تنسيق ORC في Azure Data Factory وSynapse Analytics
ينطبق على:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
اتبع هذه المقالة عندما تريد تحليل ملفات ORC أو كتابة البيانات بتنسيق ORC.
تنسيق ORC مدعوم للموصلات التالية: Amazon S3، Amazon S3 Compatible Storage، Azure Blob، Azure Data Lake Storage Gen1، Azure Data Lake Storage Gen2، Azure Files، نظام الملفات، FTP ، Google Cloud Storage، HDFS وHTTP وOracle Cloud Storage وSFTP.
خصائص مجموعة البيانات
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات. يوفر هذا القسم قائمة بالخصائص التي تدعمها مجموعة بيانات ORC.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى ORC. | نعم |
| مكان | إعدادات الموقع للملف (الملفات). يحتوي كل موصل يستند إلى ملف على نوع الموقع الخاص به وخصائص مدعومة ضمن location. راجع التفاصيل الواردة في مقالة الموصل -> قسم خصائص مجموعة البيانات. |
نعم |
| compressionCodec | برنامج ضغط الوسائط وفكها، لاستخدامها عند الكتابة إلى ملفات ORC. عند القراءة من ملفات ORC تحدد Data Factories تلقائياً برنامج ضغط الوسائط وفكها استناداً إلى بيانات تعريف الملف. الأنواع المعتمدة هي none، وzlib، وsnappy (افتراضي)، وlzo. ملاحظة: حالياً لا يدعم نشاط النسخ LZO عند قراءة/كتابة ملفات ORC. |
لا |
وفيما يلي مثال على مجموعة بيانات ORC على مخزن البيانات الثنائية الكبيرة الحجم لـ Azure:
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
لاحظ النقاط التالية:
- أنواع البيانات المعقدة (مثل MAP، LIST، STRUCT) معتمدة حالياً فقط في تدفقات البيانات، وليس في نشاط النسخ. لاستخدام أنواع معقدة في تدفق البيانات، لا تقم باستيراد مخطط الملف في مجموعة البيانات، تاركاً المخطط فارغاً في مجموعة البيانات. وبعد ذلك، في تحويل المصدر، قم باستيراد الإسقاط.
- المسافة البيضاء في اسم العمود غير مدعومة.
انسخ خصائص النشاط
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف الأنشطة، راجع مقالة التدفقات. يوفر هذا القسم قائمة الخصائص المعتمدة من قبل مصدر ORC ومتلقيه.
ODBC كمصدر
يتم دعم الخصائص التالية في جزء نسخ النشاط *Source*.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مصدر نشاط النسخ إلى: OrcSource. | نعم |
| إعدادات المخزن | lمجموعة من الخصائص حول كيفية قراءة البيانات من مخزن بيانات. يحتوي كل موصل يستند إلى ملف إعدادات القراءة المدعومة الخاصة به ضمن storeSettings. راجع التفاصيل في مقالة الموصل -> قسم خصائص نسخ النشاط. |
لا |
ORC كمتلقي
الخصائص التالية مدعومة في نشاط النسخ * lمتلقي * القسم.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع متلقي نشاط النسخ إلى: OrcSink. | نعم |
| إعدادات التنسيقات | مجموعة من الخصائص. راجع جدول إعدادات كتابة ORC أدناه. | لا |
| إعدادات المخزن | مجموعة من الخصائص حول كيفية كتابة البيانات إلى مخزن بيانات. يحتوي كل موصل يستند إلى ملف إعدادات الكتابة المعتمدة الخاصة به ضمن storeSettings. راجع التفاصيل في مقالة الموصل -> قسم خصائص نسخ النشاط. |
لا |
إعدادات كتابة ORC المعتمدة الواردة ضمن formatSettings:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين نوع formatSettings إلى OrcWriteSettings. | نعم |
| maxRowsPerFile | عند كتابة البيانات في مجلد، يمكنك اختيار الكتابة إلى ملفات متعددة وتحديد الصفوف القصوى لكل ملف. | لا |
| fileNamePrefix | قابل للتطبيق عند تكوين maxRowsPerFile.حدد بادئة اسم الملف عند كتابة البيانات إلى ملفات متعددة، مما أدى إلى هذا النمط: <fileNamePrefix>_00000.<fileExtension>. إذا لم يتم تحديد، سيتم إنشاء بادئة اسم الملف تلقائياً. لا تنطبق هذه الخاصية عندما يكون المصدر مخزن مستند إلى ملف أو مخزن بيانات تمكين خيار القسم. |
لا |
تعيين خصائص تدفق البيانات
في تخطيط التدفقات للبيانات، يمكنك القراءة والكتابة لتنسيق ORC في مخازن البيانات الآتية: Azure Blob Storageو Azure Data Lake Storage Gen1وAzure Data Lake Storage Gen2وSFTP ويمكنك قراءة تنسيق ORC فيAmazon S3.
يمكنك الإشارة إلى ملفات ORC إما باستخدام مجموعة بيانات ORC أو باستخدام مجموعة بيانات مضمنة.
خصائص المصدر
يسرد الجدول أدناه الخصائص المعتمدة من قبل مصدر ORC. يمكنك تحرير هذه الخصائص في علامة التبويب "Source options".
عند استخدام مجموعة البيانات المضمنة، سترى إعدادات إضافية، وهي نفس الخصائص الموضحة في قسم خصائص مجموعة البيانات.
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| Format | يجب أن يكون التنسيق orc |
yes | orc |
format |
| مسارات محرف البدل | ستتم معالجة جميع الملفات المطابقة لمسار محرف البدل. يتجاوز المجلد ومسار الملف المحددين في مجموعة البيانات. | no | سلسلة[] | wildcardPaths |
| مسار جذر التقسيم | بالنسبة لبيانات الملف المقسمة، يمكنك إدخال مسار جذر القسم لقراءة المجلدات المقسمة كأعمدة | no | السلسلة | partitionRootPath |
| قائمة الملفات | ما إذا كان المصدر يشير إلى ملف نصي يسرد الملفات المراد معالجتها | no | true أو false |
قائمة الملفات |
| عمود لتخزين اسم الملف | إنشاء عمود جديد باسم الملف المصدر ومساره | no | السلسلة | rowUrlColumn |
| بعد الانتهاء | احذف أو انقل الملفات بعد المعالجة. مسار الملف يبدأ من جذر الحاوية | no | حذف: true أو false نقل: [<from>, <to>] |
إزالة الملفات نقل الملفات |
| التصفية حسب آخر تعديل | اختيار تصفية الملفات استناداً إلى آخر مرة تم تبديلها | no | طابع زمني | تم التعديل بعد ذلك modifiedBefore |
| السماح بعدم العثور على أي ملفات | إذا كان هذا صحيحاً، فلن يتم طرح خطأ إذا لم يتم العثور على ملفات | no | true أو false |
ignoreNoFilesFound |
مثال المصدر
البرنامج النصي لتدفق البيانات المقترن تكوين مصدر ORC هو:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
خصائص المتلقّي
يسرد الجدول أدناه الخصائص المعتمدة من قبل متلقي ORC. يمكنك تحرير هذه الخصائص في علامة التبويب "Settings".
عند استخدام مجموعة البيانات المضمنة، سترى إعدادات إضافية، وهي نفس الخصائص الموضحة في قسم خصائص مجموعة البيانات.
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| Format | يجب أن يكون التنسيق orc |
yes | orc |
format |
| مسح المجلد | إذا تم مسح المجلد الوجهة قبل الكتابة | no | true أو false |
اقتطاع |
| خيار اسم الملف | تنسيق تسمية البيانات المكتوبة. بشكل افتراضي، ملف واحد لكل قسم بالتنسيق part-#####-tid-<guid> |
no | النمط: سلسلة لكل قسم: سلسلة[] كبيانات في العمود: سلسلة الإخراج إلى ملف واحد: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
مثال على المتلقي
البرنامج النصي لتدفق البيانات المقترن بتكوين متلقي ORC هو:
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
استخدام وقت تشغيل التكامل المستضاف ذاتياً
هام
بالنسبة للنسخة المُمكّنة بواسطة وقت تشغيل التكامل المستضاف ذاتياً، على سبيل المثال: بين مخازن البيانات المحلية والسحابية، إذا كنت لا تنسخ ملفات ORC كما هي، فأنت بحاجة إلى تثبيت 64 بت JRE 8 (Java Runtime Environment) أو OpenJDK ، وحزمة Microsoft Visual C++ 2010 القابلة لإعادة التوزيع على جهاز IR الخاص بك. تحقق من الفقرة التالية مع مزيد من التفاصيل.
بالنسبة للنسخة التي تعمل على وقت تشغيل التكامل المستضاف ذاتياً مع تسلسل/إلغاء تسلسل ملف ORC، تحدد الخدمة وقت تشغيل Java عن طريق التحقق أولاً من السجل (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) لـ JRE، إذا لم يتم العثور عليه، وثانياً تتحقق من متغير النظام JAVA_HOME لـ OpenJDK.
- لاستخدام JRE: يتطلب IR 64 بت JRE 64 بت. يمكنك العثور عليه من هنا.
- لاستخدام OpenJDK: معتمد منذ إصدار IR 3.13. جمّع jvm.dll مع كل التجميعات الأخرى المطلوبة من OpenJDK في جهاز وقت تشغيل التكامل المستضاف ذاتياً، وعيّن متغير بيئة النظام JAVA_HOME وفقاً لذلك.
- لتثبيت حزمة Visual C++ 2010 القابلة لإعادة التوزيع: حزمة Visual C++ 2010 القابلة لإعادة التوزيع غير مثبتة مع تثبيتات وقت تشغيل التكامل المستضاف ذاتياً. يمكنك العثور عليه من هنا.
تلميح
إذا قمت بنسخ البيانات من /إلى تنسيق ORC باستخدام وقت تشغيل التكامل المستضاف ذاتياً وظهرت رسالة خطأ تقول "حدث خطأ عند استدعاء جافا، الرسالة: java.lang.OutOfMemoryError:Java heap space"، يمكنك إضافة متغير بيئة _JAVA_OPTIONS في الجهاز الذي يستضيف وقت تشغيل التكامل المستضاف ذاتياً لضبط الحد الأدنى / الأقصى لحجم كومة الذاكرة المؤقتة لـ JVM لتمكين هذه النسخة، ثم إعادة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
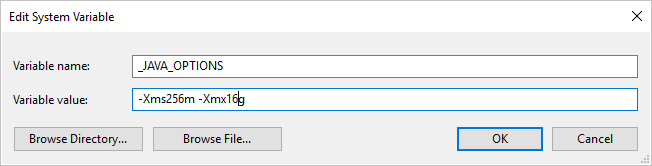
كمثال: تعيين متغير _JAVA_OPTIONS مع قيمة -Xms256m -Xmx16g. تحدد العلامة Xms تجمع تخصيص الذاكرة الأولى لآلة جافا الافتراضية (JVM)، بينما تحدد Xmx مجموعة تخصيص الذاكرة القصوى. هذا يعني أن JVM ستبدأ بمقدار Xms من الذاكرة وستكون قادرة على استخدام الحد الأقصى من الذاكرة بمقدار Xmx. تستخدم الخدمة الحد الأدنى 64 ميجابايت 1 جيجا بايت كحد أقصى، بشكل افتراضي.