نسخ البيانات من قاعدة بيانات SQL Server إلى مخزن البيانات الثنائية كبيرة الحجم في Azure باستخدام أداة Copy Data
ينطبق على:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
يمكنك في هذا التشغيل السريع استخدام مدخل Azure لإنشاء مصنع بيانات. ثم يمكنك استخدام أداة Copy Data لإنشاء مسار ينسخ البيانات من قاعدة بيانات SQL Server إلى مخزن البيانات الثنائية كبيرة الحجم في Azure.
إشعار
- إذا كنت عضوًا جديدًا في Azure Data Factory، راجع مقدمة عن Data Factory.
في هذا البرنامج التعليمي، يمكنك تنفيذ الخطوات التالية:
- إنشاء data factory.
- استخدام أداة Copy Data لإنشاء مسار.
- مراقبة تشغيل التدفق والنشاط.
المتطلبات الأساسية
اشتراك Azure
في حال لم يكن لديك اشتراك على Azure، ينبغي إنشاء حساب مجاني قبل البدء.
أدوار Azure
لإنشاء مثيلات مصنع البيانات، يجب تعيين دور Contributor أو Owner لحساب المستخدم الذي تستخدمه لتسجيل الدخول إلى Azure أو يجب أن يكون administrator في اشتراك Azure.
لعرض الأذونات التي لديك في الاشتراك، انتقِل إلى مدخل Azure. حدد اسم المستخدم في الزاوية العلوية اليمنى، ثم حدد Permissions. إذا كان لديك حق الوصول إلى اشتراكات متعددة، فحدّد الاشتراك المناسب. للحصول على نماذج من الإرشادات حول كيفية إضافة مستخدم إلى دور، راجع مقالة تعيين أدوار Azure باستخدام مدخل Azure.
SQL Server 2014، و2016، و2017
في هذا البرنامج التعليمي، يمكنك استخدام قاعدة بيانات SQL Server كمخزن بيانات المصدر. المسار في مصنع البيانات الذي تنشئه في هذا البرنامج التعليمي يعمل على نسخ البيانات من قاعدة البيانات SQL Server هذه (المصدر) لتخزين مخزن البيانات الثنائية كبيرة الحجم (المتلقي). ثم أنشئ جدولاً باسم emp في قاعدة بيانات SQL Server ثم أدرج اثنين من إدخالات النموذج في الجدول.
بدء تشغيل SQL Server Management Studio. إذا لم يكن مثبتًا من قبل على جهازك، فانتقِل إلى تنزيل SQL Server Management Studio.
الاتصال إلى مثيل SQL Server باستخدام بيانات الاعتماد الخاصة بك.
أنشئ نموذج قاعدة البيانات. في طريقة العرض الشجرية، انقر بزر الماوس الأيمن فوق قواعد البيانات، ثم حدد قاعدة بيانات جديدة.
في نافذة قاعدة بيانات جديدة أدخِل اسمًا لقاعدة البيانات، ثم حدد موافق.
لإنشاء جدول emp وإدراج بعض بيانات النموذج فيه، شغّل البرنامج النصي التالي للاستعلام مقابل قاعدة البيانات. في طريقة العرض الشجرية، انقر بزر الماوس الأيمن فوق قاعدة البيانات التي قمت بإنشائها، ثم حدد New Query.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
حساب مخزن Azure
في هذا البرنامج التعليمي، يمكنك استخدام حساب تخزين Azure للأغراض العامة (وخاصةً مخزن البيانات الثنائية كبيرة الحجم) كمخزن بيانات الوجهة/المتلقي. إذا لم يكن لديك حساب مساحة تخزين للأغراض العامة، فراجع إنشاء حساب مساحة تخزين لإنشاء واحد. يعمل المسار في مصنع البيانات الذي تنشئه في هذا البرنامج التعليمي على نسخ البيانات من قاعدة بيانات SQL Server (المصدر) إلى مخزن البيانات الثنائية كبيرة الحجم هذا (المتلقي).
الحصول على اسم حساب مساحة التخزين ومفتاح الحساب
يمكنك استخدام اسم ومفتاح حسابك على مساحة التخزين في هذا البرنامج التعليمي. للحصول على اسم حساب مساحة التخزين ومفتاحه، يُرجى إجراء الخطوات التالية:
سجّل الدخول إلى مدخل Azure باستخدام اسم المستخدم وكلمة المرور على Azure.
في القائمة اليسرى، حدد جميع الخدمات. أجرِ التصفية باستخدام الكلمة الرئيسية Storage، ثم حدد Storage accounts.
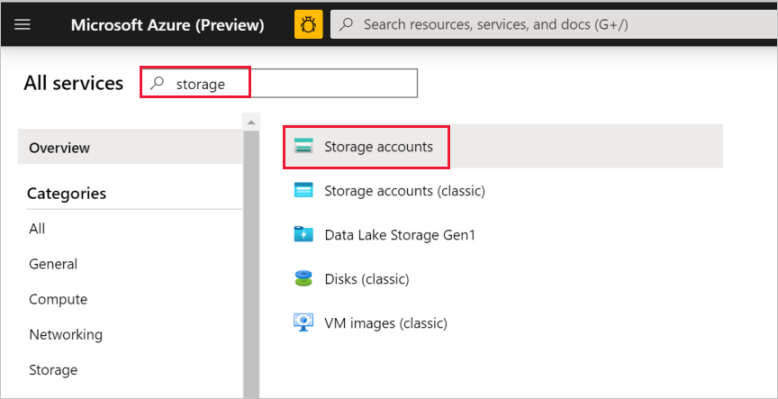
في قائمة حسابات مساحة التخزين، أجرِ تصفية حسابك على مساحة التخزين إذا لزم الأمر. ثم حدد حسابك على مساحة التخزين.
في نافذة Storage account حدد Access keys.
في المربعات Storage account name وkey1، انسخ القيم ثم الصقها في Notepad أو محرر آخر لاستخدامها لاحقًا في البرنامج التعليمي.
إنشاء مصدرًا للبيانات
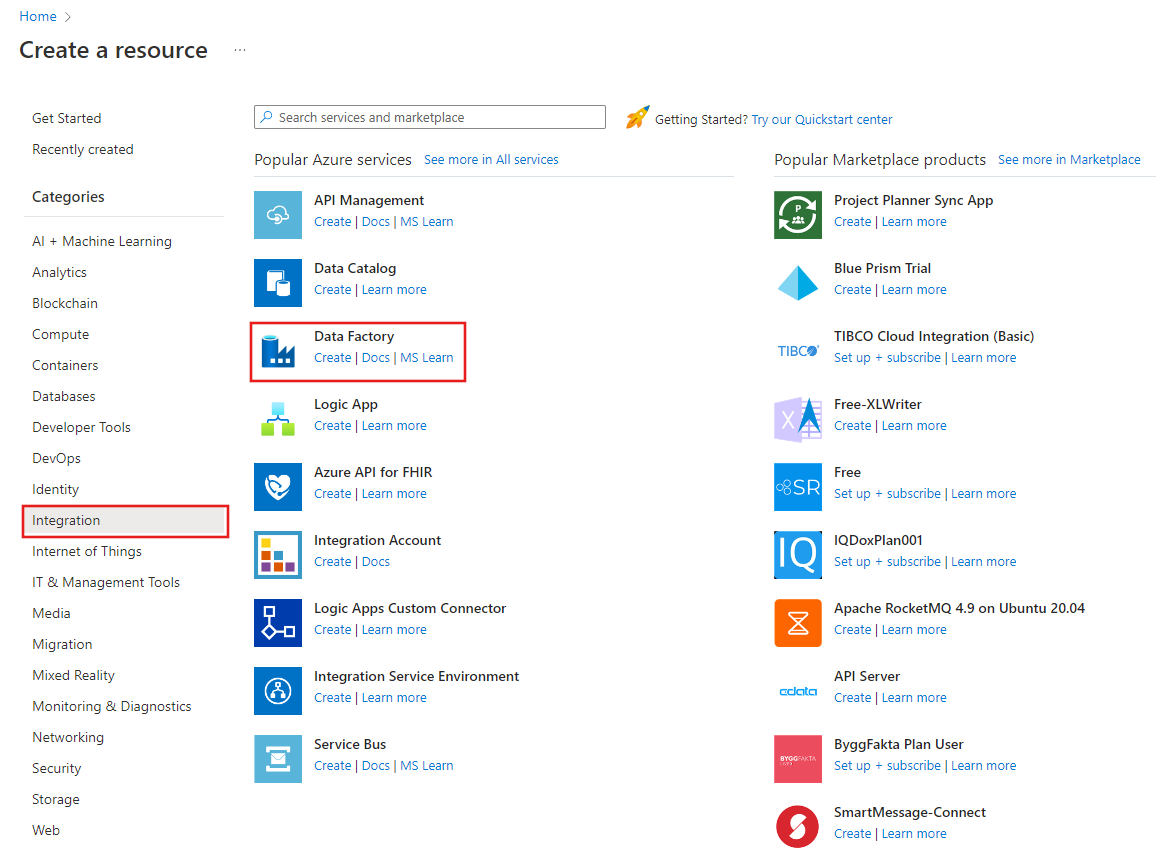
في القائمة اليسري، حدد Create a resource>Integration>Data Factory.
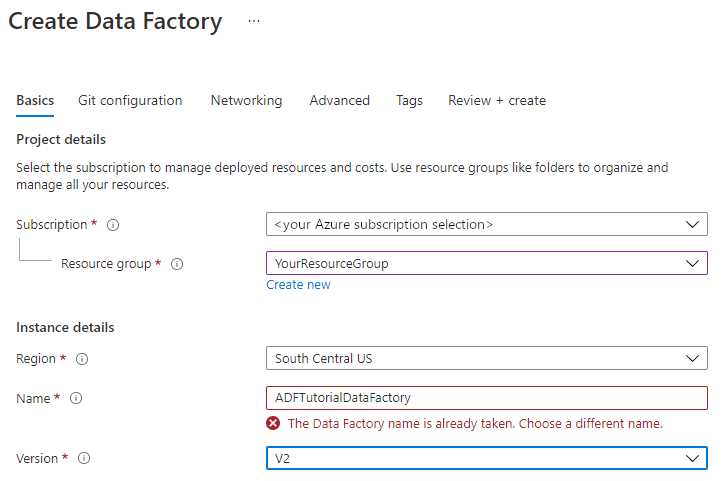
في صفحة New data factory، أدخِل ADFTutorialDataFactory في خانة Name.
يجب أن يكون اسم مصنع البيانات مميزًا وعامًا. إذا رأيت رسالة الخطأ التالية لحقل الاسم، فغيّر اسم مصنع البيانات (على سبيل المثال، yournameADFTutorialDataFactory). للحصول على قواعد التسمية للبيانات الاصطناعية على Data Factory، راجع قواعد تسمية Data Factory.
حدد subscription على Azure الذي تريد إنشاء مصنع البيانات فيه.
بالنسبة إلى مجموعة الموارد، نفِّذ إحدى الخطوات التالية:
حدد Use existing واختر مجموعة موارد موجودة من القائمة المنسدلة.
حدد Create new وأدخل اسم مجموعة الموارد.
للتعرف على مجموعات الموارد، راجع استخدام مجموعات الموارد لإدارة موارد Azure التابعة لك.
ضمن Version، حدد V2.
ضمن Location، حدد موقع مصنع البيانات. لن تظهر القائمة المنسدلة إلا على المواقع المعتمدة فقط. يمكن أن تكون مخازن البيانات (على سبيل المثال، مخازن Azure وقاعدة بيانات SQL) ومراكز الحوسبة (على سبيل المثال، Azure HDInsight) المستخدمة في Data Factory مستخدمة أيضًا في مناطق/مواقع أخرى.
حدد إنشاء.
بعد الانتهاء من الإنشاء، ستظهر صفحة Data Factory كما هو موضح في الصورة.

حدد Open على تجانب Open Azure Data Factory Studio لبدء تشغيل تطبيق واجهة مستخدم Azure Data Factory الموجود في علامة تبويب منفصلة.
استخدام أداة Copy Data لإنشاء مسار
في صفحة Azure Data Factory الرئيسية، حدد Ingest لبدء تشغيل أداة Copy Data.
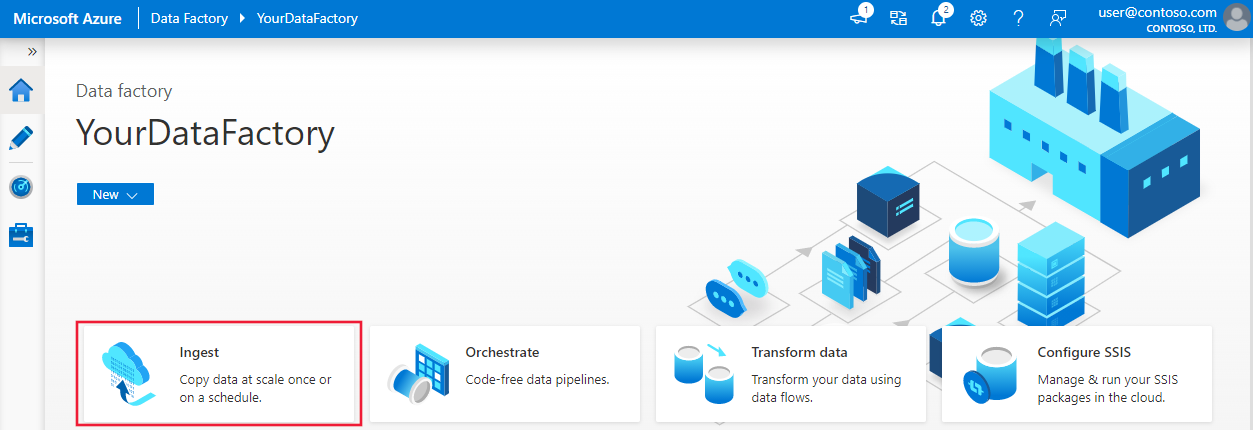
في صفحة Properties لأداة Copy Data، اختر Built-in copy task ضمن Task type، واختر Run once now ضمن Task cadence or task schedule، ثم اختر Next.
في صفحة Source data store، حدد + Create new connection.
ضمن New connection، ابحث عن SQL Server، ثم حدد Continue.
في مربع الحوار New connection (SQL server)، ضمن Name، أدخِل SqlServerLinkedService. حدد +New ضمن Connect via integration runtime. يجب إنشاء وقت تشغيل تكامل ذاتي الاستضافة، وتنزيله إلى جهازك، وتسجيله باستخدام Data Factory. يعمل وقت تشغيل التكامل ذاتي الاستضافة على نسخ البيانات بين البيئة المحلية والسحابة.
في مربع الحوار Integration runtime setup، حدد Self-Hosted. بعد ذلك، حدد متابعة.

في مربع الحوار Integration runtime setup، ضمن Name، أدخِل TutorialIntegrationRuntime. وبعد ذلك، حدد إنشاء.
في مربع الحوار Integration runtime setup، حدد Click here to launch the express setup for this computer. يعمل هذا الإجراء على تثبيت وقت تشغيل التكامل على جهازك وتسجيله باستخدام Data Factory. بدلاً من ذلك، يمكنك استخدام خيار الإعداد اليدوي لتحميل ملف التثبيت وتشغيله واستخدام المفتاح لتسجيل وقت تشغيل التكامل.
شغّل التطبيق الذي تم تنزيله. راجع حالة الإعداد السريع في النافذة.

في مربع الحوار New Connection (SQL Server)، تأكد من تحديد TutorialIntegrationRuntime ضمن Connect via integration runtime. ثم اتخذ الخطوات التالية:
أ. ضمن Name، أدخِل SqlServerLinkedService.
ب. ضمن Server name، أدخِل اسم مثيل SQL Server.
جـ. ضمن Database name، أدخِل اسم قاعدة البيانات المحلية.
د. ضمن Authentication type، حدد المصادقة المناسبة.
هـ. ضمن User name، أدخِل اسم المستخدم الذي له حق الوصول إلى SQL Server.
و. أدخِل كلمة مرور للمستخدم.
ز. اختبر الاتصال ثم حدد Create.

في الصفحة Source data store، تأكد من تحديد اتصال SQL Server الذي تم إنشاؤه حديثًا في كتلة الاتصال. ثم في القسم Source tables، اختر EXISTING TABLES، وحدد الجدول dbo.emp في القائمة، وحدد Next. يمكنك تحديد أي جدول آخر على أساس قاعدة البيانات.
في صفحة Apply filter، يمكنك معاينة البيانات وعرض مخطط بيانات الإدخال عن طريق تحديد الزر Preview data. بعد ذلك حدد التالي.
في صفحة Destination data store، حدد + Create new connection
حدد New connection، ثم حدد Azure Blob Storage، في نافذة Continue.

في مربع الحوار New connection (Azure Blob Storage)، اتخذ الخطوات التالية:
أ. ضمن Name، أدخِل AzureStorageLinkedService.
ب. ضمن Connect via integration runtime، حدد TutorialIntegrationRuntime، ثم حدد Account key ضمن Authentication method.
جـ. ضمن Azure subscription، حدد اشتراكك على Azure من القائمة المنسدلة.
د. ضمن Storage account name، حدد حساب مساحة التخزين من القائمة المنسدلة.
هـ. اختبر الاتصال ثم حدد Create.
في مربع الحوار Destination data store، تأكد من تحديد اتصال Azure Blob Storage الذي تم إنشاؤه حديثًا في كتلة Connection. ثم ضمن Folder path، أدخِل adftutorial/fromonprem. لقد أنشئت حاوية adftutorial كجزء من المتطلبات الأساسية. إذا لم يكن مجلد الناتج موجودًا (في هذه الحالة fromonprem)، فسيعمل Data Factory على إنشائه تلقائيًا. يمكنك أيضًا استخدام الزر Browse لاستعراض مخزن البيانات الثنائية كبيرة الحجم وحاوياته/مجلداته. إذا لم تحدد أي قيمة ضمن File name، فسيتم استخدام الاسم من المصدر تلقائيًا (في هذه الحالة dbo.emp).

في مربع الحوار File format settings، حدد Next.
في صفحة Settings، ضمن Task name، أدخل CopyFromBlobToSqlPipeline، ثم حدد Next. تنشئ أداة Copy Data مسارًا بالاسم الذي تحدده لهذا الحقل.
في مربع الحوار Summary، راجع قيم جميع الإعدادات، وحدد Next.
في صفحة Deployment، حدد Monitor لمراقبة المسار الذي أنشأته (مهمة).
عند اكتمال تشغيل المسار، يمكنك عرض حالة المسار الذي أنشأته.
في صفحة «Pipeline runs»، حدد Refresh لتحديث القائمة. حدد الرابط الموجود ضمن Pipeline name لعرض تفاصيل تشغيل النشاط أو إعادة تشغيل المسار.

في صفحة «Activity runs»، حدد رابط Details (أيقونة النظارات) أسفل عمود Activity name للحصول على المزيد من التفاصيل حول عملية النسخ. للعودة إلى صفحة «Pipeline runs»، حدد الرابط All pipeline runs في قائمة «breadcrumb». لإعادة تنشيط طريقة العرض، حدد Refresh.

تأكد من رؤية ملف الإخراج في مجلد fromonprem من الحاوية adftutorial.
حدد علامة تبويب Author على اليسار للتبديل إلى وضع المحرر. يمكنك تحديث الخدمات المرتبطة ومجموعات البيانات والمسارات التي أنشأتها الأداة باستخدام المحرر. حدد Code لعرض رمز JSON المقترن بالكيان المفتوح في المحرر. للحصول على تفاصيل حول تحرير هذه الكيانات في واجهة مستخدم Data Factory، راجع إصدار مدخل Azure من هذا البرنامج التعليمي.

المحتوى ذو الصلة
ينسخ المسار في هذا النموذج البيانات من قاعدة بيانات SQL Server إلى مخزن البيانات الثنائية كبيرة الحجم. لقد تعرفت على كيفية:
- إنشاء data factory.
- استخدام أداة Copy Data لإنشاء مسار.
- مراقبة تشغيل التدفق والنشاط.
للحصول على قائمة مخازن البيانات المدعومة من Data Factory، راجع مخازن البيانات المعتمدة.
للتعرف على كيفية نسخ البيانات بشكل مجمع من مصدر إلى وجهة، انتقِل إلى البرنامج التعليمي التالي: