أنشطة العملاء المطلوبة
ما قبل الحدث
لخدمات Azure
- كن على دراية ب Azure Service Health في مدخل Microsoft Azure. ستعمل هذه الصفحة ك "متجر واحد" أثناء وقوع حادث.
- ضع في اعتبارك استخدام تنبيهات Service Health، والتي يمكن تكوينها لإنتاج إعلامات تلقائيا عند حدوث حوادث Azure.
ل Power BI
- كن على دراية بصحة الخدمة في مركز مسؤولي Microsoft 365. ستعمل هذه الصفحة ك "متجر واحد" أثناء وقوع حادث.
- ضع في اعتبارك استخدام تطبيق مسؤول Microsoft 365 للأجهزة المحمولة للحصول على إعلامات تنبيه تلقائية لحوادث الخدمة.
أثناء الحادث
لخدمات Azure
- ستوفر Azure Service Health داخل مدخل إدارة Azure آخر التحديثات.
- إذا كانت هناك مشكلات في الوصول إلى حالة الخدمة، فراجع صفحة حالة Azure.
- إذا كانت هناك مشكلات في الوصول إلى صفحة الحالة، فانتقل إلى @AzureSupport على X (المعروف سابقا ب Twitter).
- إذا لم يتطابق التأثير/المشكلات مع الحدث (أو استمر بعد التخفيف)، فاتصل بالدعم لرفع تذكرة دعم الخدمة.
ل Power BI
- ستوفر صفحة Service Health ضمن مركز مسؤولي Microsoft 365 آخر التحديثات
- إذا كانت هناك مشكلات في الوصول إلى حالة الخدمة، فراجع صفحة حالة Microsoft 365
- إذا لم يتطابق التأثير/المشكلات مع الحدث (أو إذا استمرت المشكلات بعد التخفيف)، فيجب عليك رفع تذكرة دعم الخدمة.
بعد استرداد Microsoft
راجع الأقسام أدناه للحصول على هذه التفاصيل.
نشر الحدث
لخدمات Azure
- ستقوم Microsoft بنشر PIR إلى مدخل Microsoft Azure - حالة الخدمة للمراجعة.
ل Power BI
- ستقوم Microsoft بنشر PIR إلى مسؤول Microsoft 365 - حالة الخدمة للمراجعة.
انتظر عملية Microsoft
تنتظر عملية "انتظار Microsoft" ببساطة حتى تقوم Microsoft باسترداد جميع المكونات والخدمات في المنطقة الأساسية المتأثرة. بمجرد الاسترداد، تحقق من ربط النظام الأساسي للبيانات بالخدمات المشتركة للمؤسسة أو الخدمات الأخرى، وتاريخ مجموعة البيانات، ثم قم بتنفيذ عمليات إحضار النظام إلى التاريخ الحالي.
بمجرد الانتهاء من هذه العملية، يمكن إكمال التحقق من صحة الخبراء التقنيين ومتخصصي الأعمال (SME) لتمكين موافقة أصحاب المصلحة على استرداد الخدمة.
إعادة النشر عند حدوث كارثة
بالنسبة لاستراتيجية "إعادة النشر في حالة الكوارث"، يمكن وصف تدفق العملية عالي المستوى التالي.
استرداد الخدمات المشتركة للمؤسسة وأنظمة المصدر الخاصة ب Contoso

- هذه الخطوة هي شرط أساسي لاستعادة النظام الأساسي للبيانات.
- وستنجز هذه الخطوة مختلف مجموعات الدعم التشغيلي لشركات Contoso المسؤولة عن الخدمات المشتركة للمؤسسة وأنظمة المصادر التشغيلية.
استرداد خدمات Azure تشير خدمات Azure إلى التطبيقات والخدمات التي تجعل عرض Azure Cloud متوفرا داخل المنطقة الثانوية للنشر.

تشير خدمات Azure إلى التطبيقات والخدمات التي تجعل عرض Azure Cloud متاحا داخل المنطقة الثانوية للنشر.
- هذه الخطوة هي شرط أساسي لاسترداد النظام الأساسي للبيانات.
- سيتم إكمال هذه الخطوة من قبل Microsoft وشركاء النظام الأساسي الآخر كخدمة (PaaS)/software كخدمة (SaaS).
استرداد أساس النظام الأساسي للبيانات
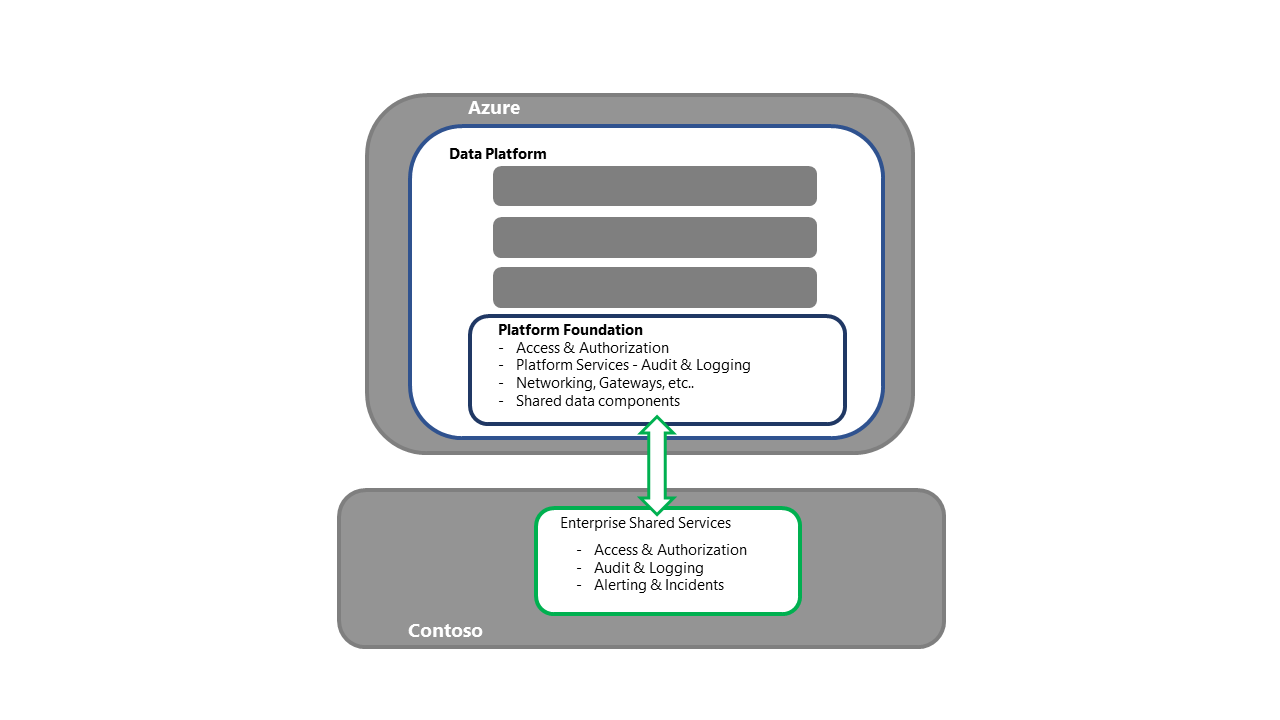
- هذه الخطوة هي نقطة الإدخال لأنشطة استرداد النظام الأساسي.
- وبالنسبة لاستراتيجية إعادة التوزيع، سيتم شراء كل مكون/خدمة مطلوبة ونشرها في المنطقة الثانوية.
- راجع قسم خدمة ومكون Azure في هذه السلسلة للحصول على تصنيف تفصيلي للمكونات واستراتيجيات التوزيع.
- وينبغي أن تتضمن هذه العملية أيضا أنشطة مثل الربط بالخدمات المشتركة للمؤسسة، وضمان الاتصال بالوصول/المصادقة، والتحقق من أن تفريغ السجل يعمل، مع ضمان الاتصال بكل من عمليات المنبع والمصب.
- يجب تأكيد البيانات/المعالجة. على سبيل المثال، التحقق من الطابع الزمني للنظام الأساسي المسترد.
- إذا كانت هناك أسئلة حول تكامل البيانات، يمكن اتخاذ قرار بالعودة إلى الحالة السابقة في الوقت المناسب قبل تنفيذ المعالجة الجديدة لتحديث النظام الأساسي.
- سيساعد وجود ترتيب أولوية للعمليات (بناء على تأثير الأعمال) في تنظيم الاسترداد.
- يجب إغلاق هذه الخطوة من خلال التحقق التقني ما لم يتفاعل مستخدمو الأعمال مباشرة مع الخدمات. إذا كان هناك وصول مباشر، فستحتاج إلى خطوة التحقق من صحة الأعمال.
- بمجرد اكتمال التحقق من الصحة، يحدث تسليم إلى فرق الحلول الفردية لبدء عملية استرداد التعافي من الكوارث (DR) الخاصة بها.
- يجب أن يتضمن هذا التسليم تأكيد الطابع الزمني الحالي للبيانات والعمليات.
- إذا كان سيتم تنفيذ عمليات بيانات المؤسسة الأساسية، يجب أن تكون الحلول الفردية على دراية بهذا - التدفقات الواردة/الصادرة، على سبيل المثال.
استرداد الحلول الفردية التي تستضيفها المنصة
- يجب أن يكون لكل حل فردي دفتر تشغيل DR الخاص به. يجب أن تحتوي دفاتر التشغيل على الأقل على أصحاب المصلحة التجاريين المرشحين الذين سيختبرون ويتأكدون من اكتمال استرداد الخدمة.
- اعتمادا على الخلاف على الموارد أو الأولوية، قد يتم إعطاء الأولوية للحلول/أحمال العمل الرئيسية على غيرها - عمليات المؤسسة الأساسية عبر المختبرات المخصصة، على سبيل المثال.
- بمجرد اكتمال خطوات التحقق من الصحة، يحدث تسليم إلى حلول انتقال البيانات من الخادم لبدء عملية استرداد DR الخاصة بهم.
التسليم إلى أنظمة انتقال البيانات من الخادم والأنظمة التابعة
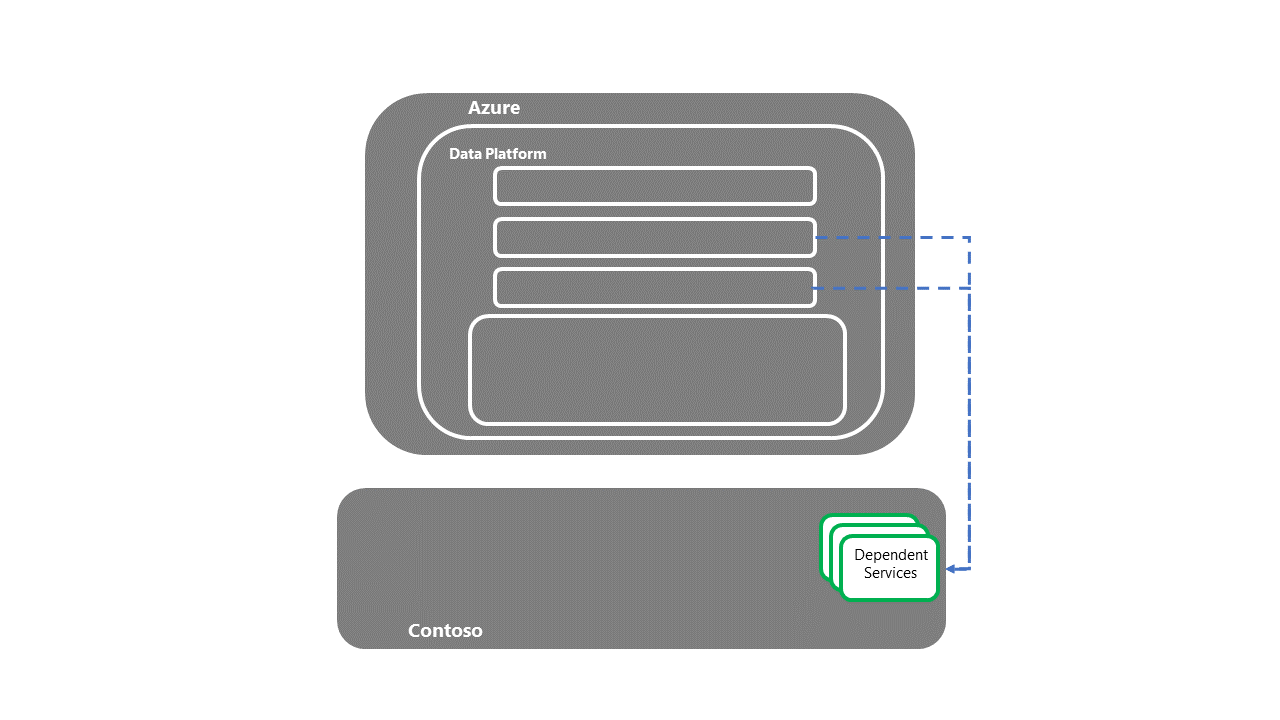
- بمجرد استرداد الخدمات التابعة، تكتمل عملية استرداد E2E DR.
إشعار
في حين أنه من الممكن نظريا أتمتة عملية E2E DR بالكامل، إلا أنه من غير المحتمل نظرا لخطر الحدث مقابل تكلفة أنشطة SDLC المطلوبة لتغطية عملية E2E.
العودة إلى المنطقة الأساسية الاحتياطية هي عملية نقل خدمة النظام الأساسي للبيانات وبياناتها مرة أخرى إلى المنطقة الأساسية، بمجرد أن تكون متاحة ل BAU.
واستنادا إلى طبيعة نظم المصدر ومختلف عمليات البيانات، يمكن إجراء النسخ الاحتياطي للنظام الأساسي للبيانات بشكل مستقل عن أجزاء أخرى من النظام الإيكولوجي للبيانات.
ينصح العملاء بمراجعة تبعيات النظام الأساسي للبيانات الخاصة بهم (في المنبع والمصب على حد سواء) لاتخاذ القرار المناسب. يفترض القسم التالي استردادا مستقلا للنظام الأساسي للبيانات.
- بمجرد أن تصبح جميع المكونات/الخدمات المطلوبة متاحة في المنطقة الأساسية، سيكمل العملاء اختبار الدخان للتحقق من صحة استرداد Microsoft.
- سيتم التحقق من صحة تكوين المكون/الخدمة. ستتم معالجة دلتا عن طريق إعادة التوزيع من التحكم بالمصادر.
- سيتم تحديد تاريخ النظام في المنطقة الأساسية عبر المكونات ذات الحالة. يجب معالجة دلتا بين التاريخ المحدد والتاريخ/الطابع الزمني في المنطقة الثانوية عن طريق إعادة تنفيذ أو إعادة تشغيل عمليات استيعاب البيانات من تلك النقطة إلى الأمام.
- وبموافقة كل من أصحاب المصلحة التجاريين والتقنيين، سيتم تحديد نافذة احتياطية. من الناحية المثالية، يجب أن يحدث هذا أثناء فترة هدوء في نشاط النظام ومعالجته.
- أثناء العودة إلى الحالة الاحتياطية، ستتم مزامنة المنطقة الأساسية مع المنطقة الثانوية، قبل تبديل النظام.
- بعد فترة تشغيل موازية، سيتم نقل المنطقة الثانوية دون اتصال من النظام.
- سيتم إما إسقاط المكونات في المنطقة الثانوية أو تجريدها مرة أخرى، اعتمادا على استراتيجية الاسترداد بعد الكوارث المحددة.
عملية قطع الغيار الدافئة
وفيما يتعلق باستراتيجية "الاحتياطي الدافئ"، فإن تدفق العمليات رفيع المستوى يتماشى بشكل وثيق مع تدفق "إعادة التوزيع عند وقوع الكوارث"، والفرق الرئيسي هو أن المكونات قد تم شراؤها بالفعل في المنطقة الثانوية. تلغي هذه الاستراتيجية مخاطر التنازع على الموارد من المؤسسات الأخرى التي تتطلع إلى إكمال الإصلاح بعد الكوارث في تلك المنطقة.
عملية التشغيل السريع
تعني استراتيجية "قطع الغيار السريع" أن خدمات النظام الأساسي بما في ذلك النظام الأساسي كخدمة (PaaS) وأنظمة البنية التحتية كخدمة (IaaS) ستستمر على الرغم من حدث الكارثة حيث تعمل الأنظمة الثانوية جنبا إلى جنب مع الأنظمة الأساسية. كما هو الحال مع استراتيجية "الاحتياطي الدافئ"، فإن هذه الاستراتيجية تلغي خطر الخلاف على الموارد من المؤسسات الأخرى التي تتطلع إلى إكمال الإصلاح بعد الكوارث الخاصة بها في تلك المنطقة.
سيقوم عملاء Hot Spare بمراقبة استرداد Microsoft للمكونات/الخدمات في المنطقة الأساسية. بمجرد الانتهاء، سيقوم العملاء بالتحقق من صحة أنظمة المنطقة الأساسية وإكمال العودة إلى المنطقة الأساسية. ستكون هذه العملية مشابهة لعملية تجاوز الفشل DR أي التحقق من قاعدة التعليمات البرمجية والبيانات المتوفرة وإعادة التوزيع كما هو مطلوب.
إشعار
وينبغي ملاحظة خاصة هنا لضمان اتساق أي بيانات تعريف للنظام بين المنطقتين.
- بمجرد اكتمال الرجوع إلى الأساسي، يمكن تحديث موازنات تحميل النظام لإعادة المنطقة الأساسية إلى طبولوجيا النظام. إذا كان متوفرا، يمكن استخدام نهج إصدار الكناري لتشغيل المنطقة الأساسية للنظام بشكل متزايد.
بنية خطة الإصلاح بعد الكوارث
تقدم خطة الإصلاح بعد الكوارث الفعالة دليلا خطوة بخطوة لاسترداد الخدمة يمكن تنفيذه بواسطة مورد تقني Azure. على هذا النحو، يسرد التالي بنية MVP مقترحة لخطة الإصلاح بعد الكوارث.
- متطلبات العملية
- أي تفاصيل خاصة بعملية الاسترداد بعد الكوارث للعميل، مثل التخويل الصحيح المطلوب لبدء الاسترداد بعد الكارثة، واتخاذ القرارات الرئيسية حول الاسترداد حسب الضرورة (بما في ذلك "تعريف تم")، وخدمة دعم مرجع تذاكر DR، وتفاصيل غرفة الحرب.
- تأكيد المورد، بما في ذلك العميل المتوقع DR والنسخ الاحتياطي للمنفذ. يجب توثيق جميع الموارد مع جهات الاتصال الأساسية والثانوية ومسارات التصعيد وترك التقويمات. وفي حالات الإصلاح بعد الكوارث الحرجة، قد تحتاج نظم القوائم إلى النظر فيها.
- الكمبيوتر المحمول أو حزم الطاقة أو طاقة النسخ الاحتياطي واتصال الشبكة وتفاصيل الهاتف المحمول لمنفذ DR والنسخ الاحتياطي DR وأي نقاط تصعيد.
- العملية التي سيتم اتباعها إذا لم يتم استيفاء أي من متطلبات العملية.
- قائمة جهات الاتصال
- مجموعات دعم وقيادة الإصلاح بعد الكوارث.
- الشركات الصغيرة والمتوسطة التي سوف تكمل دورة الاختبار / المراجعة للتعافي التقني.
- مالكو الأعمال المتأثرون، بما في ذلك موافقو استرداد الخدمة.
- المالكون الفنيون المتأثرون، بما في ذلك الموافقون على الاسترداد التقني.
- دعم الشركات الصغيرة والمتوسطة في جميع المناطق المتأثرة، بما في ذلك الحلول الرئيسية التي تستضيفها المنصة.
- أنظمة انتقال البيانات من الخادم المتأثرة - الدعم التشغيلي.
- أنظمة المصدر المصدر - الدعم التشغيلي.
- جهات اتصال الخدمات المشتركة للمؤسسة. على سبيل المثال، دعم الوصول والمصادقة ومراقبة الأمان ودعم البوابة
- أي مورد خارجي أو خارجي، بما في ذلك جهات الاتصال الداعمة لموفري السحابة.
- تصميم البنية
- وصف تفاصيل سيناريو النهاية (E2E)، وإرفاق جميع وثائق الدعم المقترنة.
- التبعيات
- سرد جميع علاقات المكونات وتبعياتها.
- متطلبات الإصلاح بعد الكوارث
- تأكيد توفر أنظمة المصدر حسب الحاجة.
- تم منح وصول مرتفع عبر المكدس إلى موارد منفذ DR.
- تتوفر خدمات Azure كما هو مطلوب.
- العملية التي يجب اتباعها إذا لم يتم استيفاء أي من المتطلبات الأساسية.
- الاسترداد التقني - إرشادات خطوة بخطوة
- قم بتشغيل الطلب.
- وصف الخطوة.
- المتطلبات الأساسية للخطوة.
- خطوات عملية مفصلة لكل إجراء منفصل، بما في ذلك عناوين URL.
- إرشادات التحقق من الصحة، بما في ذلك الأدلة المطلوبة.
- الوقت المتوقع لإكمال كل خطوة، بما في ذلك الحالات الطارئة.
- العملية التي سيتم اتباعها إذا فشلت الخطوة.
- نقاط التصعيد في حالة الفشل أو دعم الشركات الصغيرة والمتوسطة.
- الاسترداد التقني - متطلبات النشر
- تأكيد الطابع الزمني للتاريخ الحالي للنظام عبر المكونات الرئيسية.
- تأكيد عناوين URL لنظام التعافي من الكوارث وعناوين IP.
- الاستعداد لعملية مراجعة أصحاب المصلحة في الأعمال، بما في ذلك تأكيد الوصول إلى الأنظمة وإكمال الشركات الصغيرة والمتوسطة للتحقق من الصحة والموافقة.
- مراجعة أصحاب المصلحة في الأعمال والموافقة عليها
- تفاصيل جهة اتصال مورد الأعمال.
- خطوات التحقق من صحة الأعمال وفقا للاسترداد التقني أعلاه.
- سجل الأدلة المطلوب من موافقة العمل على تسجيل الخروج من الاسترداد.
- متطلبات نشر الاسترداد
- التسليم إلى الدعم التشغيلي لتنفيذ عمليات البيانات لتحديث النظام.
- تسليم عمليات وحلول انتقال البيانات من الخادم - تأكيد تفاصيل التاريخ والاتصال لنظام الإصلاح بعد الكوارث.
- تأكد من اكتمال عملية الاسترداد مع عميل التعافي من الكوارث - تأكيد مسار الأدلة ودفتر التشغيل المكتمل.
- إعلام فرق الأمان بأنه يمكن إزالة امتيازات الوصول المرتفعة من فريق الإصلاح بعد الكوارث.
وسائل شرح
- يوصى بتضمين لقطات شاشة للنظام لكل عملية خطوة. ستساعد لقطات الشاشة هذه في معالجة التبعية على المؤسسات الصغيرة والمتوسطة الحجم للنظام لإكمال المهام.
- لمواكبة الخدمات السحابية المتطورة بسرعة، يجب إعادة النظر في خطة الاسترداد بعد الكوارث بانتظام واختبارها وتنفيذها بواسطة الموارد ذات المعرفة الحالية ب Azure وخدماتها.
- وينبغي أن تعكس خطوات الاسترداد التقني أولوية المكون والحل للمنظمة. على سبيل المثال، يتم استرداد تدفقات بيانات المؤسسة الأساسية قبل مختبرات تحليل البيانات المخصصة.
- يجب أن تتبع خطوات الاسترداد الفني ترتيب مهام سير العمل (عادة من اليسار إلى اليمين)، بمجرد استرداد المكونات أو الخدمة الأساسية مثل Key Vault. ستضمن هذه الاستراتيجية توفر تبعيات المصدر ويمكن اختبار المكونات بشكل مناسب.
- وبمجرد الانتهاء من الخطة المفصلة خطوة بخطوة، ينبغي الحصول على الوقت الإجمالي للأنشطة ذات الطوارئ. إذا تجاوز هذا الإجمالي هدف وقت الاسترداد المتفق عليه (RTO)، فهناك العديد من الخيارات المتاحة:
- أتمتة عمليات الاسترداد المحددة (حيثما أمكن).
- ابحث عن فرص لتشغيل خطوات الاسترداد المحددة بالتوازي (حيثما أمكن). ومع ذلك، لاحظ أن هذه الاستراتيجية قد تتطلب موارد إضافية لمنفذ DR.
- رفع المكونات الرئيسية إلى مستويات أعلى من مستويات الخدمة مثل PaaS، حيث تتحمل Microsoft مسؤولية أكبر عن أنشطة استرداد الخدمة.
- توسيع RTO مع أصحاب المصلحة.
اختبار الإصلاح بعد الكوارث
تؤدي طبيعة خدمة Azure Cloud التي تقدم إلى قيود لأي سيناريوهات اختبار DR. لذلك، فإن التوجيه هو الوقوف في اشتراك DR مع مكونات النظام الأساسي للبيانات كما ستكون متاحة في المنطقة الثانوية.
من هذا الأساس، يمكن تنفيذ دفتر تشغيل خطة DR بشكل انتقائي، مع إيلاء اهتمام خاص للخدمات والمكونات التي يمكن نشرها والتحقق من صحتها. ستتطلب هذه العملية مجموعة بيانات اختبار منسقة، مما يتيح تأكيد عمليات التحقق من صحة التقنية والأعمال وفقا للخطة.
يجب اختبار خطة الإصلاح بعد الكارثة بانتظام ليس فقط للتأكد من أنها محدثة، ولكن أيضا لبناء "ذاكرة العضلات" للفرق التي تقوم بأنشطة تجاوز الفشل والاسترداد.
- يجب أيضا اختبار النسخ الاحتياطية للبيانات والتكوين بانتظام للتأكد من أنها "مناسبة للغرض" لدعم أي أنشطة استرداد.
المجال الرئيسي الذي يجب التركيز عليه أثناء اختبار الإصلاح بعد الكوارث هو التأكد من أن الخطوات الوصفية لا تزال صحيحة وأن التوقيتات المقدرة لا تزال ذات صلة.
- إذا كانت الإرشادات تعكس شاشات المدخل بدلا من التعليمات البرمجية - يجب التحقق من صحة الإرشادات كل 12 شهرا على الأقل بسبب إيقاع التغيير في السحابة.
في حين أن الطموح هو أن يكون لديك عملية DR مؤتمتة بالكامل، قد يكون من غير المحتمل أن تكون الأتمتة الكاملة بسبب ندرة الحدث. لذلك، يوصى بإنشاء أساس الاسترداد باستخدام البنية الأساسية Desired State Configuration (DSC) كتعليق برمجي (IaC) يستخدم لتقديم النظام الأساسي ثم رفعه مع بناء المشاريع الجديدة على الأساس.
- مع مرور الوقت مع تمديد المكونات والخدمات، يجب فرض NFR، ما يتطلب إعادة بناء التعليمات البرمجية لمسار توزيع الإنتاج لتوفير تغطية الإصلاح بعد الكوارث.
إذا تجاوزت توقيتات دفتر التشغيل RTO الخاص بك، فهناك العديد من الخيارات:
- توسيع RTO مع أصحاب المصلحة.
- خفض الوقت المطلوب لأنشطة الاسترداد، عبر الأتمتة، أو تشغيل المهام بالتوازي أو الترحيل إلى مستويات خادم سحابة أعلى.
Azure Chaos Studio
Azure Chaos Studio هي خدمة مدارة لتحسين المرونة عن طريق إدخال الأخطاء في تطبيقات Azure. يمكنك Chaos Studio من تنسيق إدخال الخطأ على موارد Azure بطريقة آمنة ومتحكم بها، باستخدام التجارب. راجع وثائق المنتج للحصول على وصف أنواع الأخطاء المدعومة حاليا.
لا يغطي التكرار الحالي ل Chaos Studio سوى مجموعة فرعية من مكونات وخدمات Azure. حتى تتم إضافة المزيد من مكتبات الأخطاء، يعد Chaos Studio نهجا موصى به لاختبار المرونة المعزول بدلا من اختبار الإصلاح بعد الكوارث للنظام الكامل.
يمكن العثور على مزيد من المعلومات حول Chaos studio في وثائق Azure Chaos Studio.
استرداد موقع Azure
بالنسبة لمكونات IaaS، سيحمي Azure Site Recovery معظم أحمال العمل التي تعمل على جهاز ظاهري مدعوم أو خادم فعلي
هناك إرشادات قوية ل:
- تنفيذ Azure VM Disaster Recovery Drill
- تنفيذ تجاوز فشل DR إلى منطقة ثانوية
- تنفيذ احتياطي DR إلى المنطقة الأساسية
- تمكين أتمتة خطة الإصلاح بعد الكوارث
الموارد ذات الصلة
- التصميم للمرونة والتوافر
- استمرارية العمل والإصلاح بعد الكارثة
- النسخ الاحتياطي والتعافي من الكوارث لتطبيقات Azure
- المرونة في Azure
- ملخص اتفاقيات مستوى الخدمة (SLAs)
- خمس أفضل الممارسات لتوقع الفشل
الخطوات التالية
الآن بعد أن تعلمت كيفية نشر السيناريو، يمكنك قراءة ملخص DR لسلسلة النظام الأساسي لبيانات Azure.