تنسيق دلتا في Azure Data Factory
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
توضح هذه المقالة كيفية نسخ البيانات من وإلى بحيرة دلتا المخزنة في Azure Data Lake Store Gen2 أو Azure Blob Storage باستخدام تنسيق دلتا. يتوفر هذا الموصل كـ مجموعة بيانات مضمنة في تعيين تدفقات البيانات كمصدر وحوض.
تعيين خصائص تدفق البيانات
يتوفر هذا الموصل كـ مجموعة بيانات مضمنة في تعيين تدفقات البيانات كمصدر وحوض.
خصائص المصدر
يسرد الجدول أدناه الخصائص التي يدعمها مصدر دلتا. يمكنك تحرير هذه الخصائص في علامة التبويب "Source options".
| الاسم | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| Format | يجب أن يكون التنسيق delta |
yes | delta |
format |
| نظام الملفات | نظام الحاوية / الملفات لبحيرة الدلتا | yes | السلسلة | fileSystem |
| مسار المجلد | دليل delta lake | yes | السلسلة | folderPath |
| نوع الضغط | نوع الضغط لجدول دلتا | no | bzip2gzipdeflateZipDeflatesnappylz4 |
نوع الضغط |
| مستوى الضغط | اختر ما إذا كان الضغط يكمل بأسرع وقت ممكن أو إذا كان يجب ضغط الملف الناتج بشكل أمثل. | مطلوب إذا compressedType لم يتم تحديده. |
Optimal أو Fastest |
compressionLevel |
| السفر عبر الزمن | اختيار ما إذا كنت تريد الاستعلام عن لقطة قديمة لجدول دلتا | no | الاستعلام حسب الطابع الزمني: الطابع الزمني الاستعلام حسب الإصدار: عدد صحيح |
الطابع الزمنيAsOf versionAsOf |
| السماح بعدم العثور على أي ملفات | إذا كان صحيحا، لا يتم طرح خطأ إذا لم يتم العثور على ملفات | no | true أو false |
ignoreNoFilesFound |
استيراد مخطط
تتوفر دلتا فقط كفئة بيانات مضمنة، ولا يوجد مخطط مقترن افتراضيًا. للحصول على بيانات تعريف العمود، انقر فوق الزر استيراد مخطط في علامة التبويب إسقاط . يسمح لك هذا بالإشارة إلى أسماء الأعمدة وأنواع البيانات المحددة بواسطة المجموعة. لاستيراد المخطط، يجب أن تكون جلسة تصحيح تدفق البيانات نشطة، ويجب أن يكون لديك ملف تعريف كيان CDM موجود للإشارة إليه.
مثال البرنامج النصي المصدر دلتا
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
خصائص المتلقّي
يسرد الجدول أدناه الخصائص التي يدعمها مصدر دلتا. يمكنك تحرير هذه الخصائص في علامة التبويب "Settings".
| الاسم | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| Format | يجب أن يكون التنسيق delta |
yes | delta |
format |
| نظام الملفات | نظام الحاوية / الملفات لبحيرة الدلتا | yes | السلسلة | fileSystem |
| مسار المجلد | دليل delta lake | yes | السلسلة | folderPath |
| نوع الضغط | نوع الضغط لجدول دلتا | no | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
نوع الضغط |
| مستوى الضغط | اختر ما إذا كان الضغط يكمل بأسرع وقت ممكن أو إذا كان يجب ضغط الملف الناتج بشكل أمثل. | مطلوب إذا compressedType لم يتم تحديده. |
Optimal أو Fastest |
compressionLevel |
| المكنسة | حذف الملفات الأقدم من المدة المحددة التي لم تعد ذات صلة بإصدار الجدول الحالي. عند تحديد قيمة 0 أو أقل، لا يتم تنفيذ عملية التفريغ. | yes | Integer | المكنسة |
| إجراء الجدول | اخبر ADF ما يجب فعله بجدول Delta الهدف في المتلقي. يمكنك تركها كما هي وإلحاق صفوف جديدة، أو استبدال تعريف الجدول والبيانات الموجودة ببيانات التعريف والبيانات الجديدة، أو الاحتفاظ ببنية الجدول الموجودة ولكن أولًا اقتطاع كافة الصفوف ثم إدراج الصفوف الجديدة. | no | بلا، اقتطاع، استبدال | deltaTruncate، الكتابة فوق |
| أسلوب التحديث | عند تحديد "السماح بالإدراج" وحده أو عند الكتابة إلى جدول دلتا جديد، يتلقى الهدف كافة الصفوف الواردة بغض النظر عن مجموعة نهج الصف. إذا كانت بياناتك تحتوي على صفوف من نهج الصفوف الأخرى، فيجب استبعادها باستخدام تحويل عامل تصفية سابق. عند تحديد كافة أساليب التحديث، يتم تنفيذ دمج، حيث يتم إدراج/حذف/تحديث/تحديث الصفوف وفقا لمجموعة نهج الصفوف باستخدام تحويل Alter Row السابق. |
yes | true أو false |
قابلة للادراج قابل للحذف upsertable قابل للتحديث |
| الكتابة المحسنة | تحقيق سرعة نقل أعلى لعملية الكتابة عن طريق تحسين خلط ورق اللعب الداخلي في منفذي Spark. نتيجة لذلك، قد تلاحظ عددًا أقل من الأقسام والملفات ذات الحجم الأكبر | no | true أو false |
optimizedWrite: صحيح |
| ضغط تلقائي | بعد اكتمال أي عملية كتابة، ستقوم Spark بتنفيذ الأمر تلقائيًا OPTIMIZE لإعادة تنظيم البيانات، ما يؤدي إلى المزيد من الأقسام إذا لزم الأمر، لتحسين أداء القراءة في المستقبل |
no | true أو false |
autoCompact: صحيح |
مثال البرنامج النصي لمتلقي دلتا
البرنامج النصي لتدفق البيانات المرتبط هو:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
متلقي دلتا مع تنقيح القسم
باستخدام هذا الخيار ضمن أسلوب التحديث أعلاه (أي التحديث/upsert/حذف)، يمكنك تحديد عدد الأقسام التي يتم فحصها. يتم جلب الأقسام التي تفي بهذا الشرط فقط من المخزن الهدف. يمكنك تحديد مجموعة ثابتة من القيم التي قد يأخذها عمود القسم.
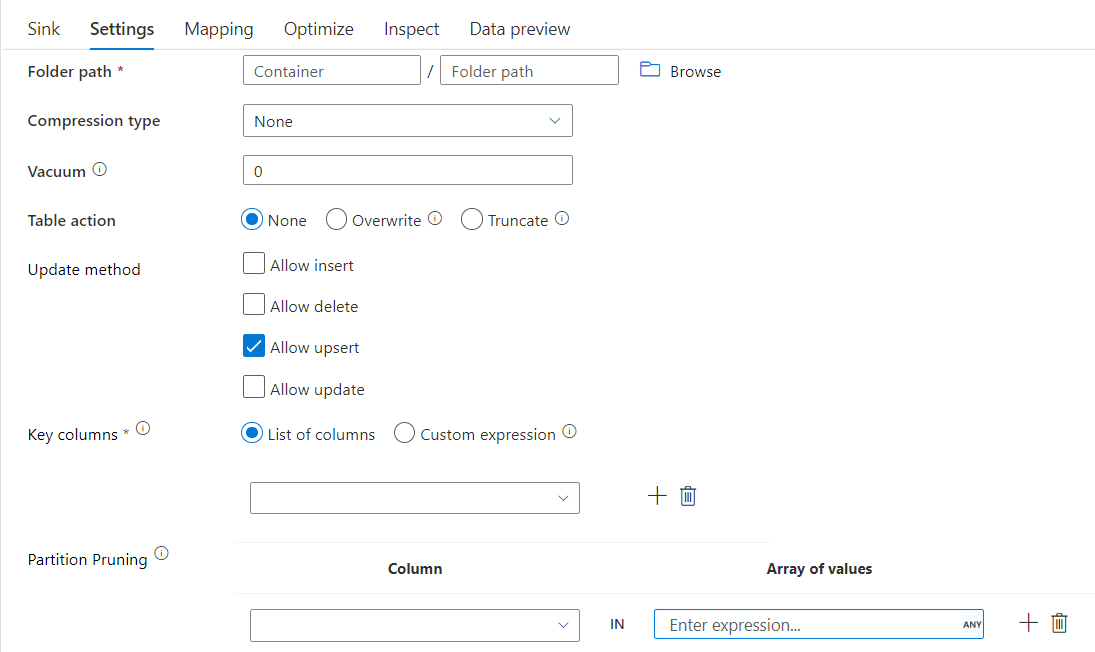
مثال البرنامج النصي لمتلقي دلتا مع تنقيح القسم
يتم إعطاء نموذج البرنامج النصي كما هو موضح أدناه.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
سيقرأ دلتا قسمين فقط حيث part_col == 5 و8 من مخزن دلتا الهدف بدلاً من جميع الأقسام. part_col هو عمود يتم من خلاله تقسيم بيانات دلتا الهدف. لا تحتاج إلى أن تكون موجودة في بيانات المصدر.
خيارات تحسين متلقي دلتا
في علامة التبويب الإعدادات، تجد ثلاثة خيارات أخرى لتحسين تحويل مصدر دلتا.
عند تمكين خيار دمج المخطط ، فإنه يسمح بتطور المخطط، أي تتم إضافة أي أعمدة موجودة في الدفق الوارد الحالي ولكن ليس في جدول Delta الهدف تلقائيا إلى مخططه. هذا الخيار مدعوم عبر جميع أساليب التحديث.
عند تمكين الضغط التلقائي، بعد الكتابة الفردية، يتحقق التحويل مما إذا كان يمكن ضغط الملفات بشكل أكبر، ويشغل مهمة تحسين سريعة (بأحجام ملفات 128 ميغابايت بدلاً من 1 غيغابايت) لمزيد من الملفات المضغوطة للأقسام التي تحتوي على أكبر عدد من الملفات الصغيرة. يساعد الضغط التلقائي في دمج عدد كبير من الملفات الصغيرة في عدد أصغر من الملفات الكبيرة. يبدأ الضغط التلقائي فقط عندما يكون هناك 50 ملفاً على الأقل. بمجرد تنفيذ عملية الضغط، يتم إنشاء إصدار جديد من الجدول، وكتابة ملف جديد يحتوي على بيانات العديد من الملفات السابقة في نموذج صغير مضغوط.
عند تمكين تحسين الكتابة، يعمل تحويل المتلقي على تحسين أحجام الأقسام بشكل ديناميكي استناداً إلى البيانات الفعلية عن طريق محاولة كتابة 128 ملف ميغابايت لكل قسم جدول. هذا حجم تقريبي ويمكن أن يختلف اعتماداً على خصائص مجموعة البيانات. تعمل عمليات الكتابة المحسنة على تحسين الكفاءة الإجمالية للكتابات والقراءات اللاحقة. وهو ينظم الأقسام بحيث يتحسن أداء القراءات اللاحقة.
تلميح
ستؤدي عملية الكتابة المحسنة إلى إبطاء مهمة ETL الإجمالية لأن المتلقي سيصدر الأمر تحسين Spark Delta Lake بعد معالجة بياناتك. يوصى باستخدام الكتابة المحسنة باعتدال. على سبيل المثال، إذا كان لديك مسار بيانات كل ساعة، فنفذ تدفق بيانات باستخدام الكتابة المحسنة يوميا.
القيود المعروفة
عند الكتابة إلى متلقي دلتا، هناك قيود معروفة حيث لن تظهر أرقام الصفوف المكتوبة في إخراج المراقبة.
المحتوى ذو الصلة
- قم بإنشاء تحويل مصدر في تعيين تدفق البيانات.
- قم بإنشاء تحويل متلقي في تعيين تدفق البيانات.
- إنشاء تحويل صف تبديل لوضع علامة على الصفوف على أنها إدراج أو تحديث أو رفع أو حذف.