نسخ البيانات من مخزن Azure Blob إلى قاعدة بيانات في قاعدة بيانات azure SQL باستخدام Azure Data Factory
ينطبق على:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
في هذا البرنامج التعليمي، يمكنك إنشاء مصنع بيانات باستخدام واجهة مستخدم مصنع البيانات Azure (UI). البنية الأساسية لمصنع البيانات هذا نسخ البيانات من تخزين Azure Blob إلى قاعدة بيانات في قاعدة بيانات azure SQL. ينطبق نمط التكوين في هذا البرنامج التعليمي على النسخ من مخزن بيانات يستند إلى ملف إلى مخزن بيانات يعتمد على العلاقات. للحصول على قائمة بمخازن البيانات المدعومة كمصادر ومتلقين، راجع جدول مخازن البيانات المدعومة.
إشعار
إذا كنت مستخدما جديدا ل Data Factory، فراجع مقدمة إلى Azure Data Factory.
في هذا البرنامج التعليمي، يمكنك تنفيذ الخطوات التالية:
- إنشاء data factory.
- كيفية إنشاء التدفق الأساسي من خلال نشاط النسخ.
- اختبار تشغيل التدفقات.
- تشغيل البنية الأساسية يدويًا.
- تشغيل البنية الأساسية وفقًا لجدول زمني.
- مراقبة تشغيل التدفق والنشاط.
المتطلبات الأساسية
- اشتراك Azure. إذا لم تكن مشتركًا في Azure، فيمكنك إنشاء حساب مجاني على Azure قبل البدء.
- حساب Azure Storage. يمكنك استخدام تخزين Blob كمخزن بيانات مصدر . إذا لم يكن لديك حساب تخزين، فشاهد إنشاء حساب تخزين Azure للحصول على خطوات لإنشاء حساب.
- Azure SQL Database. يمكنك استخدام قاعدة البيانات كمخزن بيانات متلقي . إذا لم يكن لديك قاعدة بيانات في قاعدة بيانات Azure SQL، فشاهد إنشاء قاعدة بيانات في قاعدة بيانات Azure SQL للحصول على خطوات لإنشاء قاعدة بيانات.
إنشاء كائن ثنائي كبير الحجم وجدول SQL
الآن، قم بإعداد مخزن الكائن الثنائي كبير الحجم وقاعدة بيانات SQL ضمن خطوات البرنامج التعليمي من خلال تنفيذ الخطوات التالية.
قم بإنشاء نقطة مصدر
قم بإطلاق Notepad. انسخ النص التالي، واحفظه كملف emp.txt على القرص:
FirstName,LastName John,Doe Jane,Doeإنشاء حاوية باسم adftutorial في تخزين Blob الخاص بك. إنشاء مجلد باسم الإدخال في هذه الحاوية. ثم قم بتحميل ملف emp.txt إلى مجلد الإدخال . استخدم مدخل Azure أو أدوات مثل Azure Storage Explorer للقيام بهذه المهام.
إنشاء جدولsink SQL
استخدم البرنامج النصي SQL التالي لإنشاء جدول dbo.emp في قاعدة البيانات الخاصة بك:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);السماح لخدمات Azure للوصول إلى خادم SQL. تأكد من تشغيل السماح بالوصول إلى خدمات Azure ل SQL Server بحيث يمكن ل Data Factory كتابة البيانات إلى SQL Server. للتحقق من هذا الإعداد ثم تشغيله، انتقل إلى خادم SQL المنطقي > نظرة عامة >تعيين جدار حماية الخادم> تعيين خيار السماح بالوصول إلى خدمات Azure إلى تشغيل.
إنشاء مصدرًا للبيانات
في هذه الخطوة، يمكنك إنشاء مصنع بيانات، وبدء تشغيل واجهة المستخدم Data Factory لإنشاء مسار لمصنع البيانات.
افتح Microsoft Edge أو Google Chrome. يتم حاليًّا دعم واجهة مستخدم Data Factory فقط في مستعرضي الويب Microsoft Edge وGoogle Chrome.
في القائمة اليسرى، حدد Create a resource>Integration>Data Factory.
في صفحة Create Data Factory، ضمن علامة التبويب Basics، حدد اشتراك Azure الذي تريد إنشاء مصنع البيانات فيه.
بالنسبة إلى مجموعة الموارد، نفِّذ إحدى الخطوات التالية:
أ. حدد مجموعة موارد موجودة من القائمة المنسدلة.
ب. حدد إنشاء جديد وأدخل اسم مجموعة الموارد الجديدة.
للتعرف على مجموعات الموارد، راجع استخدام مجموعات الموارد لإدارة موارد Azure التابعة لك.
ضمن Region، حدد موقعا لمصنع البيانات. لن تظهر القائمة المنسدلة إلا على المواقع المعتمدة فقط. يمكن أن تكون مخازن البيانات (على سبيل المثال، مخازن Azure وقاعدة بيانات SQL) ومراكز الحوسبة (على سبيل المثال، Azure HDInsight) المستخدمة في مصنع البيانات مستخدمة أيضًا في مناطق أخرى.
ضمن Name، أدخل ADFTutorialDataFactory.
يجب أن يكون اسم Azure data factory مميزاً عالمياً. إذا تلقيت رسالة خطأ حول قيمة الاسم، فأدخل اسماً مختلفاً لمصنع البيانات. (على سبيل المثال، yournameADFTutorialDataFactory). للحصول على قواعد التسمية للبيانات الاصطناعية على Data Factory، راجع قواعد تسمية Data Factory.
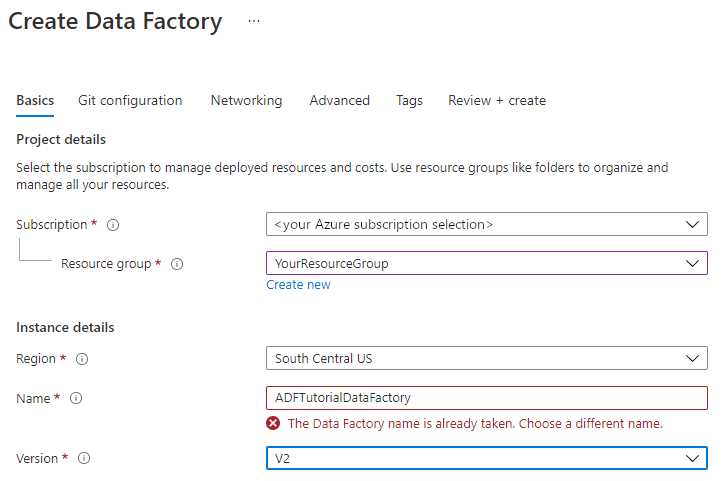
ضمن Version، حدد V2.
حدد علامة تبويب تكوين Git في الأعلى، وحدد خانة الاختيار تكوين Git لاحقا .
تحديد مراجعة + إنشاء، ثم حدد إنشاء بعد إتمام التحقق من الصحة.
بعد الانتهاء من الإنشاء، سترى الإعلام في مركز الإعلامات. حدد Go to resource للانتقال إلى صفحة Data factory.
حدد فتح في تجانب Open Azure Data Factory Studio لتشغيل واجهة مستخدم Azure Data Factory في علامة تبويب منفصلة.
إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية
في هذه الخطوة، يمكنك إنشاء التدفق الأساسية لنشاط النسخ في مصنع البيانات. نشاط النسخ ينسخ البيانات من مخزن البيانات الثنائية كبيرة الحجم إلى قاعدة بيانات SQL. في البرنامج التعليمي للتشغيل السريع، قمت بإنشاء مسار باتباع الخطوات التالية:
- إنشاء خدمة مرتبطة.
- إنشاء مجموعات بيانات إدخالات وإخراجات.
- إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية.
في هذا البرنامج التعليمي، يمكنك البدء بإنشاء البنية الأساسية. ثم تقوم بإنشاء الخدمات المرتبطة ومجموعات البيانات عندما تحتاج إليها لتكوين التدفق.
في الصفحة الرئيسية، حدد Orchestrate.
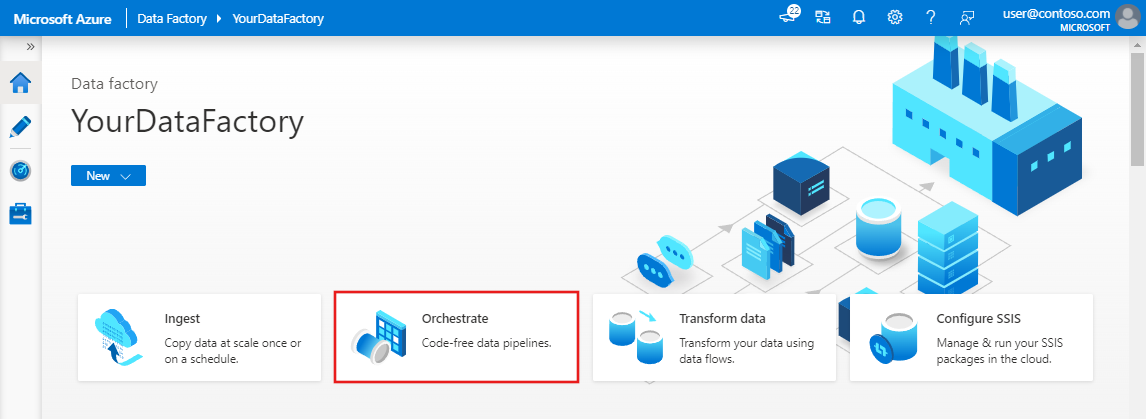
في اللوحة General ضمن Properties، حدد CopyPipeline للاسم. ثم قم بطي اللوحة بالنقر فوق رمز الخصائص في الزاوية العلوية اليمنى.
في مربع أداة الأنشطة، قم بتوسيع الفئة نقل وتحويل، واسحب نشاط Copy Data وأفلته من مربع الأداة إلى سطح مصمم المسار. حدد CopyFromBlobToSql للاسم.
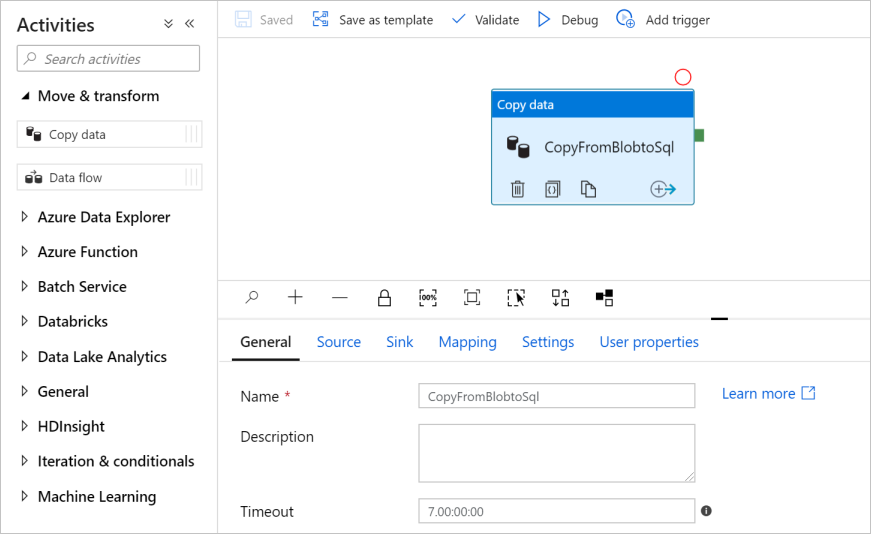
تكوين المصدر
تلميح
في هذا البرنامج التعليمي، يمكنك استخدام مفتاح الحساب كنوع مصادقة لمخزن بيانات المصدر، ولكن يمكنك اختيار أساليب المصادقة المدعومة الأخرى: SAS URI، وكيان الخدمة، والهوية المدارة إذا لزم الأمر. راجع الأقسام المقابلة فيthis article للحصول على التفاصيل. لتخزين أسرار مخازن البيانات بشكل آمن، يُوصى أيضًا باستخدام Azure Key Vault. راجعthis article للحصول على رسوم توضيحية مفصلة.
انتقل إلى علامة التبويب المصدر . حدد + جديد لإنشاء مجموعة بيانات مصدر.
في مربع الحوار New Dataset ، حدد Azure Blob Storage، ثم حدد Continue. البيانات المصدر في تخزين Blob، لذلك يمكنك تحديد Azure Blob Storage لمجموعة البيانات المصدر.
في مربع الحوار تحديد تنسيق ، اختر نوع تنسيق البيانات، ثم حدد متابعة.
في مربع الحوار تعيين خصائص ، أدخل SourceBlobDataset للاسم. حدد خانة الاختيار للصف الأول كعنوان. ضمن مربع النص Linked service ، حدد + New.
في مربع الحوار New Linked Service (Azure Blob Storage)، أدخِل AzureStorageLinkedService كاسم، وحدد حسابك على مساحة التخزين من قائمة الأسماء على Storage account. اختبار الاتصال، حدد إنشاء لنشر الخدمة المرتبطة.
بعد إنشاء الخدمة المرتبطة، يتم الانتقال مرة أخرى إلى صفحة تعيين الخصائص. بجوار File path، حدد Browse.
انتقل إلى مجلد adftutorial/input ، وحدد ملف emp.txt ، ثم حدد موافق.
حدد موافق. وسينتقل تلقائيًا إلى صفحة البنية الأساسية. في علامة التبويب المصدر ، تأكد من تحديد SourceBlobDataset . لمعاينة البيانات في هذه الصفحة، حدد معاينة البيانات.
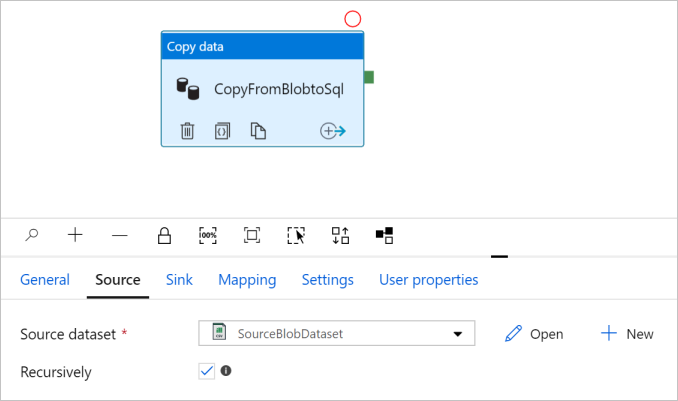
تكوين متلقٍّ
تلميح
في هذا البرنامج التعليمي، يمكنك استخدام مصادقة SQL كنوع مصادقة لمخزن بيانات المتلقي الخاص بك، ولكن يمكنك اختيار أساليب المصادقة المدعومة الأخرى: كيان الخدمة والهوية المدارة إذا لزم الأمر. راجع الأقسام المقابلة فيthis article للحصول على التفاصيل. لتخزين أسرار مخازن البيانات بشكل آمن، يُوصى أيضًا باستخدام Azure Key Vault. راجعthis article للحصول على رسوم توضيحية مفصلة.
انتقل إلى علامة التبويب Sink ، وحدد + New لإنشاء مجموعة بيانات المتلقي.
في مربع الحوار مجموعة بيانات جديدة، أدخل "SQL" في مربع البحث لتصفية الموصلات، وحدد قاعدة بيانات Azure SQL، ثم حدد متابعة. يمكنك في هذا البرنامج التعليمي، معرفة كيفية نسخ البيانات إلى قاعدة بيانات SQL.
في مربع الحوار تعيين خصائص ، أدخل OutputSqlDataset للاسم. من القائمة المنسدلة Linked service، حدد + New. يجب أن تكون مجموعة البيانات مقترنة بخدمة مرتبطة. الخدمة المرتبطة هي سلسلة الاتصال التي يستخدمها "مصنع البيانات" للاتصال بقاعدة بيانات SQL في وقت التشغيل. تحدد مجموعة البيانات الحاوية والمجلد والملف (اختياريًا) الذي يتم نسخ البيانات إليه.
في مربع الحوار خدمة مرتبطة جديدة (قاعدة بيانات Azure SQL)، اتبع الخطوات التالية:
أ. ضمن Name، أدخل AzureSqlDatabaseLinkedService.
ب. ضمن اسم الخادم، حدد مثيل SQL Server الخاص بك.
جـ. ضمن اسم قاعدة البيانات، حدد قاعدة البيانات الخاصة بك.
د. ضمن اسم المستخدم، أدخل اسم المستخدم.
هـ. ضمن كلمة المرور، أدخل كلمة المرور للمستخدم.
و. حدد اختبار الاتصال لاختبار الاتصال.
ز. حدد Create لنشر الخدمة المرتبطة.
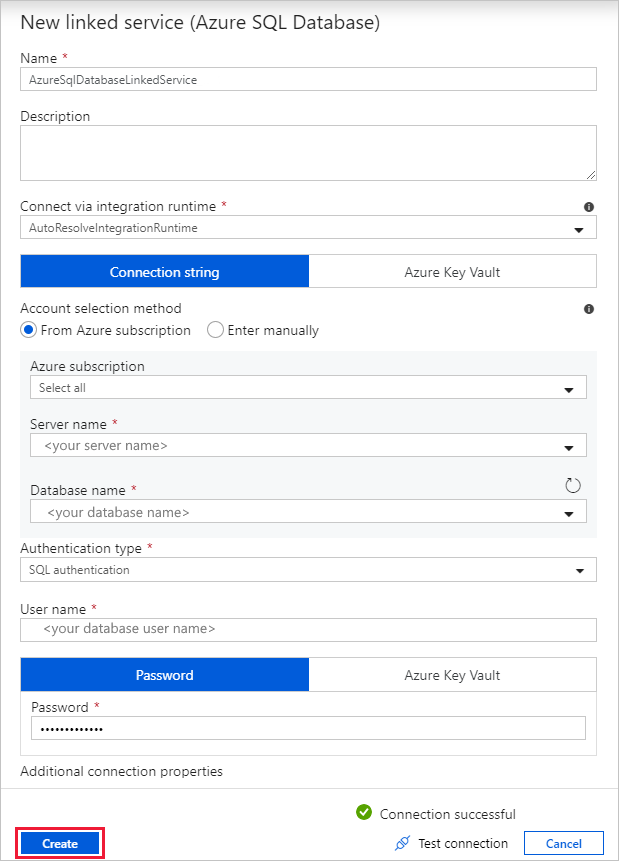
ينتقل تلقائيا إلى مربع الحوار تعيين خصائص . في الجدول، حدد [dbo].[ emp]. ثم حدد موافق.
انتقل إلى علامة التبويب مع البنية الأساسية لبرنامج ربط العمليات التجارية، وفي مجموعة بيانات المتلقي، تأكد من تحديد OutputSqlDataset .
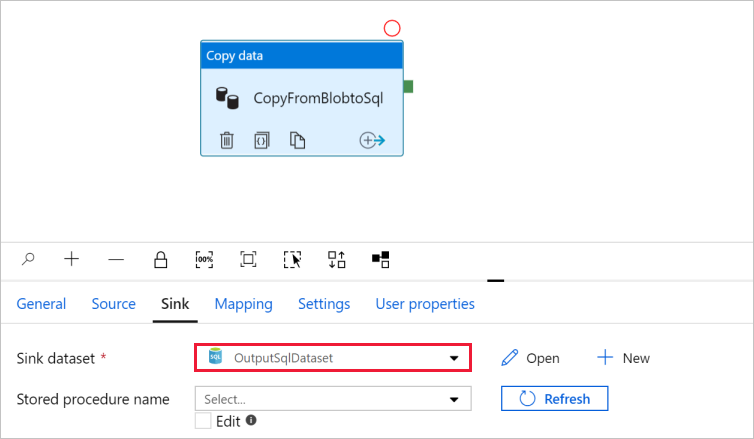
يمكنك اختياريا تعيين مخطط المصدر إلى مخطط الوجهة المقابل باتباع تعيين المخطط في نشاط النسخ.
التحقق من صحة خط الأنابيب
للتحقق من صحة البنية الأساسية لبرنامج ربط العمليات التجارية، حدد Validate من شريط الأدوات.
يمكنك مشاهدة التعليمات البرمجية JSON المقترنة بالبنية الأساسية لبرنامج ربط العمليات التجارية بالنقر فوق Code في أعلى اليمين.
تصحيح الأخطاء ونشرها
يمكنك تصحيح التدفقات قبل نشر البيانات الاصطناعية (الخدمات المرتبطة ومجموعات البيانات والتدفق) إلى "مصنع البيانات" أو مستودع "Azure Repos Git" الخاص بك.
لتصحيح أخطاء التدفقات، حدد Debug على شريط الأدوات. تشاهد حالة تشغيل التدفقات في علامة التبويب Output أسفل النافذة.
بمجرد تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية بنجاح، في شريط الأدوات العلوي، حدد Publish all. يؤدي هذا الإجراء إلى نشر الكيانات (مجموعات البيانات ومسارات المعالجة) التي قمت بإنشائها من أجل Data Factory.
انتظر حتى ترى رسالة تم النشر بنجاح. للاطلاع على رسائل الإشعارات، انقر على إظهار الإشعارات في أعلى اليمين (زر جرس).
تشغيل التدفق يدويًا
في هذه الخطوة، يمكنك تشغيل خط الأنابيب الذي قمت بنشره في الخطوة السابقة يدويًا.
حدد Trigger على شريط الأدوات، ثم حدد Trigger Now. في صفحة Pipeline Run، حدد OK.
انتقل إلى علامة التبويب Monitor على اليسار. ترى تشغيل البنية الأساسية الذي يتم تشغيله بواسطة مشغل يدوي. يمكنك استخدام الارتباطات ضمن العمود PIPELINE NAME لعرض تفاصيل النشاط وإعادة تشغيل "تدفقات".

لمشاهدة عمليات تشغيل النشاط المقترنة بتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية، حدد الارتباط CopyPipeline ضمن عمود PIPELINE NAME . لا يوجد في هذا المثال سوى نشاط واحد، لذلك لن ترى سوى إدخال واحد في القائمة. للحصول على تفاصيل حول عملية النسخ، حدد ارتباط التفاصيل (أيقونة النظارات) ضمن العمود اسم النشاط. حدد جميع "تدفقات" قيد التشغيل في الأعلى للعودة إلى طريقة عرض "تشغيل خطوط الأنابيب". لإعادة تنشيط طريقة العرض، حدد Refresh.

تحقق من إضافة صفين إضافيين إلى جدول emp في قاعدة البيانات.

تشغيل التدفق وفقًا لجدول زمني
في هذا الجدول الزمني، يمكنك إنشاء مشغل جدول للبنية الأساسية. يعمل المشغل على تشغيل البنية الأساسية وفق الجدول الزمني المحدد، مثل كل ساعة أو يوميًا. هنا تقوم بتعيين المشغل للتشغيل كل دقيقة حتى تاريخ الانتهاء المُحدد.
انتقل إلى علامة التبويب Author على اليسار أعلى علامة تبويب جهاز العرض.
انتقل إلى البنية الأساسية لبرنامج ربط العمليات التجارية، وانقر فوق مشغل على شريط الأدوات، وحدد جديد/تحرير.
في مربع الحوار إضافة مشغلات ، حدد + جديد لاختيار منطقة المشغل .
في نافذة New Trigger ، اتبع الخطوات التالية:
أ. ضمن Name، أدخل RunEveryMinute.
ب. تحديث تاريخ البدء للمشغل. إذا كان التاريخ سابقًا للتاريخ الحالي، فسيبدأ المشغل في النفاذ بمجرد نشر التغيير.
جـ. ضمن المنطقة الزمنية، حدد القائمة المنسدلة.
د. تعيين التكرار إلى كل دقيقة (دقائق) واحدة.
هـ. حدد خانة الاختيار تحديد تاريخ انتهاء، وقم بتحديث جزء End On ليكون بعد التاريخ الحالي بدقائق قليلة. يتم تنشيط المشغل فقط بعد نشر التغييرات. إذا قمت بتعيينه إلى بضع دقائق فقط عن بعضها البعض، وكنت لا تنشر ذلك بحلول ذلك الوقت، فأنت لا ترى تشغيل المشغل.
و. بالنسبة إلى الخيار المنشط ، حدد نعم.
ز. حدد موافق.
هام
تقترن التكلفة بكل تشغيل للبنية الأساسية، لذا قم بتعيين تاريخ الانتهاء بشكل مناسب.
في صفحة تحرير المشغل ، راجع التحذير، ثم حدد حفظ. لا تأخذ البنية الأساسية في هذا المثال أي معلمات.
انقر فوق نشر الكل لنشر التغيير.
انتقل إلى علامة التبويب Monitor على اليسار لمشاهدة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية المشغلة.

للتبديل من طريقة عرض Pipeline Runs إلى طريقة عرض Trigger Runs ، حدد Trigger Runs على الجانب الأيمن من النافذة.
ترى المشغل يعمل في قائمة.
تحقق من إدراج صفين في الدقيقة (لكل تشغيل مسار) في جدول emp حتى وقت الانتهاء المحدد.
المحتوى ذو الصلة
يقوم التدفق الموجود في هذه العينة بنسخ البيانات من موقع إلى آخر في مخزن الكائنات الثنائية كبيرة الحجم. لقد تعرفت على كيفية:
- إنشاء data factory.
- كيفية إنشاء التدفق الأساسي من خلال نشاط النسخ.
- اختبار تشغيل التدفقات.
- تشغيل البنية الأساسية يدويًا.
- تشغيل البنية الأساسية وفقًا لجدول زمني.
- مراقبة تشغيل التدفق والنشاط.
تقدم إلى البرنامج التعليمي التالي لمعرفة كيفية نسخ البيانات من الموقع إلى السحابة:
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ