تحليل التحويل في تعيين تدفق البيانات
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
تتوفر تدفقات البيانات في كل من Azure Data Factory وخطوط أنابيب Azure Synapse. تنطبق هذه المقالة على تعيين تدفقات البيانات. إذا كنت جديداً في مجال التحويلات، فيرجى الرجوع إلى المقالة التمهيدية تحويل البيانات باستخدام تدفق بيانات التعيين.
استخدم تحويل التحليل لتحليل الأعمدة فـي بياناتك الموجودة في نموذج المستند. الأنواع الحالية المدعومة من المستندات المضمنة التي يمكن تحليلها هي JSON وXML والنص المحدد.
التكوين
في لوحة تكوين تحويل التحليل، يمكنك أولا اختيار نوع البيانات المضمنة في الأعمدة التي ترغب في تحليلها مضمنة. يحتوي تحويل التحليل أيضاً على إعدادات التكوين التالية.

Column
على غرار الأعمدة والمجاميع المشتقة، تكون الخاصية Column هي المكان الذي تقوم فيه إما بتعديل عمود موجود عن طريق تحديده من منتقي القائمة المنسدلة. أو يمكنك كتابة اسم عمود جديد هنا. يخزن ADF بيانات المصدر التي تم تحليلها في هذا العمود. في معظم الحالات، تريد تعريف عمود جديد يوزع حقل سلسلة المستندات المضمنة الواردة.
تعبير
استخدم منشئ التعبير لتعيين المصدر للتحليل الخاص بك. يمكن أن يكون تعيين المصدر بسيطا مثل مجرد تحديد العمود المصدر مع البيانات المكتفية ذاتيا التي ترغب في تحليلها، أو يمكنك إنشاء تعبيرات معقدة لتحليلها.
تعبيرات سبيل المثال
بيانات سلسلة المصدر:
chrome|steel|plastic- التعبير:
(desc1 as string, desc2 as string, desc3 as string)
- التعبير:
بيانات JSON المصدر:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- التعبير:
(level as string, registration as long)
- التعبير:
بيانات JSON المتداخلة المصدر:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- التعبير:
(car as (model as string, year as integer), color as string, transmission as string)
- التعبير:
بيانات XML المصدر:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- التعبير:
(Customers as (Customer as integer, CompanyName as string))
- التعبير:
XML المصدر مع بيانات السمة:
<cars><car model="camaro"><year>1989</year></car></cars>- التعبير:
(cars as (car as ({@model} as string, year as integer)))
- التعبير:
التعبيرات ذات الأحرف المحجوزة:
{ "best-score": { "section 1": 1234 } }- لا يعمل التعبير أعلاه نظرا لأن الحرف '-' في
best-scoreيتم تفسيره على أنه عملية طرح. استخدم متغيرا مع رمز القوس في هذه الحالات لإخبار محرك JSON بتفسير النص حرفيا:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- لا يعمل التعبير أعلاه نظرا لأن الحرف '-' في
ملاحظة: إذا واجهت أخطاء في استخراج السمات (على وجه التحديد، @model) من نوع معقد، فإن الحل البديل هو تحويل النوع المعقد إلى سلسلة، وإزالة الرمز @ (على وجه التحديد، استبدال(toString(your_xml_string_parsed_column_name.cars.car)،'@'،') )، ثم استخدم نشاط تحويل JSON لتحليل.
نوع عمود الإخراج
إليك المكان الذي تقوم فيه بتكوين مخطط الإخراج الهدف من التحليل المكتوب في عمود واحد. أسهل طريقة لتعيين مخطط لإخراجك من التحليل هي حدد الزر "الكشف عن النوع" في الجزء العلوي الأيسر مـن منشئ التعبير. يحاول ADF الكشف التلقائي عن المخطط من حقل السلسلة، الذي تقوم بتحليله وتعيينه لك في تعبير الإخراج.
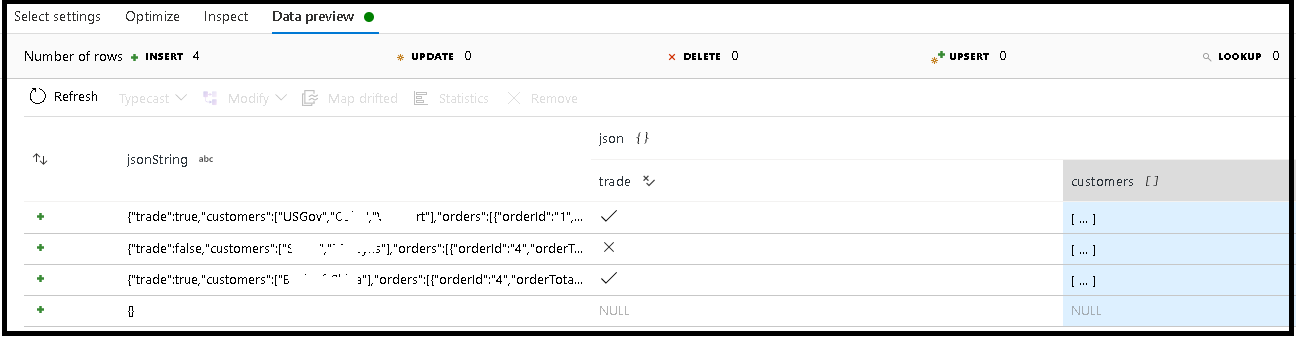
في هذا المثال، حددنا تحليل الحقل الوارد "jsonString"، وهو نص عادي، ولكنه منسق كبنية JSON. سنقوم بتخزين النتائج التي تم تحليلها بتنسيق JSON في عمود جديد يسمى "json" بهذا المخطط:
(trade as boolean, customers as string[])
ارجع إلى علامة التبويب فحص ومعاينة البيانات للتحقق من تعيين الإخراج بشكل صحيح.
استخدم نشاط العمود المشتق لاستخراج البيانات الهرمية (أي your_complex_column_name.car.model في حقل التعبير)
الأمثلة
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
البرنامج النصي لتدفق البيانات
بناء الجملة
الأمثلة
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
المحتوى ذو الصلة
- استخدم تبسيط التحويل لتحويل الصفوف إلى أعمدة محورية.
- استخدم تحويل العمود المشتق لتحويل الصفوف.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ