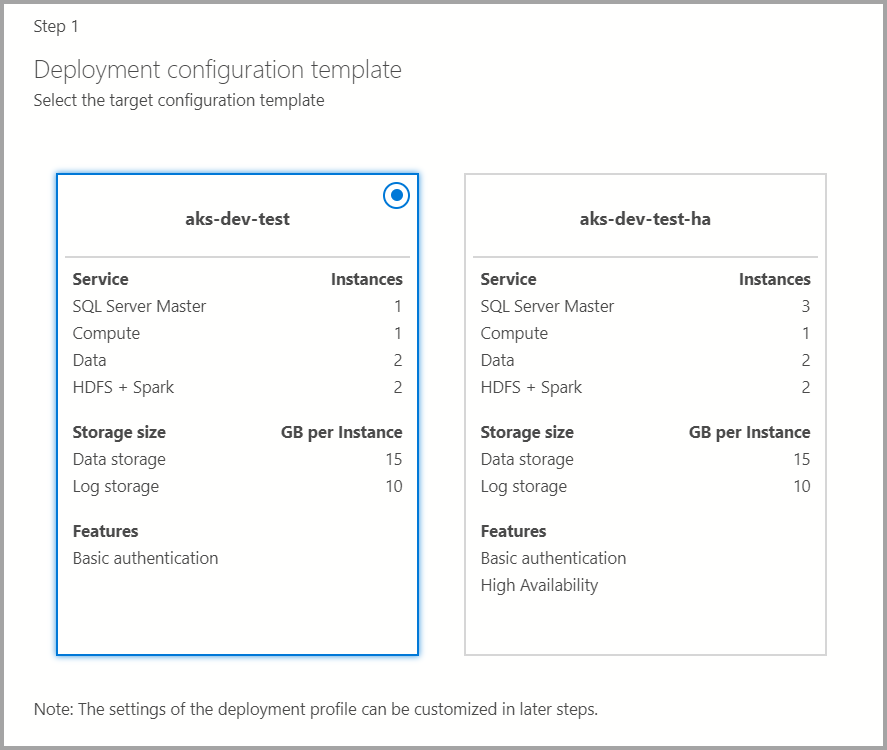
目標組態範本
從可用的範本中選取目標組態範本。 可用的設定檔會根據上一個對話框中所選擇的部署目標類型進行篩選。
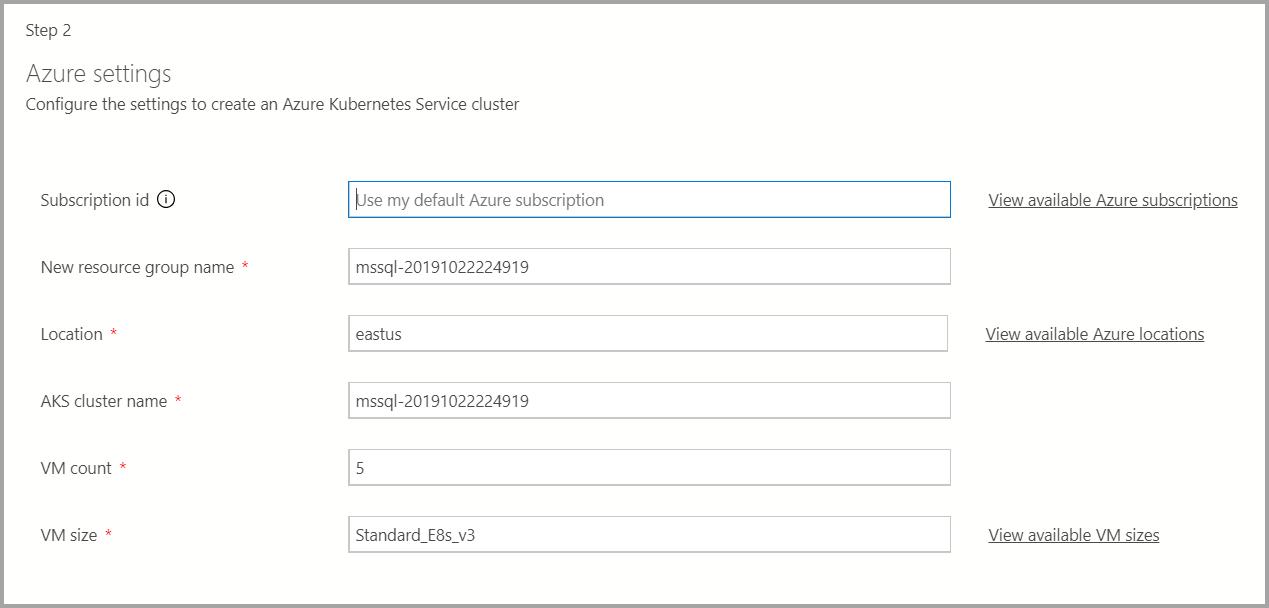
Azure settings
如果部署目標是新的 Azure Kubernetes Service (AKS),則需要其他資訊,例如 Azure 訂用帳戶標識符、資源群組、AKS 叢集名稱、VM 計數、大小和其他資訊,才能建立 AKS 叢集。
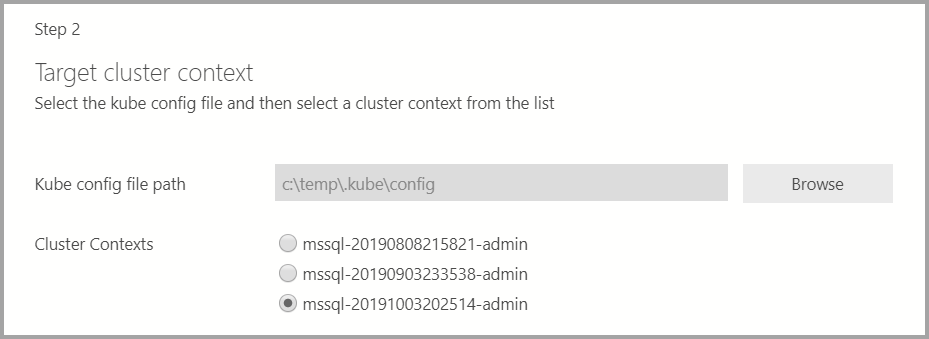
如果部署目標是現有的 Kubernetes 叢集,精靈會提示 kube 組態檔的路徑以匯入 Kubernetes 叢集設定。 確定已選取適當的叢集內容,其中可以部署 SQL Server 2019 巨量數據叢集。
叢集、Docker 和 AD 設定
輸入巨量數據叢集的叢集名稱、系統管理員使用者名稱和密碼。 這個帳戶同時用於控制器和 SQL Server。
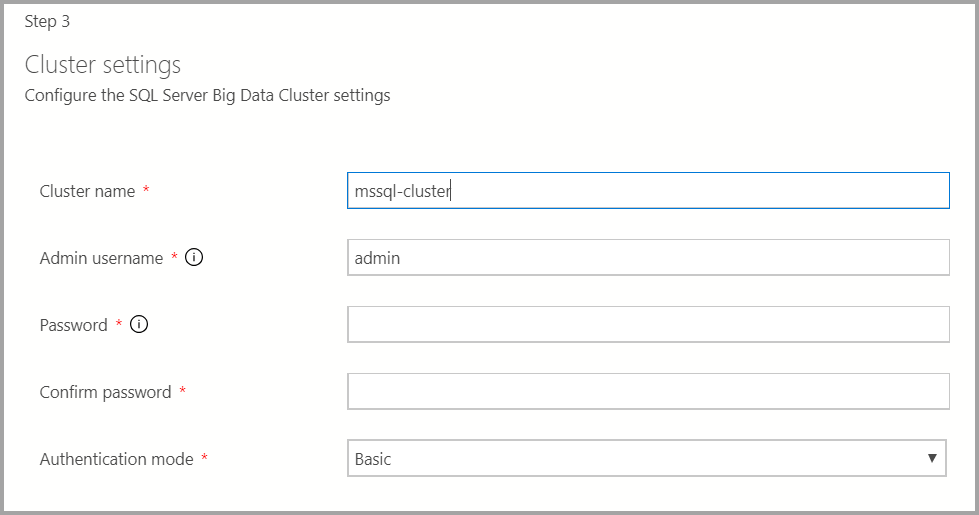
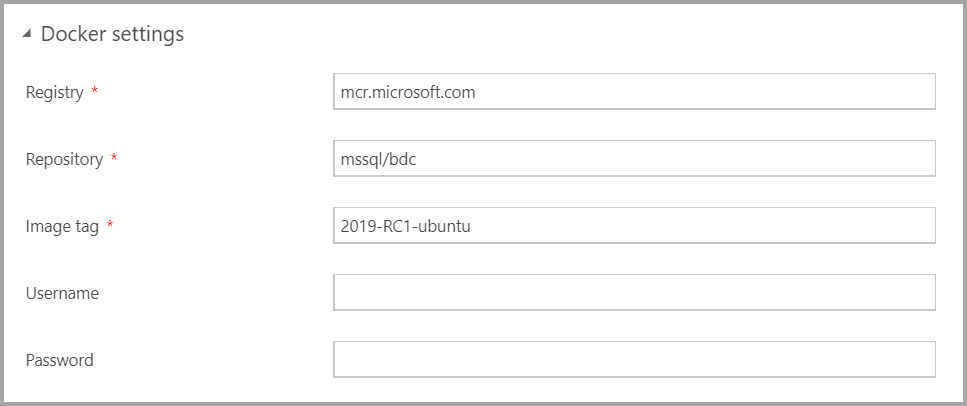
視需要輸入 Docker 設定。
Important
確定影像卷標欄位是最新的: 2019-CU13-ubuntu-20.04
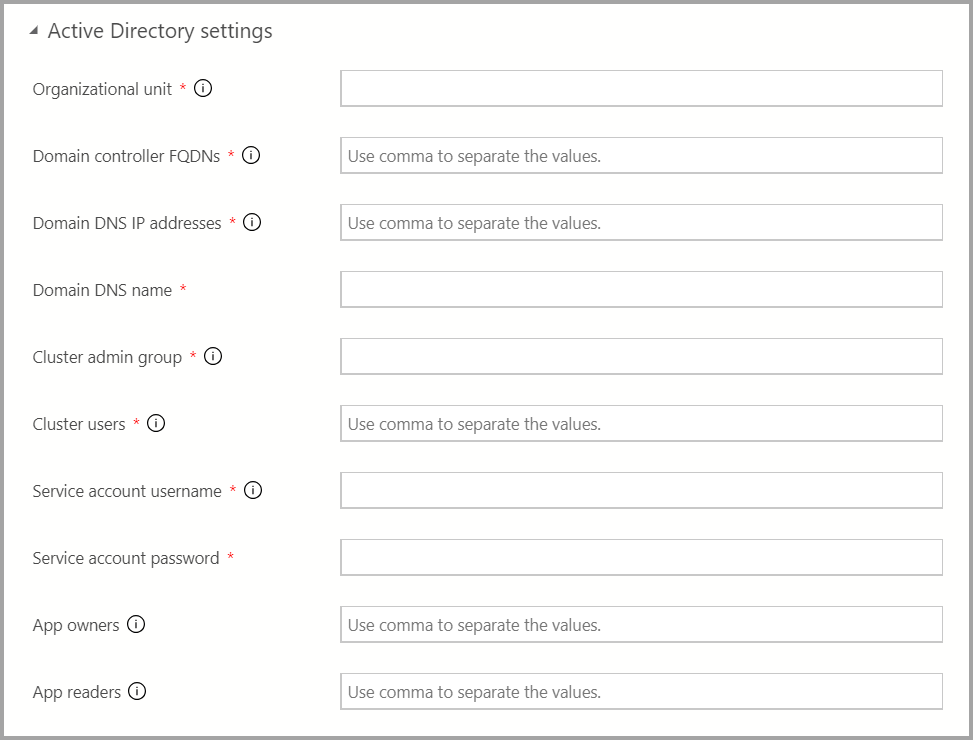
如果 AD 驗證可用,請輸入 AD 設定。
Service settings
此畫面有各種設定的輸入,例如 調整、 端點、 記憶體和其他 進階記憶體設定。 輸入適當的值,然後選取 [ 下一步]。
Scale settings
輸入巨量數據叢集中每個元件的實例數目。
Spark 實例可以與 HDFS 一起包含。 它包含在存放集區中,或單獨在 Spark 集區中。
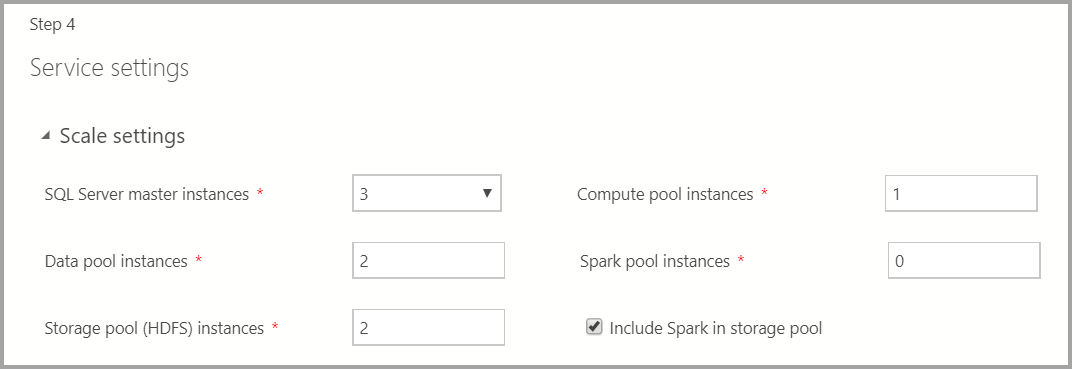
如需每個元件的其他資訊,您可以參考 主要實例、 數據集區、 存放集區或 計算集區。
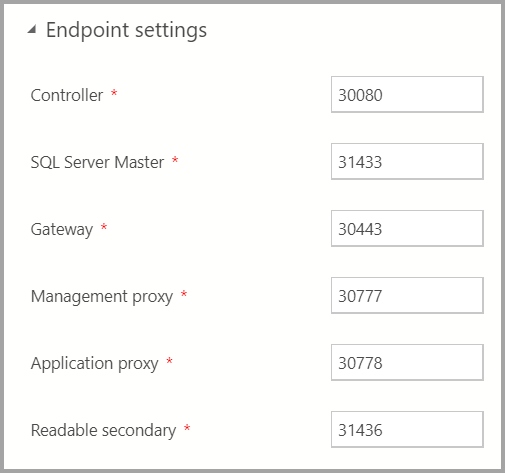
Endpoint settings
默認端點已預先填入。 不過,您可以視需要變更它們。
Storage settings
儲存設定包括資料和日誌的儲存類別和要求大小。 這些設定可以套用到記憶體、數據和 SQL Server 主要集區。

進階記憶體設定
您可以在 [進階記憶體設定] 底下新增其他記憶體設定
存放集區 (HDFS)
Data pool
SQL Server Master

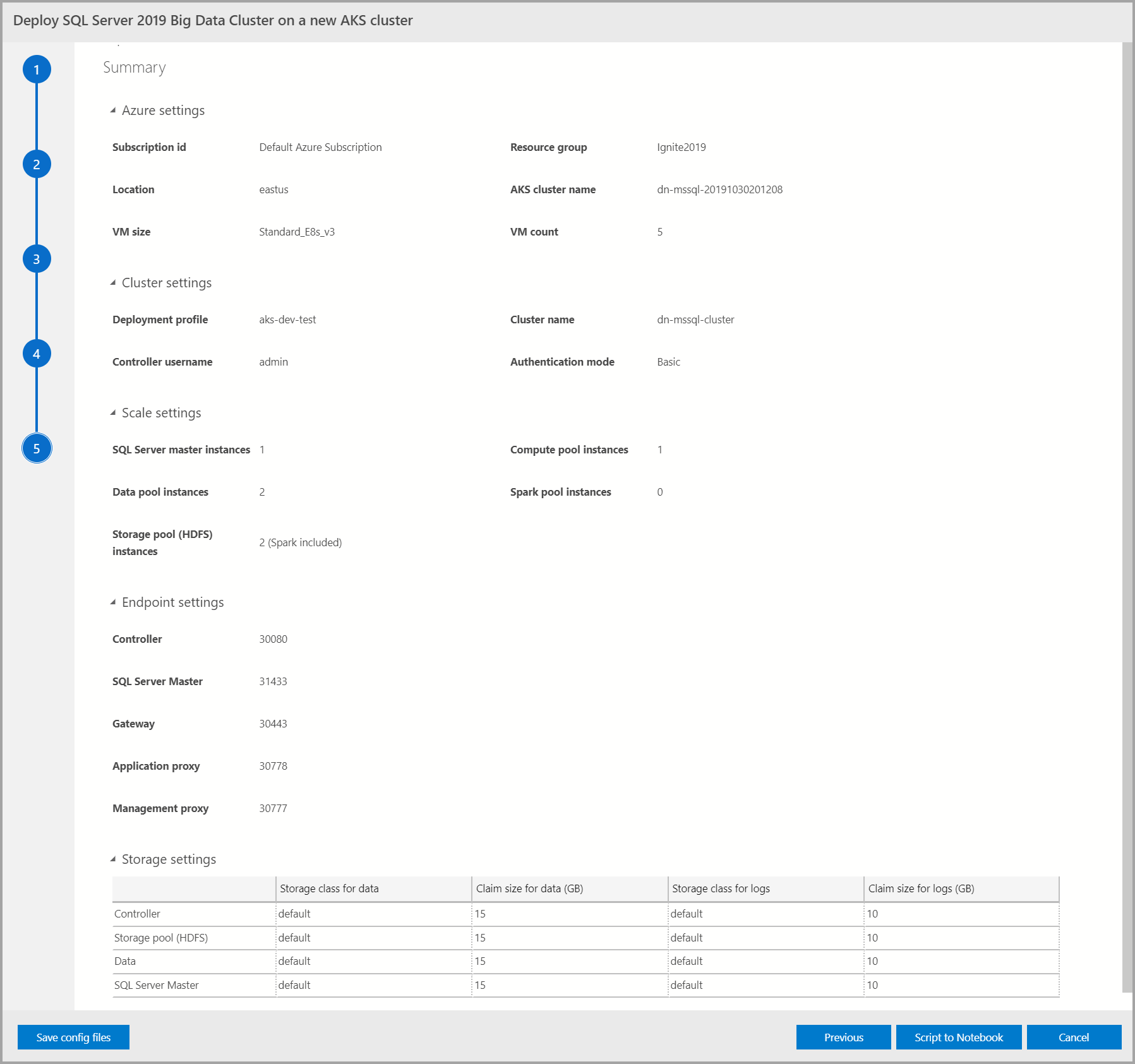
Summary
此畫面摘要說明用來部署巨量數據叢集的所有輸入。 您可以透過 [儲存設定檔] 按鈕下載 組態檔 。 選取 「腳本到筆記本」,將整個部署配置轉換成筆記本中的腳本。 一旦記事本開啟,請選取 [ 執行格 ] 以開始將大數據叢集部署到選取的目標。
Next steps
如需部署的詳細資訊,請參閱 SQL Server 巨量數據叢集的部署指引。