適用於:Azure Stack HCI 版本 22H2 和 21H2;Windows Server 2022、Windows Server 2019
本文提供了有關如何規劃集群卷以滿足工作負載的性能和容量需求的指導,包括選擇其文件系統、彈性類型和大小。
備註
存儲空間直通不支援常規使用的文件伺服器。 如果需要在 Storage Space Direct 上運行檔伺服器或其他通用服務,請在虛擬機上對其進行配置。
評論:什麼是卷
卷是放置工作負載所需檔的位置,例如 Hyper-V 虛擬機的 VHD 或 VHDX 檔。 卷將存儲池中的驅動器組合在一起,以引入 存儲空間直通的容錯、可伸縮性和性能優勢,這是 Azure Stack HCI 和 Windows Server 背後的軟體定義存儲技術。
備註
我們使用術語「卷」來共同指代卷及其下的虛擬磁碟,包括其他內置 Windows 功能(如群集共用卷 (CSV) 和 ReFS)提供的功能。 瞭解這些實現級別的區別對於成功規劃和部署存儲空間直通不是必需的。
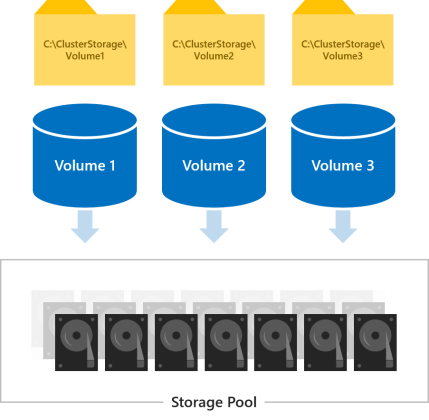
集群中的所有伺服器都可以同時訪問所有卷。 創建后,它們將顯示在所有伺服器上的 C:\ClusterStorage\ 中。

選擇要創建的捲數
我們建議將捲數設置為集群中伺服器數的倍數。 例如,如果您有 4 台伺服器,則總共 4 個卷的性能將比使用 3 個或 5 個捲時更一致。 這允許集群在伺服器之間均勻分配卷 「擁有權」 (一台伺服器處理每個卷的元數據編排)。
我們建議將每個集群的捲總數限制為64個卷。
選擇檔案系統
我們建議將新的 彈性文件系統 (ReFS) 用於存儲空間直通。 ReFS 是專為虛擬化構建的主要文件系統,具有許多優勢,包括顯著的性能加速和針對數據損壞的內置保護。 它支持幾乎所有關鍵的NTFS功能,包括Windows Server版本1709及更高版本中的重複資料刪除。 有關詳細資訊,請參閱 ReFS 功能比較表 。
如果您的工作負載需要 ReFS 尚不支援的功能,您可以改用 NTFS。
小提示
具有不同文件系統的卷可以共存於同一集群中。
選擇彈性類型
存儲空間直通中的卷提供彈性,以防止硬體問題(如驅動器或伺服器故障),並在整個伺服器維護(如軟體更新)中實現持續可用性。
備註
您可以選擇哪些彈性類型與您擁有的驅動器類型無關。
有兩台伺服器
如果群集中有兩台伺服器,則可以使用雙向鏡像,也可以使用嵌套復原能力。
雙向鏡像保留所有數據的兩個副本,一個副本位於每個伺服器的驅動器上。 它的存儲效率為 50%;要寫入 1 TB 的數據,存儲池中至少需要 2 TB 的物理存儲容量。 雙向鏡像可以安全地容忍一次一個硬體故障(一台伺服器或驅動器)。
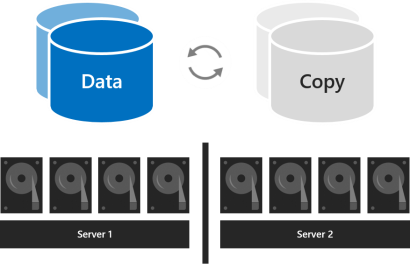
嵌套彈性在具有雙向鏡像的伺服器之間提供數據彈性,然後在具有雙向鏡像或鏡像加速奇偶校驗的伺服器內增加彈性。 嵌套可提供數據彈性,即使一台伺服器重新啟動或不可用。 使用嵌套雙向鏡像時,其存儲效率為 25%,嵌套鏡像加速奇偶校驗時,其存儲效率約為 35-40%。 嵌套彈性可以安全地容忍一次兩個硬體故障(兩個驅動器,或一個伺服器和另一個伺服器上的一個驅動器)。 由於增加了數據彈性,我們建議在雙伺服器集群的生產部署中使用嵌套彈性。 有關詳細資訊,請參閱 嵌套復原能力。

擁有三台伺服器
對於三台伺服器,您應該使用三向鏡像以獲得更好的容錯能力和性能。 三向鏡像保留所有數據的三個副本,每個伺服器的驅動器上有一個副本。 它的存儲效率為 33.3% – 要寫入 1 TB 的數據,存儲池中至少需要 3 TB 的物理存儲容量。 三向鏡像可以安全地同時容忍至少兩個硬體問題(驅動器或伺服器)。 如果 2 個節點不可用,則存儲池將丟失仲裁,因為 2/3 的磁碟不可用,並且虛擬磁碟不可訪問。 但是,一個節點可能會關閉,另一個節點上的一個或多個磁碟可能會發生故障,而虛擬磁碟仍保持連線狀態。 例如,如果您在重新啟動一部伺服器時,突然有另一部磁碟驅動器或伺服器故障,所有數據依然會保持安全並持續可存取。
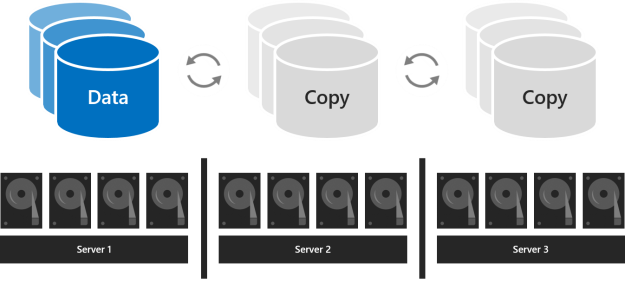
具有 4 台或更多伺服器
對於四個或更多伺服器,您可以為每個卷選擇是使用三向鏡像、雙奇偶校驗(通常稱為“糾刪碼”),還是將兩者與鏡像加速奇偶校驗混合使用。
雙奇偶校驗提供與三向鏡像相同的容錯能力,但具有更好的存儲效率。 使用四台伺服器,其存儲效率為50.0%;要存儲 2 TB 的數據,您需要在儲存池中具有 4 TB 的物理儲存容量。 這提高了 7 台伺服器的存儲效率 66.7%,並繼續提高到 80.0% 的存儲效率。 權衡是奇偶校驗編碼的計算密集度更高,這可能會限制其性能。
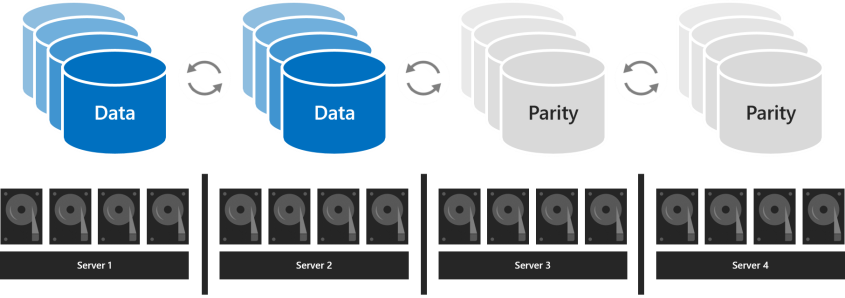
使用哪種彈性類型取決於您環境的性能和容量要求。 下表總結了每種彈性類型的性能和存儲效率。
| 復原類型 | 容量效率 | 速度 |
|---|---|---|
| 鏡子 |

三向鏡:33% 雙向鏡:50% |

最高性能 |
| 鏡像加速的同位 |

取決於鏡像和奇偶校驗的比例 |

比鏡像慢得多,但速度是雙奇偶校驗的兩倍 最適合大型順序寫入和讀取 |
| 雙奇偶校驗 |

4 台伺服器:50% 16 台伺服器:最多 80% |

最高的I/O延遲和寫入時的CPU使用率 最適合大型順序寫入和讀取 |
當性能最重要時
具有嚴格延遲要求或需要大量混合隨機 IOPS 的工作負載(例如 SQL Server 資料庫或性能敏感型 Hyper-V 虛擬機)應在使用鏡像來最大化性能的卷上運行。
小提示
鏡像速度比任何其他復原模式都快。 我們幾乎所有的性能示例都使用鏡像。
當容量最重要時
不經常寫入的工作負載(例如數據倉庫或 “冷” 存儲)應在使用雙奇偶校驗的捲上運行,以最大限度地提高存儲效率。 某些其他工作負載,例如 Scale-Out File Server (SoFS)、虛擬桌面基礎設施 (VDI) 或其他不會產生大量快速漂移隨機 IO 流量和/或不需要最佳性能的工作負載,也可以自行決定使用雙重奇偶校驗。 與鏡像相比,奇偶校驗不可避免地會增加 CPU 利用率和 IO 延遲,尤其是在寫入時。
批量寫入數據時
以大型順序傳遞(例如存檔或備份目標)寫入的工作負載還有另一種選擇:一個卷可以混合鏡像和雙奇偶校驗。 先將資料寫入鏡像部分,然後逐漸移至同位部分。 這允許在更長的時間內進行計算密集型奇偶校驗編碼,從而加快攝取速度,並在大型寫入到達時降低資源利用率。 在調整部分大小時,請考慮一次發生的寫入量(例如每天一次備份)應該適合鏡像部分。 例如,如果您每天提取一次 100 GB,請考慮對 150 GB 到 200 GB 使用鏡像,對其餘部分使用雙重奇偶校驗。
最終的存儲效率取決於您選擇的比例。
小提示
如果您在數據攝取過程中觀察到寫入性能突然下降,則可能表明鏡像部分不夠大,或者鏡像加速奇偶校驗不太適合您的使用案例。 例如,如果寫入性能從 400 MB/s 下降到 40 MB/s,請考慮擴展鏡像部分或切換到三向鏡像。
關於使用 NVMe、SSD 和 HDD 的部署
在具有兩種驅動器類型的部署中,速度較快的驅動器提供緩存,而速度較慢的驅動器提供容量。 這會自動發生 - 有關詳細資訊,請參閱 瞭解存儲空間直通中的緩存。 在此類部署中,所有卷最終都位於相同類型的驅動器上,即容量驅動器。
在具有所有三種類型驅動器的部署中,只有最快的驅動器 (NVMe) 提供緩存,留下兩種類型的驅動器(SSD 和 HDD)來提供容量。 對於每個卷,您可以選擇它是完全駐留在 SSD 層上、完全駐留在 HDD 層上,還是跨越兩者。
這很重要
建議您使用 SSD 層,在全快閃上放置最敏感的效能工作負載。
選擇卷的大小
建議在 Azure Stack HCI 中將每個卷的大小限制為 64 TB。
小提示
如果您使用的備份解決方案依賴於卷影複製服務 (VSS) 和 Volsnap 軟體提供程式(這在檔案伺服器工作負載中很常見),則將卷大小限制為 10 TB 將提高性能和可靠性。 使用較新的 Hyper-V RCT API 和/或 ReFS 塊克隆和/或本機 SQL 備份 API 的備份解決方案在高達 32 TB 及以上的情況下表現良好。
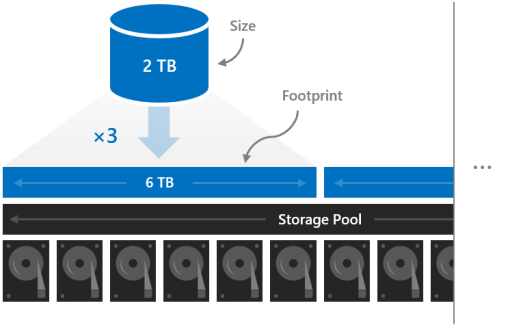
腳印
卷的大小是指其可用容量,即它可以存儲的數據量。 這是由 New-Volume cmdlet 的 -Size 參數提供的,然後在運行 Get-Volume cmdlet 時顯示在 Size 屬性中。
大小與卷 的佔用空間不同,即它在存儲池中佔用的總物理存儲容量。 佔用空間取決於其彈性類型。 例如,使用三向鏡像的卷的佔用空間是其大小的三倍。
卷的佔用空間需要適合存儲池。
預留容量
在存儲池中保留一些未分配的容量可以為卷提供空間,以便在驅動器發生故障后“就地”修復,從而提高數據安全性和性能。 如果有足夠的容量,則立即就地並行修復甚至可以在更換故障驅動器之前將捲恢復到完全彈性。 此作業會自動進行。
我們建議為每個伺服器預留相當於一個容量驅動器的驅動器,最多 4 個驅動器。 您可以自行決定保留更多,但此最低建議可保證在任何驅動器發生故障后可以立即就地並行修復成功。

例如,如果您有 2 台伺服器,並且使用的是 1 TB 容量的驅動器,請留出 2 x 1 = 2 TB 的池作為預留。 如果您有 3 台伺服器和 1 TB 容量的驅動器,請留出 3 x 1 = 3 TB 作為預留空間。 如果您有 4 個或更多伺服器和 1 TB 容量的驅動器,請留出 4 x 1 = 4 TB 作為預留空間。
備註
在具有所有三種類型驅動器 (NVMe + SSD + HDD) 的集群中,我們建議為每個伺服器預留相當於 1 個 SSD 加 1 個 HDD 的硬碟,每個伺服器最多 4 個驅動器。
示例:容量規劃
考慮一個四伺服器集群。 每個伺服器都有一些緩存驅動器和16個2 TB驅動器的容量。
4 servers x 16 drives each x 2 TB each = 128 TB
從存儲池中的這 128 TB 中,我們留出 4 個驅動器,即 8 TB,以便進行就地修復,而無需在驅動器發生故障後急於更換驅動器。 這在池中留下了 120 TB 的物理存儲容量,我們可以用它來創建卷。
128 TB – (4 x 2 TB) = 120 TB
假設我們需要部署來託管一些高度活躍的 Hyper-V 虛擬機,但我們也有大量的冷存儲 - 我們需要保留舊文件和備份。 因為我們有 4 台伺服器,所以讓我們創建 4 個卷。
讓我們將虛擬機放在前兩個卷 Volume1 和 Volume2 上。 我們選擇 ReFS 作為文件系統(為了更快地創建和檢查點)和三向鏡像以實現復原能力,從而最大限度地提高性能。 讓我們將冷存儲放在其他兩個卷上, 即 Volume 3 和 Volume 4。 我們選擇NTFS作為檔案系統(用於重複資料刪除)和雙奇偶校驗以實現彈性,以最大限度地提高容量。
我們不需要將所有卷的大小都設置為相同,但為了簡單起見,例如,我們可以將它們全部設置為 12 TB。
Volume1 和 Volume2 各佔用 12 TB x 33.3% 的效率 = 36 TB 的物理存儲容量。
Volume3 和 Volume4 各佔用 12 TB x 50.0% 的效率 = 24 TB 的物理存儲容量。
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
這四個卷完全符合我們池中可用的物理存儲容量。 太棒了!

小提示
您無需立即建立所有卷。 您始終可以擴展卷或稍後創建新卷。
為簡單起見,此示例在整個過程中使用十進位 (以 10 為基數) 單位,這意味著 1 TB = 1,000,000,000,000 位元組。 但是,Windows 中的存儲量以二進位 (base-2) 單位顯示。 例如,每個 2 TB 驅動器在 Windows 中將顯示為 1.82 TiB。 同樣,128 TB 儲存池將顯示為116.41 TiB。 這是預期的。
用法
請參閱 創建卷。
後續步驟
如需詳細資訊,請參閱: