إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
تتوفر تدفقات البيانات في خطوط أنابيب Azure Data Factory وخطوط أنابيب Azure Synapse Analytics. تنطبق هذه المقالة على تعيين تدفقات البيانات. إذا كنت جديدا على التحويلات، فراجع المقالة التمهيدية تحويل البيانات باستخدام تعيين تدفقات البيانات.
تلميح
للتحويل المكافئ (الحصول على البيانات) في Dataflow Gen2، راجع دليل Dataflow Gen2 لمستخدمي تدفق البيانات في خريطة الصورة.
يقوم تحويل المصدر بتكوين مصدر البيانات الخاص بك لتدفق البيانات. عند تصميم تدفق البيانات، تكون خطوتك الأولى هي تكوين تحويل مصدر. لإضافة مصدر، حدد خانة "Add Source" في لوحة تدفق البيانات.
يتطلب كل تدفق بيانات تحويل مصدر واحد على الأقل، ولكن يمكنك إضافة أكبر عدد من المصادر حسب الضرورة لإكمال تحويلات البيانات. يمكنك الانضمام إلى هذه المصادر مع صلة أو بحث أو تحويل اتحاد.
كل تحويل مصدر مقترن بمجموعة بيانات واحدة أو خدمة مرتبطة. تحدد مجموعة البيانات وشكل البيانات التي تريد الكتابة إليها أو القراءة منها وموقعها. إذا كنت تستخدم مجموعة بيانات مستندة إلى ملف، يمكنك استخدام أحرف البدل وقوائم الملفات في المصدر للعمل مع أكثر من ملف واحد في المرة الواحدة.
مجموعات البيانات المضمنة
أول قرار تتخذه عند إنشاء تحويل مصدر هو ما إذا كان يتم تعريف معلومات المصدر داخل عناصر مجموعة بيانات أو ضمن تحويل المصدر. تتوفر معظم التنسيقات في تنسيق واحد فقط أو الآخر. لمعرفة كيفية استخدام موصل محدد، راجع مستند الموصل المناسب.
عندما يتم اعتماد تنسيق لكل من العناصر المضمنة وفي عنصر مجموعة البيانات، يكون هناك فوائد لكليهما. عناصر مجموعة البيانات هي عناصر قابلة لإعادة الاستخدام يمكن استخدامها في تدفقات البيانات والأنشطة الأخرى مثل النسخ "Copy". هذه الكيانات القابلة لإعادة الاستخدام مفيدة بشكل خاص عند استخدام مخطط محصَّن. لا تستند مجموعات البيانات إلى "Spark". في بعض الأحيان، قد تحتاج إلى تجاوز إعدادات معينة أو إسقاط مخطط في تحويل المصدر.
يوصى بمجموعات البيانات المضمنة عند استخدام مخططات مرنة أو مثيلات مصدر لمرة واحدة أو مصادر ذات معلمات. إذا كان المصدر الخاص بك ذات معلمات كبيرة، مجموعات البيانات المضمنة تسمح لك عدم إنشاء عناصر "وهمية". تستند مجموعات البيانات المضمنة في "Spark" وخصائصها الأصلية لتدفق البيانات.
لاستخدام مجموعة بيانات مضمنة، حدد التنسيق الذي تريده في محدد "Source type". بدلاً من تحديد مجموعة بيانات مصدر، حدد الخدمة المرتبطة التي تريد الاتصال بها.
خيارات المخطط
نظرا لتعريف مجموعة بيانات مضمنة داخل تدفق البيانات، لا يوجد مخطط محدد مقترن بمجموعة البيانات المضمنة. في علامة التبويب إسقاط، يمكنك استيراد مخطط البيانات المصدر وتخزين هذا المخطط كإسقاط المصدر. في علامة التبويب هذه، يمكنك العثور على زر "خيارات المخطط" الذي يسمح لك بتحديد سلوك خدمة اكتشاف مخطط ADF.
- استخدام المخطط المتوقع: يكون هذا الخيار مفيدا عندما يكون لديك عدد كبير من الملفات المصدر التي يقوم ADF بفحصها كمصدر. السلوك الافتراضي لـ ADF هو اكتشاف مخطط كل ملف مصدر. ولكن إذا كان لديك إسقاط محدد مسبقا مخزن بالفعل في تحويل المصدر الخاص بك، يمكنك تعيين هذا إلى صحيح ويتخطى ADF الاكتشاف التلقائي لكل مخطط. مع تشغيل هذا الخيار، يمكن لتحويل المصدر قراءة جميع الملفات بطريقة أسرع بكثير، وتطبيق المخطط المحدد مسبقًا على كل ملف.
- السماح بانحراف المخطط: قم بتشغيل انحراف المخطط بحيث يسمح تدفق البيانات بأعمدة جديدة لم يتم تعريفها بالفعل في المخطط المصدر.
- التحقق من صحة المخطط: يؤدي تعيين هذا الخيار إلى فشل تدفق البيانات إذا كان أي عمود ونوع معرفين في الإسقاط لا يتطابقان مع المخطط المكتشف للبيانات المصدر.
- استنتاج أنواع الأعمدة المنجرفة: عند تحديد أعمدة منجرفة جديدة بواسطة ADF، يتم تحويل هذه الأعمدة الجديدة إلى نوع البيانات المناسب باستخدام الاستدلال التلقائي لنوع ADF.
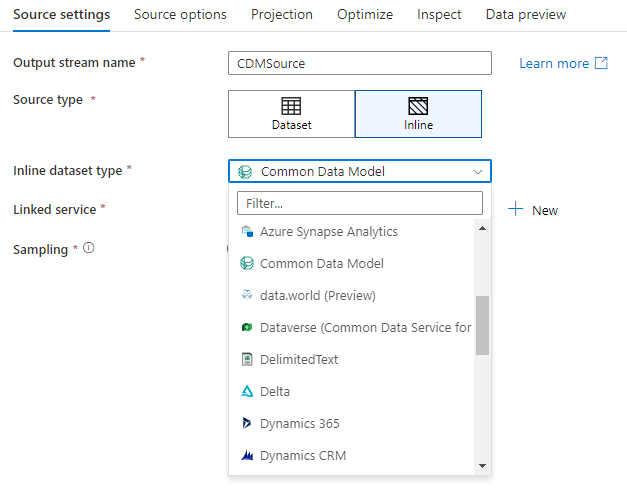
مساحة عمل قاعدة البيانات (مساحات عمل Synapse فقط)
في Azure Synapse مساحات العمل، يوجد خيار إضافي في تحويلات تدفق البيانات يسمى Workspace DB. يسمح لك هذا باختيار قاعدة بيانات مساحة عمل مباشرة من أي نوع متوفر كبيانات مصدر دون الحاجة إلى خدمات أو مجموعات بيانات مرتبطة إضافية. قواعد البيانات التي يتم إنشاؤها من خلال قوالب قواعد البيانات Azure Synapse يمكن الوصول إليها أيضا عند اختيار قاعدة بيانات مساحة العمل.
أنواع المصادر المدعومة
تتبع عملية تدفق البيانات نهج الاستخلاص والتحميل والتحويل (ELT) وتعمل مع مجموعات بيانات stageing جميعها في Azure. حالياً، يمكن استخدام مجموعات البيانات التالية في تحويل المصدر.
الإعدادات الخاصة بهذه الموصلات موجودة في علامة التبويب "Source options" توجد أمثلة البرامج النصية لتدفق المعلومات والبيانات على هذه الإعدادات في وثائق الموصل.
تحتوي خطوط أنابيب Azure Data Factory وSynapse على أكثر من موصل أصلي 90. لتضمين بيانات من تلك المصادر الأخرى في تدفق البيانات خاصتك، استخدم Copy Activity لتحميل تلك البيانات في إحدى مناطق التشغيل المرحلي المعتمدة.
إعدادات مصدر البيانات
بعد إضافة مصدر، قم بتكوينه عبر علامة التبويب "Source settings" هنا يمكنك اختيار أو إنشاء مجموعة بيانات نقاط المصدر في. يمكنك أيضاً تحديد خيارات المخطط وأخذ العينات للبيانات.
يمكن تكوين قيم التطوير لمعلمات مجموعة البيانات في إعداد تتبع الأخطاء. (يجب تشغيل وضع تتبع الأخطاء.)
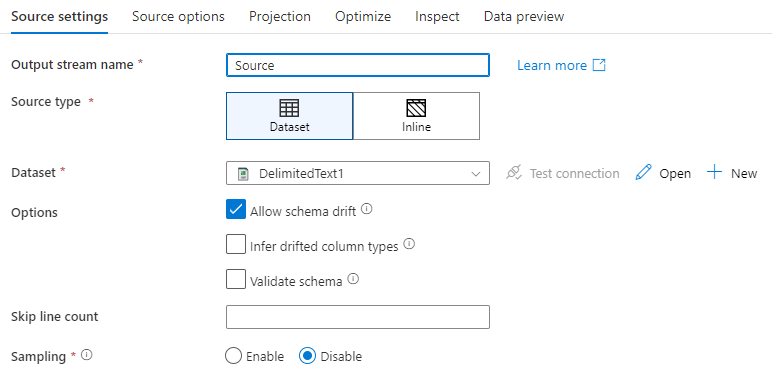
اسم تدفق الإنتاج: اسم تحويل المصدر.
"Source type": اختر ما إذا كنت تريد استخدام مجموعة بيانات مضمنة أو كائن مجموعة بيانات موجود.
"Test connection": اختبار ما إذا كان يمكن بنجاح الاتصال بخدمة Spark لتدفق البيانات إلى الخدمة المرتبطة المستخدمة في مجموعة البيانات المصدر. يجب تشغيل وضع تتبع الأخطاء لتمكين هذه الميزة.
انحراف المخطط: انحراف المخطط هو قدرة الخدمة على التعامل بشكل أصلي مع المخططات المرنة في تدفقات البيانات الخاصة بك دون الحاجة إلى تحديد تغيير حالة العمود بشكل صريح.
حدد خانة الاختيار السماح بانحراف المخطط إذا كانت الأعمدة المصدر تتغير كثيرا. يسمح هذا الإعداد لجميع حقول المصدر الواردة بالتدفق خلال التحويلات إلى المصدر.
يؤدي تحديد "Infer drifted column types" إلى توجيه الخدمة للكشف عن أنواع البيانات وتعريفها لكل عمود جديد تم اكتشافه. مع إيقاف تشغيل هذه الميزة، تكون جميع الأعمدة المنجرفة من سلسلة النوع.
التحقق من صحة المخطط: إذا تم تحديد التحقق من صحة المخطط ، يفشل تدفق البيانات في التشغيل إذا لم تتطابق بيانات المصدر الواردة مع المخطط المحدد لمجموعة البيانات.
"Skip line count": يحدد الحقل تخطي عدد الأسطر عدد الأسطر التي يجب تجاهلها في بداية مجموعة البيانات.
"Sampling": تمكين "Sampling" للحد من عدد الصفوف من المصدر. استخدم هذا الإعداد عند اختبار أو أخذ عينة بيانات من المصدر لأغراض تتبع الأخطاء. يُعد ذلك مفيد جداً عند تنفيذ تدفق البيانات في وضع تتبع الأخطاء من البنية الأساسية لبرنامج ربط العمليات التجارية.
للتحقق من صحة المصدر الخاص بك تكوين بشكل صحيح، تشغيل وضع تتبع الأخطاء وجلب الإصدار الأولي للبيانات. لمزيد من المعلومات، انظر نمط تتبع الأخطاء.
إشعار
عند تشغيل وضع التصحيح، يقوم تكوين حد الصف في إعدادات تتبع الأخطاء بالكتابة فوق إعداد أخذ العينات في المصدر أثناء معاينة البيانات.
خيارات المصدر
تحتوي علامة التبويب "Source options" على إعدادات خاصة بالموصل والتنسيق المختار. لمزيد من المعلومات والأمثلة، راجع وثائق الموصلذات الصلة. يشمل ذلك تفاصيل مثل مستوى العزل لمصادر البيانات التي تدعمه (مثل خوادم SQL المحلية، وقواعد بيانات Azure SQL، ومثيلات Azure SQL Manage)، بالإضافة إلى إعدادات أخرى خاصة بمصادر البيانات أيضا.
إسقاط
مثل المخططات في مجموعات البيانات، يحدد الإسقاط في مصدر أعمدة البيانات وأنواعها وتنسيقاتها من البيانات المصدر. بالنسبة لمعظم أنواع مجموعات البيانات، مثل SQL وParquet، يتم إصلاح الإسقاط في المصدر ليعكس المخطط المحدد في مجموعة بيانات، والتي ستختلف استنادا إلى المصدر. عندما لا تكون الملفات المصدر مكتوبة بقوة (على سبيل المثال، ملفات .csv المسطحة بدلاً من ملفات Parquet)، يُمكنك تحديد أنواع البيانات لكل حقل في تحويل المصدر. تعرض الصورة التالية مثالا للإسقاط:
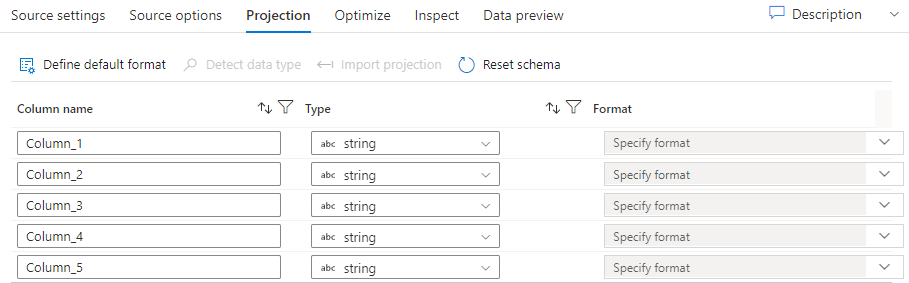
إذا لم يتضمن الملف النصي مخططا محددا، فحدد Detect data type بحيث تقوم الخدمة بنماذج أنواع البيانات واستدلالها. حدد "Define default format" للانتقاء التلقائي لتنسيقات البيانات الافتراضية.
"Reset schema" إعادة تعيين الإسقاط إلى ما هو معرف في مجموعة البيانات المشار إليها.
يسمح لك الكتابة فوق المُخطط بتعديل أنواع البيانات المتوقعة هنا المصدر، والكتابة فوق أنواع البيانات المعرفة بالمخطط. يمكنك بدلاً من ذلك تعديل أنواع بيانات العمود في تحويل عمود مشتق من انتقال البيانات من الخادم. استخدم تحويل التحديد لتعديل أسماء الأعمدة.
استيراد مخطط
حدد الزر "Import schema" في علامة التبويب "Projection" لاستخدام نظام مجموعة تتبع الأخطاء نشط لإنشاء إسقاط مخطط. وهي متوفرة في كل نوع مصدر. يتجاوز استيراد المخطط هنا الإسقاط المحدد في مجموعة البيانات. لن يتم تغيير كائن مجموعة البيانات.
استيراد المخطط مفيد في مجموعات البيانات مثل Avro و Azure Cosmos DB التي تدعم هياكل بيانات معقدة لا تتطلب تعريفات مخطط لوجود في مجموعة البيانات. بالنسبة لمجموعات البيانات المُضمنة، يعد استيراد المخطط هو الطريقة الوحيدة للإشارة إلى بيانات تعريف الأعمدة دون انجراف المخطط.
تحسين تحويل المصدر
تسمح علامة التبويب "Optimize" بتحرير معلومات القسم في كل خطوة تحويل. في معظم الحالات، يتم تحسين استخدام التقسيم الحالي لبنية التقسيم المثالية لمصدر.
إذا كنت تقرأ من مصدر قاعدة بيانات Azure SQL، فإن تقسيم Source المخصص غالبا يقرأ البيانات بأسرع حال. تقرأ الخدمة استعلامات كبيرة عن طريق إجراء اتصالات بقاعدة البيانات الخاصة بك بالتوازي. يمكن إجراء هذا التقسيم المصدر على عمود أو باستخدام الاستعلام.
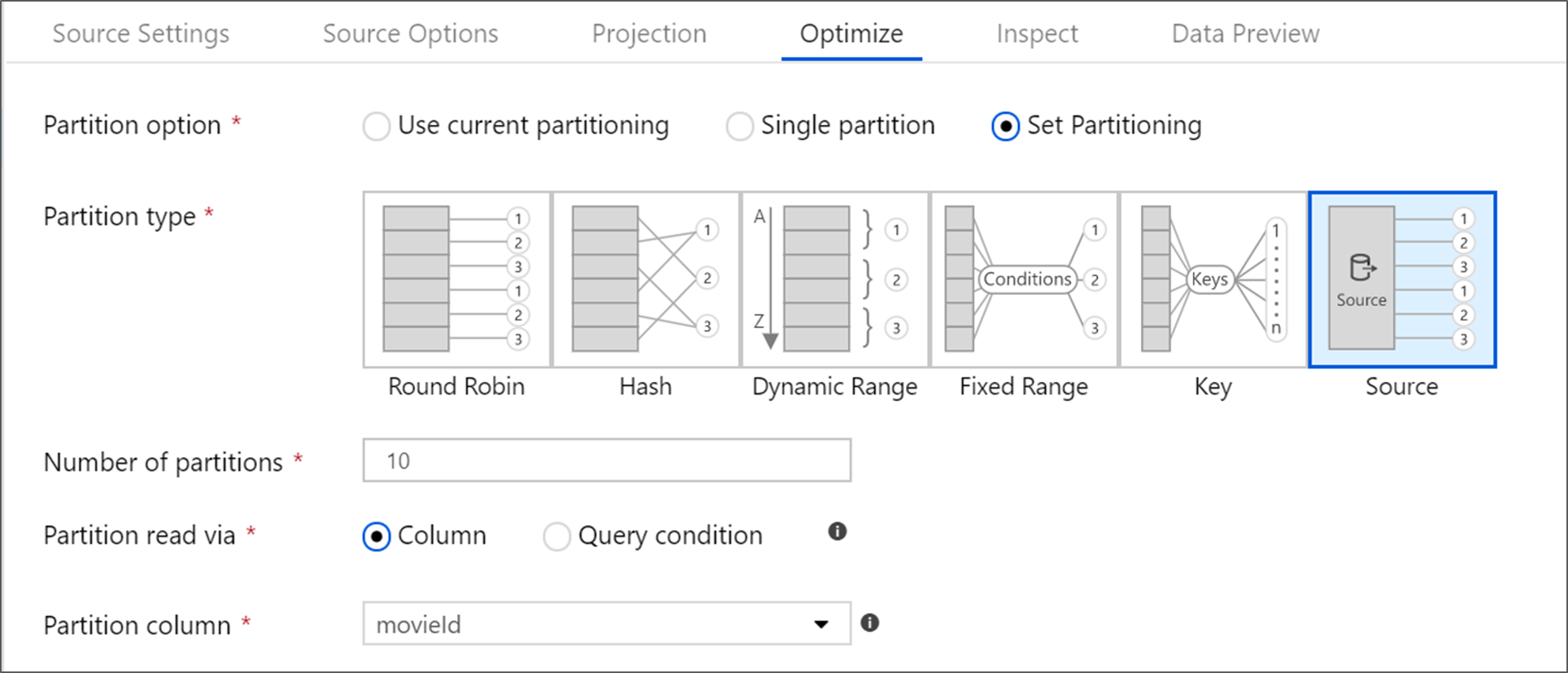
لمزيد من المعلومات حول التحسين ضمن تدفق بيانات التعيين، راجع "Optimize tab".
المحتوى ذو الصلة
ابدأ في إنشاء تدفق البيانات الخاص بك مع تحويل عمود مشتق والتحويل المحدد.