適用於:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) on Linux
SQL Server 2019 (15.x) on Linux
當您在機器學習服務 (資料庫內) 安裝中包含 Python 選項時,Python 整合便可在 SQL Server 2017 及更新版中提供使用。
注意
此文章目前僅適用於:適用於 Linux 的 SQL Server 2016 (13.x)、SQL Server 2017 (14.x)、SQL Server 2019 (15.x) 與 SQL Server 2019 (15.x)。
若要開發及部署適用於 SQL Server 的 Python 解決方案,請在您的開發工作站上安裝 Microsoft 的 revoscalepy \(英文\) 及其他 Python 程式庫。 同時也位於遠端 SQL Server 執行個體上的 revoscalepy 程式庫,會協調兩個系統之間的計算要求。
在此文章中了解如何設定 Python 開發工作站,使您可以與已啟用機器學習和 Python 整合的遠端 SQL Server 互動。 在完成此文章中的步驟之後,您將會有與 SQL Server 上相同的 Python 程式庫。 您也會知道如何將本機 Python 工作階段的計算推送到 SQL Server 上的遠端 Python 工作階段。
若要驗證安裝,您可以使用此文章中所述的內建 Jupyter Notebook,或是將程式庫連結到 PyCharm 或您平常使用的任何其他 IDE。
提示
如需這些練習的影片示範,請參閱從 Jupyter Notebook 在 SQL Server 中遠端執行 R 和 Python \(英文\)。
常用工具
無論您是不熟悉 SQL 的 Python 開發人員,還是不熟悉 Python 及資料庫內分析的 SQL 開發人員,您都會需要 Python 開發工具和 T-SQL 查詢編輯器 (例如 SQL Server Management Studio (SSMS)) 來執行資料庫內分析的所有功能。
針對 Python 開發,您可以使用 Jupyter Notebook,此應用程式會隨附於由 SQL Server 所安裝的 Anaconda 發行版本之中。 此文章說明如何啟動 Jupyter Notebook,使您可以從本機或在 SQL Server 上遠端執行 Python 程式碼。
SSMS 是個別的下載,很適合用來建立及執行 SQL Server 上的預存程序,包括那些包含 Python 程式碼的預存程序。 您在 Jupyter Notebook 中撰寫的 Python 程式碼幾乎都可以內嵌到預存程序之中。 您可以逐步執行其他快速入門以了解 SSMS 和內嵌的 Python。
1 - 安裝 Python 套件
本機工作站的 Python 套件版本必須與 SQL Server 上的套件版本相同,這包括基底 Anaconda 4.2.0 (英文) 搭配 Python 3.5.2 發行版本 (英文),以及 Microsoft 特定的套件。
安裝指令碼會將三個 Microsoft 特定程式庫新增到 Python 用戶端。 指令碼會安裝:
- revoscalepy 用來定義資料來源物件和計算內容。
- microsoftml 以提供機器學習演算法。
- azureml 適用於與獨立伺服器內容相關的運算化工作,且針對資料庫內分析可能具有有限的用途。
下載安裝指令碼。 在適當的下列 GitHub 頁面上,選取 [下載原始檔案]。
Install-PyForMLS.ps1 安裝 Microsoft Python 套件的 9.2.1 版本。 此版本會對應至預設 SQL Server 執行個體。
Install-PyForMLS.ps1 安裝了 Microsoft Python 套件的 9.3 版本。
以提高的系統管理員權限開啟 PowerShell 視窗 (以滑鼠右鍵按一下 [以系統管理員身分執行])。
移至您下載安裝程式的資料夾並執行指令碼。 新增
-InstallFolder命令列引數來為程式庫指定資料夾位置。 例如:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
如果您省略安裝資料夾,預設資料夾是 %ProgramFiles%\Microsoft\PyForMLS。
安裝需要一些時間才能完成。 您可以在 PowerShell 視窗中監視進度。 設定完成時,您將會有一組完整的套件。
提示
我們建議參閱適用於 Windows 的 Python 常見問題集 (英文) 以了解在 Windows 上執行 Python 程式的一般用途資訊。
2 - 尋找可執行檔
繼續在 PowerShell 中列出安裝資料夾的內容,以確認已安裝 Python.exe、指令碼及其他套件。
輸入
cd \以移至根磁碟機,然後輸入您在上一個步驟中針對-InstallFolder所指定的路徑。 如果您在安裝期間忽略此參數,預設值為cd %ProgramFiles%\Microsoft\PyForMLS。輸入
dir *.exe以列出可執行檔。 您應該會看見 python.exe、pythonw.exe 及 uninstall-anaconda.exe。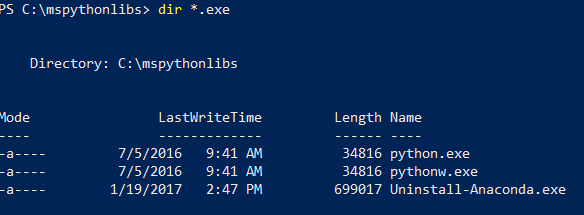
在具有多個 Python 版本的系統上,如果您想要載入 revoscalepy 及其他 Microsoft 套件,請記得使用這個特定的 Python.exe。
注意
安裝指令碼不會修改您電腦上的 PATH 環境變數,這代表您剛才安裝的新 Python 解譯器及模組並不會自動提供給您可能擁有的其他工具。 如需將 Python 解譯器及程式庫連結至工具的相關協助,請參閱安裝 IDE。
3 - 開啟 Jupyter Notebook
Anaconda 包含 Jupyter Notebook。 作為下一個步驟,請建立筆記本並執行一些包含您剛才所安裝之程式庫的 Python 程式碼。
於 PowerShell 命令提示字元中,在仍然處於
%ProgramFiles%\Microsoft\PyForMLS目錄的情況下,從 [Scripts] 資料夾開啟 Jupyter Notebook:.\Scripts\jupyter-notebook在您的預設瀏覽器中,應該會於
https://localhost:8889/tree開啟筆記本。另一個啟動方式是按兩下 jupyter-notebook.exe。
選取 [新增],然後選取 [Python 3]。
![具有 [新增 Python 3] 選項的 Jupyter 筆記本的螢幕擷取畫面。](media/setup-python-client-tools-sql/jupyter-notebook-new-p3.png?view=sql-server-ver15)
輸入
import revoscalepy並執行命令以載入其中一個 Microsoft 特定程式庫。輸入並執行
print(revoscalepy.__version__)以傳回版本資訊。 您應該會看到 9.2.1 或 9.3.0。 您可以搭配伺服器上的 revoscalepy 使用任何一個版本。輸入更複雜的陳述式系列。 此範例會在本機資料集上使用 rx_summary \(英文\) 來產生摘要統計資料。 其他函式會取得範例資料的位置,並針對本機 .xdf 檔案建立資料來源物件。
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
下列螢幕擷取畫面會顯示輸入及一部分輸出 (為了簡潔起見而修剪)。

4 - 取得 SQL 權限
若要連線至 SQL Server 執行個體以執行指令碼及上傳資料,您必須擁有資料庫伺服器的有效登入。 您可以使用 SQL 登入或整合式 Windows 驗證。 我們通常會建議您使用 Windows 整合式驗證,但針對某些案例使用 SQL 登入會比較簡單,特別是當您的指令碼包含外部資料的連接字串時。
至少,用來執行程式碼的帳戶必須擁有從您所使用的資料庫讀取的權限,以及 EXECUTE ANY EXTERNAL SCRIPT 特殊權限。 大部分的開發人員也會需要權限以建立預存程序,以及將資料寫入包含定型資料或評分資料的資料表中。
詢問資料庫管理員以在您使用 Python 的資料庫中針對您的帳戶設定下列權限:
- EXECUTE ANY EXTERNAL SCRIPT 以在伺服器上執行 Python。
- db_datareader 權限以執行用來將模型定型的查詢。
- db_datawriter 以寫入定型資料或評分資料。
- db_owner 以建立如預存程序、資料表、函式等的物件。 您也需要 db_owner 以建立範例和測試資料庫。
如果您的程式碼需要 SQL Server 預設不會安裝的套件,請向資料庫管理員安排以搭配執行個體安裝那些套件。 SQL Server 是安全的環境,因此會限制可以安裝套件的位置。 不建議您搭配程式碼以臨機操作方式來安裝套件,即使您擁有權限也一樣。 此外,在於伺服器程式庫中安裝新套件之前,請一律仔細考慮安全性影響。
5 - 建立測試資料
如果您有在遠端伺服器上建立資料庫的權限,您可以執行下列程式碼來建立會用於此文章後續步驟中的 Iris 示範資料庫。
5-1 - 遠端建立 irissql 資料庫
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2 - 從 SkLearn 匯入 Iris 範例
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - 使用 Revoscalepy API 來建立資料表並載入 Iris 資料
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - 測試遠端連線
在嘗試進行下一個步驟之前,請確定您具有 SQL Server 執行個體上的權限,以及針對 Iris 範例資料庫的連接字串。 如果資料庫不存在且您有足夠的權限,您可以使用這些內嵌指示來建立資料庫。
將連接字串取代為有效的值。 範例程式碼會使用 "Server=localhost;Database=irissql;Trusted_Connection=Yes;",但您的程式碼應該要指定遠端伺服器 (很可能是透過執行個體名稱),以及能對應至資料庫登入的認證選項。
6-1 定義函式
下列程式碼會定義您將在稍後步驟中傳送至 SQL Server 的函式。 執行時,它會使用遠端伺服器上的資料和程式庫 (revoscalepy、pandas、matplotlib) 來建立 Iris 資料集的散佈圖。 它會將 .png 的位元資料流傳回 Jupyter Notebook 以在瀏覽器中呈現。
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 將函式傳送到 SQL Server
在此範例中,建立遠端計算內容,然後將函式的執行搭配 rx_exec \(英文\) 傳送到 SQL Server。 rx_exec 函式很有用,因為它能接受計算內容作為引數。 您想要遠端執行的任何函式都必須具有計算內容引數。 某些函式 (例如 rx_lin_mod \(英文\)) 能直接支援此引數。 針對不支援的作業,您可以使用 rx_exec 來以遠端計算內容傳遞您的程式碼。
在此範例中,不需要將任何未經處理資料從 SQL Server 傳輸到 Jupyter Notebook。 所有計算都會在 Iris 資料庫內發生,且只會將影像檔案傳回用戶端。
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
下列螢幕擷取畫面會顯示輸入和散佈圖輸出。

7 - 從工具啟動 Python
由於開發人員經常會使用多個 Python 版本,安裝程式並不會將 Python 新增到您的路徑。 若要使用由安裝程式所安裝的 Python 可執行檔和程式庫,請在同時提供 revoscalepy 和 microsoftml 的路徑上,將您的 IDE 連結到 Python.exe。
命令列
當您從 (或是您針對 Python 用戶端程式庫安裝所指定的其他位置) 執行 %ProgramFiles%\Microsoft\PyForMLS 時,您將能存取完整的 Anaconda 發行版本,以及 Microsoft Python 模組 revoscalepy 和 microsoftml。
- 移至
%ProgramFiles%\Microsoft\PyForMLS並執行 Python.exe。 - 開啟互動式說明:
help()。 - 在說明提示字元中輸入模組的名稱:
help> revoscalepy。 說明會傳回名稱、套件內容、版本及檔案位置。 - 在 >。 按幾次 Enter 以結束說明。
- 匯入模組:
import revoscalepy。
Jupyter Notebook
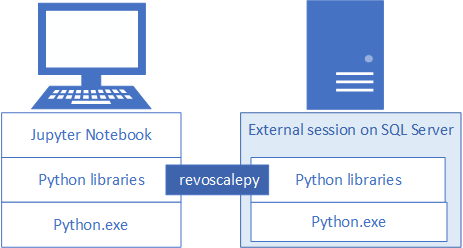
此文章使用內建的 Jupyter Notebook 來示範針對 revoscalepy 進行函式呼叫。 如果您尚不熟悉此工具,下列螢幕擷取畫面會說明所有元件搭配運作的方式,以及它們為何能直接「順利執行」。
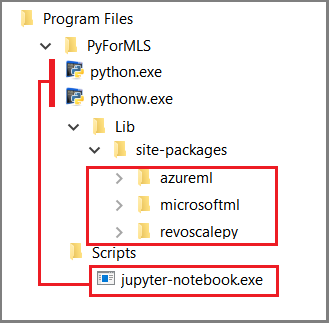
父資料夾 %ProgramFiles%\Microsoft\PyForMLS 會包含 Anaconda 和 Microsoft 套件。 Jupyter Notebook 包含在 Anaconda 中的 [Scripts] 資料夾底下,而 Python 可執行檔會自動註冊至 Jupyter Notebook。 在網站套件底下找到的套件可以匯入到筆記本中,包括用於資料科學和機器學習的三個 Microsoft 套件。
如果您是使用另一個 IDE,您必須將 Python 可執行檔和函式程式庫連結到您的工具。 下列小節提供適用於常用工具的指示。
Visual Studio
如果您在Visual Studio 中具有 Python \(英文\),請使用下列設定選項來建立包含 Microsoft Python 套件的 Python 環境。
| 組態設定 | value |
|---|---|
| 前置詞路徑 | %ProgramFiles%\Microsoft\PyForMLS |
| 解譯器路徑 | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| 具範圍限制的解譯器 | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
如需設定 Python 環境的協助,請參閱在 Visual Studio 中管理 Python 環境。
PyCharm
在 PyCharm 中,將解譯器設定至所安裝的 Python 可執行檔。
在新專案的 [Settings] \(設定\) 中,選取 [Add Local] \(新增本機\)。
輸入
%ProgramFiles%\Microsoft\PyForMLS\。
您現在可以匯入 revoscalepy、microsoftml 或 azureml 模組。 您也可以選擇 [Tools] \(工具\)[Python Console] \(Python 主控台\) 來開啟互動式視窗。