ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
يمكنك في هذا التشغيل السريع استخدام مدخل Azure لإنشاء مصنع بيانات. بعد ذلك، يمكنك استخدام أداة Copy Data لإنشاء خط تدفقات يقوم بنسخ الملفات الجديدة بشكل متزايد استناداً على اسم الملف المقسم زمنياً من تخزين Azure Blob إلى تخزين Azure Blob.
إشعار
إذا كنت جديداً في استخدام Azure Data Factory، فراجع مقدمة لـ Azure Data Factory.
في هذا البرنامج التعليمي، يمكنك تنفيذ الخطوات التالية:
- إنشاء data factory.
- استخدام أداة Copy Data لإنشاء مسار.
- مراقبة تشغيل التدفق والنشاط.
المتطلبات الأساسية
- اشتراك Azure: إذا لم يكن لديك اشتراك Azure، فأنشئ حسابمجاني قبل أن تبدأ.
- حساب تخزين Azure: استخدم تخزين Blob كمخزن بيانات المصدر والمتلقي. إذا لم يكن لديك حساب تخزين Azure، فراجع الإرشادات الواردة في إنشاء حساب تخزين.
إنشاء حاويتين في تخزين Blob
إعداد تخزين Blob للبرنامج التعليمي من خلال تنفيذ هذه الخطوات.
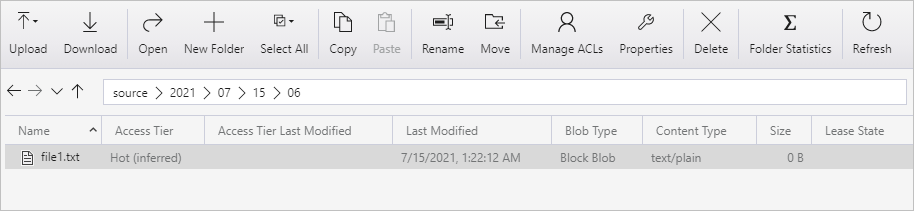
إنشاء حاوية باسم source. إنشاء مسار مجلد كـ 2021/07/15/06 في الحاوية. إنشاء ملف نصي فارغ وتسميته بـ file1.txt. تحميل file1.txt إلى مسار المجلد source/2021/07/15/06 في حساب التخزين الخاص بك. يمكنك استخدام أدوات مختلفة لتنفيذ هذه المهام، مثل Azure Storage Explorer.
إشعار
يرجى ضبط اسم المجلد مع توقيت UTC الخاص بك. على سبيل المثال، إذا كان توقيت UTC الحالي هو 6:10 صباحاً في 15 يوليو 2021، يمكنك إنشاء مسار المجلد source/2021/07/15/06/ حسب القاعدة source/{السنة}/{الشهر}/{اليوم}/{الساعة}/.
أنشئ حاوية باسم destination. يمكنك استخدام أدوات مختلفة لتنفيذ هذه المهام، مثل Azure Storage Explorer.
إنشاء مصدرًا للبيانات
في القائمة العلوية، حدد Create a resource>Analytics>Data Factory :
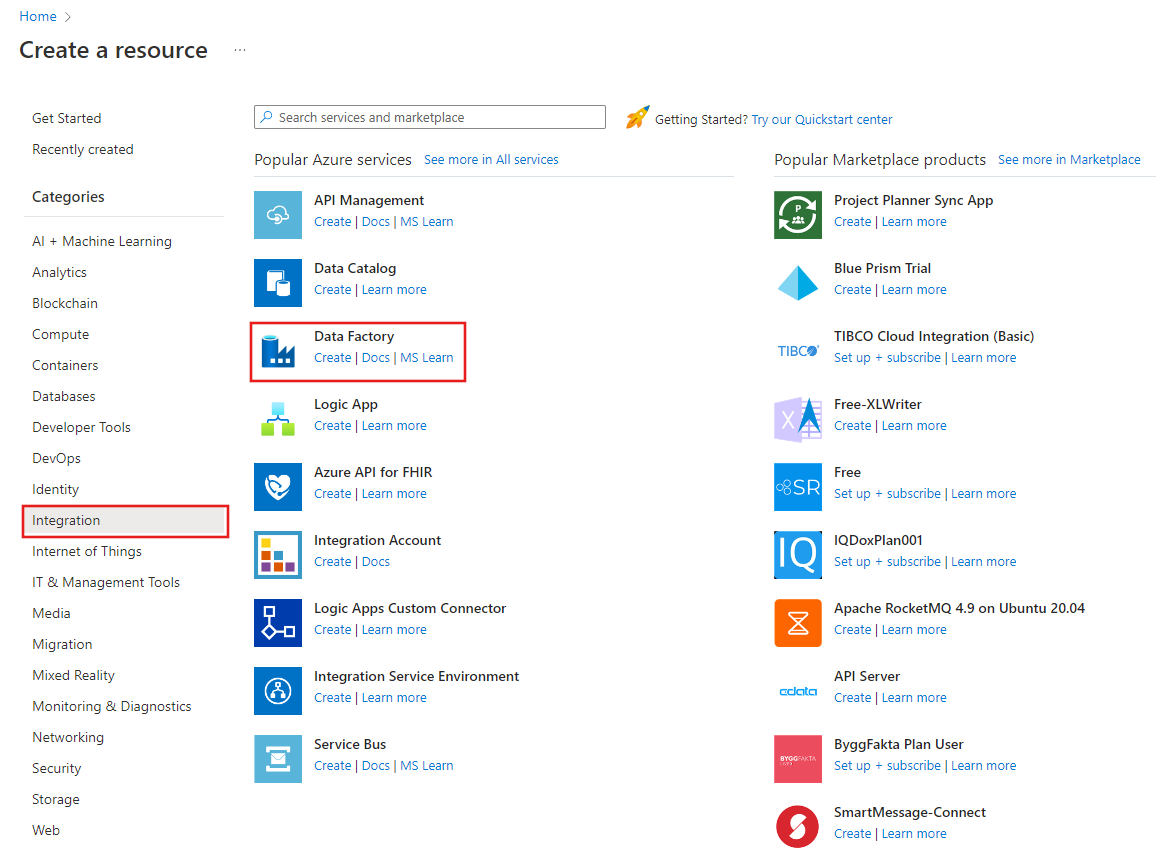
في صفحة New data factory، أدخِل ADFTutorialDataFactory في خانة Name.
يجب أن يكون اسم مصنع البيانات الخاص بك فريداً عالمياً. قد تتلقى رسالة الخطأ التالية:
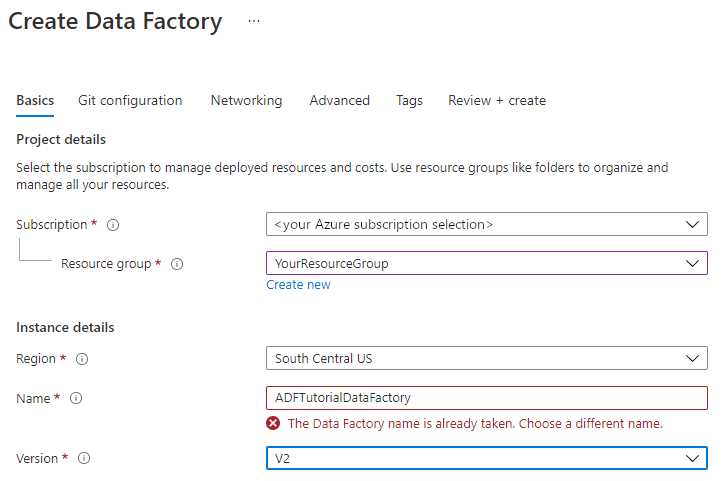
إذا تلقيت رسالة خطأ حول قيمة الاسم، فأدخل اسماً مختلفاً لمصنع البيانات. على سبيل المثال، استخدم الاسم yournameADFTutorialDataFactory. للحصول على قواعد التسمية لData Factory artifacts، راجع قواعد تسمية مصنع البيانات.
حدد اشتراك Azure لإنشاء مصنع بيانات جديد.
بالنسبة إلى مجموعة الموارد، نفِّذ إحدى الخطوات التالية:
أ. حدد Use existing واختر مجموعة موارد موجودة من القائمة المنسدلة.
ب. حدد Create new وأدخل اسم مجموعة الموارد.
للتعرف على مجموعات الموارد، راجع استخدام مجموعات الموارد لإدارة موارد Azure التابعة لك.
ضمن الإصدار، حدد V2 للإصدار.
ضمن location، حدد موقع مصنع البيانات. يتم عرض المواقع المعتمدة فقط في القائمة المنسدلة. يمكن أن تكون مخازن البيانات (على سبيل المثال،Azure Storage وSQL Database) والحسابات (على سبيل المثال، Azure HDInsight) التي يستخدمها مصنع البيانات الخاص بك في مواقع ومناطق أخرى.
حدد إنشاء.
بعد الانتهاء من الإنشاء، يتم عرض الصفحة الرئيسية لData Factory.
لبدء تشغيل واجهة مستخدم مصنع بيانات Azure (UI) في علامة تبويب منفصلة، حدد Open على الإطار المتجانب لـOpen Azure Data Factory Studio.

استخدام أداة Copy Data لإنشاء مسار
في صفحة Azure Data Factory الرئيسية، حدد العنوان "Ingest" لبدء تشغيل أداة Copy Data.
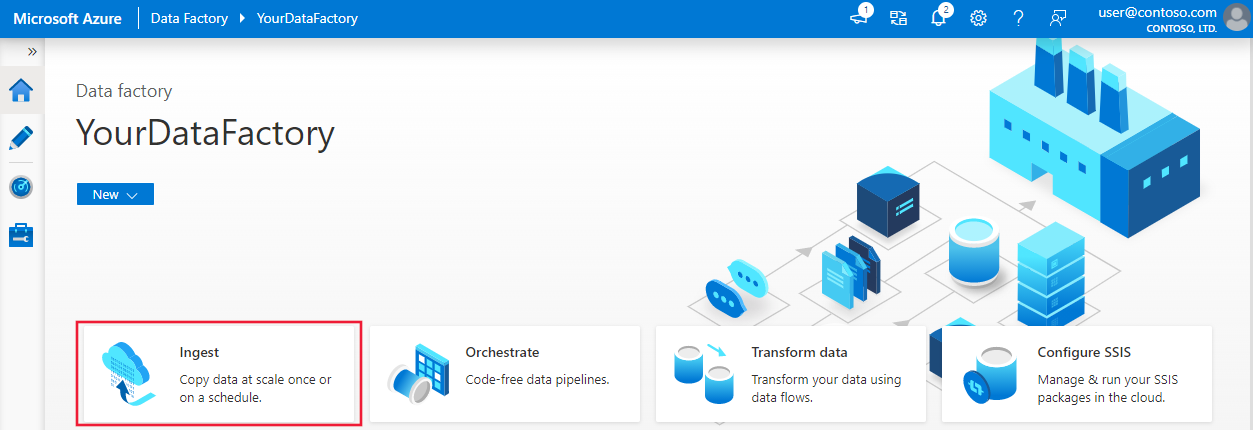
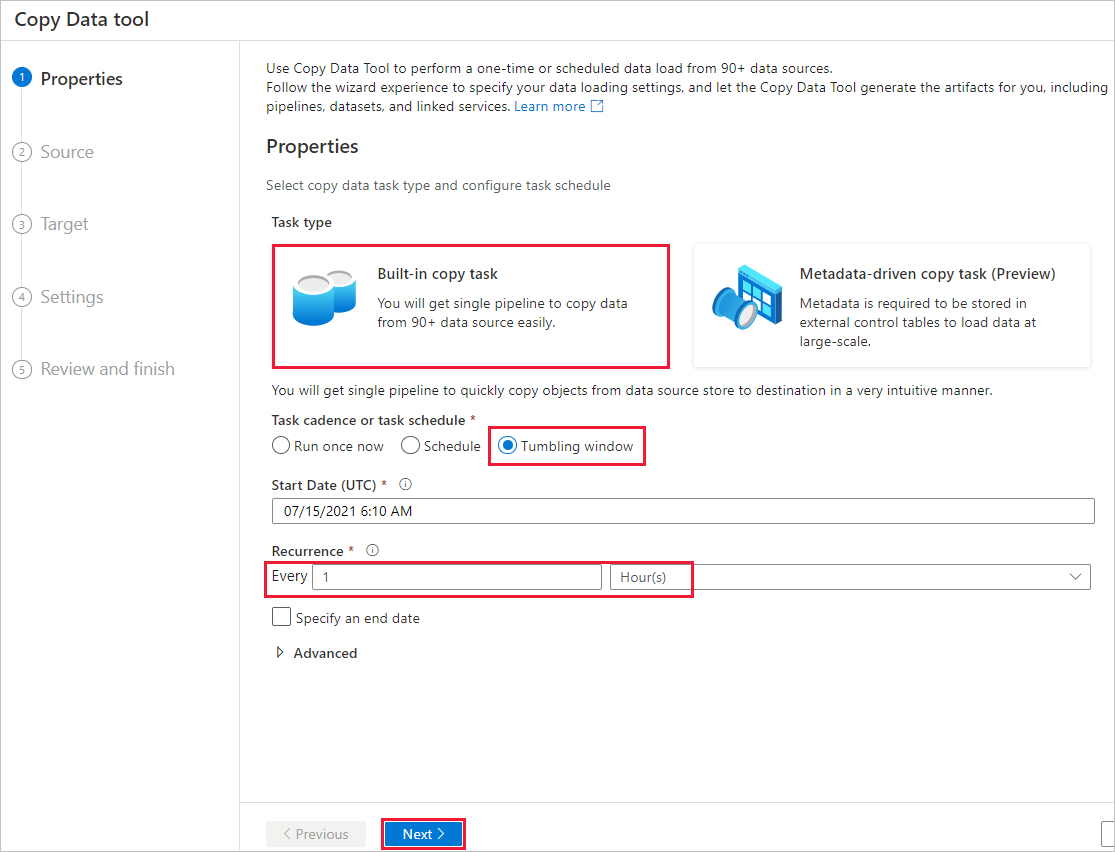
في صفحة "Properties"، اتبع الخطوات التالية:
ضمن "Task type"، حدد "Built-in copy task".
ضمن إيقاع المهمة أو جدول المهام، حدد نافذة Tumbling.
ضمن "Recurrence"، أدخل 1 Hour(s).
حدد التالي.
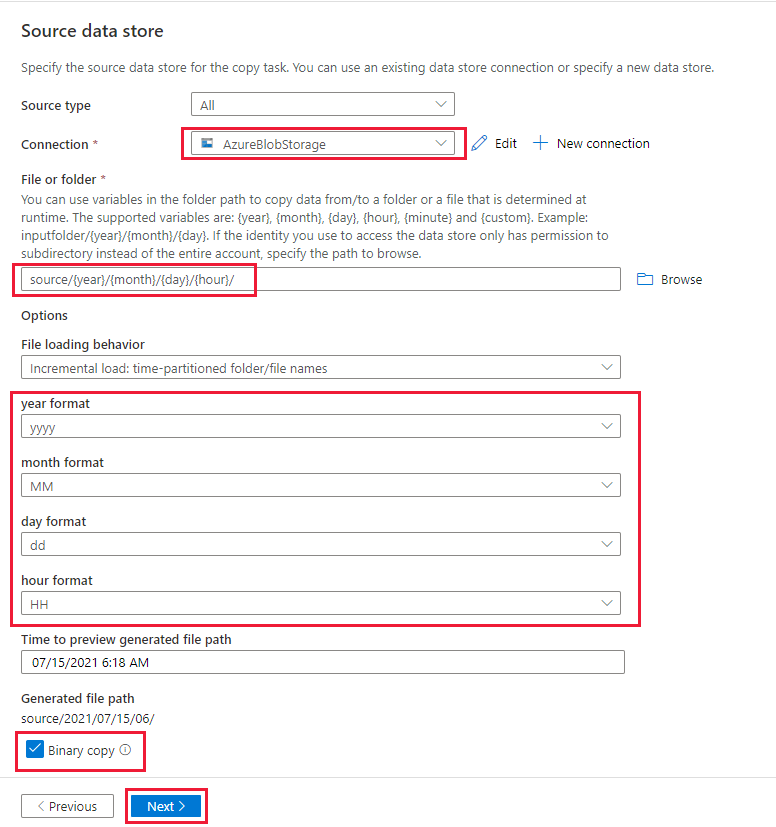
في صفحة Source data store، أكمل الخطوات التالية:
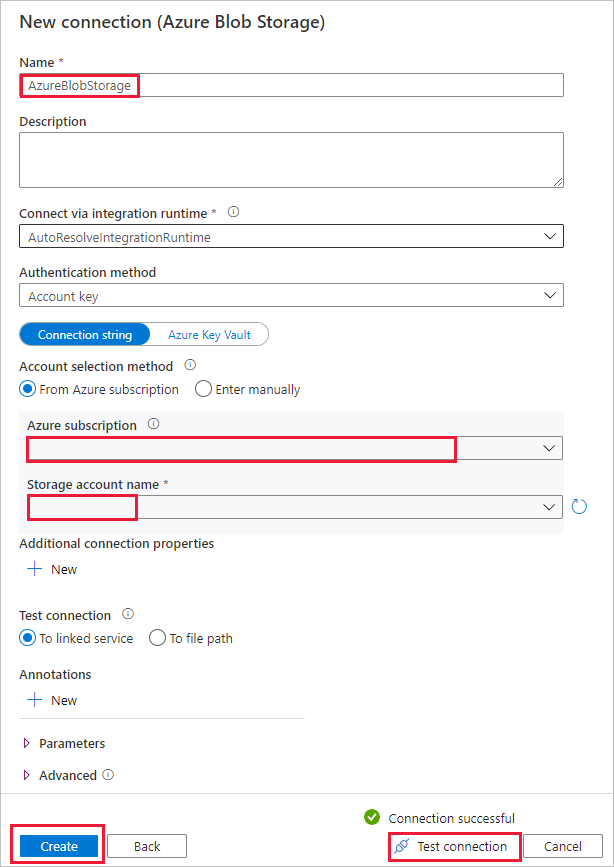
أ. حدد + New connection لإضافة اتصال.
ب. حدد Azure Blob Storage من المعرض، ثم حدد Continue.
جـ. في صفحة "New connection (Azure Blob Storage)"، حدد اسماً للاتصال. حدد اشتراك Azure، وحدد حساب التخزين الخاص بك من قائمة "Storage account name". اختبر الاتصال ثم حدد إنشاء.
د. في صفحة "Source data store"، حدد الاتصال الذي أُنشيء حديثاً في القسم "Connection".
هـ. في قسم File أو folder، استعرض وحدد الحاوية المصدر، ثم حدد "OK".
و. ضمن "File loading behavior"، حدد "Incremental load": أسماء المجلدات/الملفات المقسمة زمنياً.
ز. اكتب مسار المجلد الديناميكي source/{السنة}/{الشهر}/{اليوم}/{الساعة}/، وغيّر التنسيق كما هو موضح في لقطة الشاشة التالية.
ح. تحقق من النسخ الثنائي وحدد "Next".
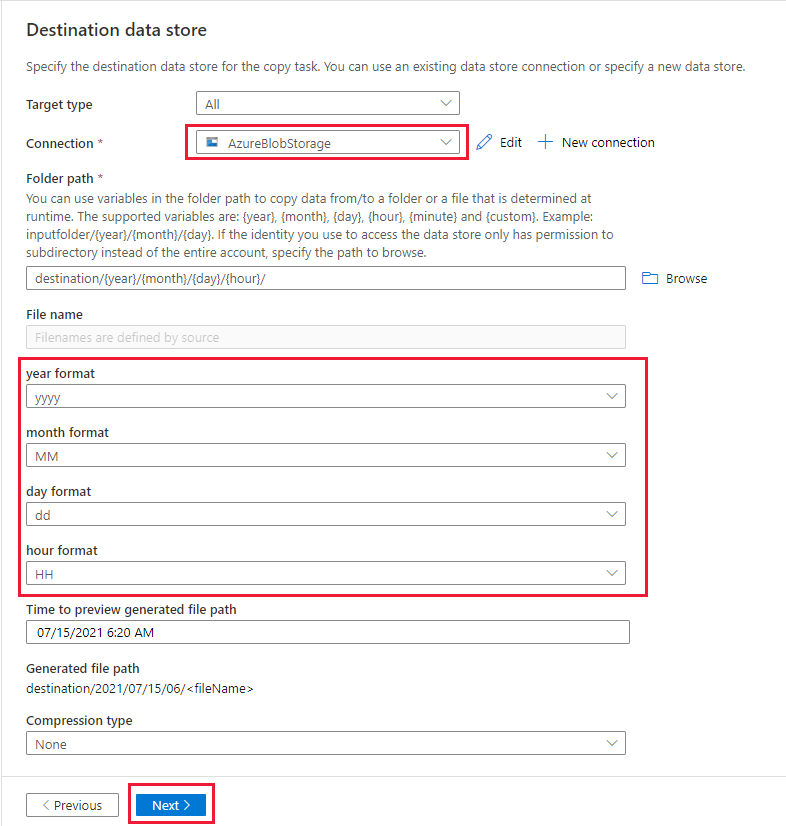
في صفحة Destination data store، أكمل الخطوات التالية:
حدد "AzureBlobStorage"، وهو نفس حساب التخزين كمخزن مصدر البيانات.
استعرض وحدد المجلد الوجهة، ثم حدد "OK".
اكتب مسار المجلد الديناميكي destination/{السنة}/{الشهر}/{اليوم}/{الساعة}/، وغيّر التنسيق كما هو موضح في لقطة الشاشة التالية.
حدد التالي.
في صفحة "Settings"، ضمن "Task name"، أدخل DeltaCopyFromBlobPipeline، ثم حدد "Next". تنشئ واجهة مستخدم Data Factory خط تدفقات باسم المهمة المحدد.
في صفحة الملخص، راجع الإعدادات، ثم حدد Next.
في صفحة Deployment، حدد Monitor لمراقبة المسار الذي أنشأته (مهمة).
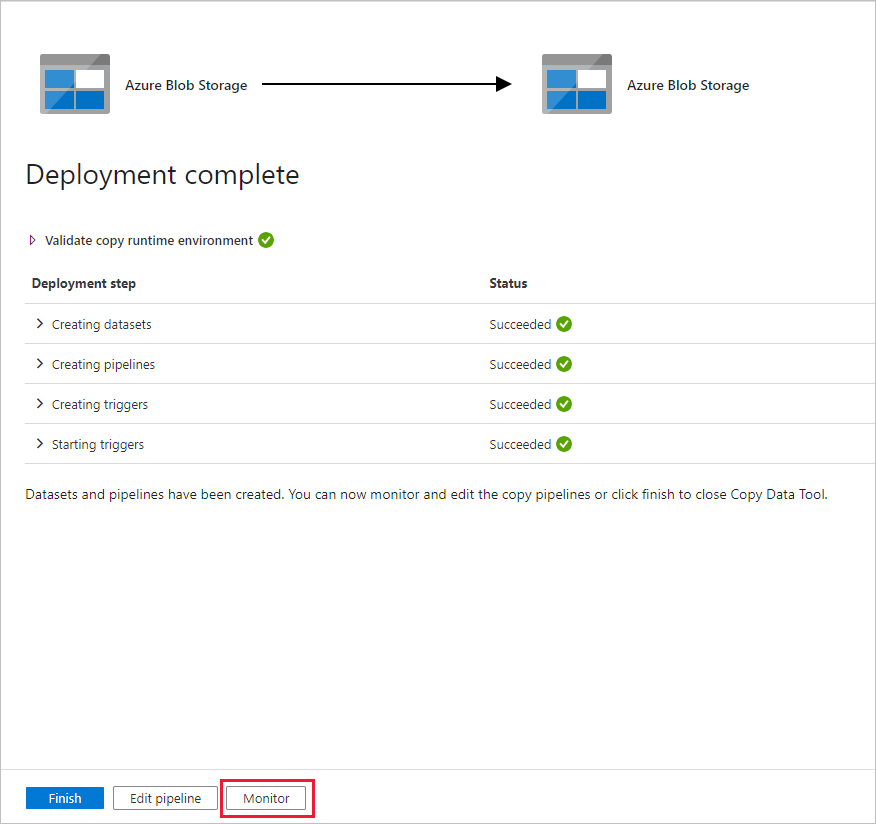
لاحظ أن علامة التبويب Monitor على اليسار محددة تلقائياً. تحتاج إلى الانتظار لتشغيل خط التدفقات عند تشغيله تلقائياً (بعد ساعة واحدة تقريباً). عند تشغيله، حدد ارتباط اسم خط التدفقات DeltaCopyFromBlobPipeline لعرض تفاصيل تشغيل النشاط أو إعادة تشغيل خط التدفقات. حدد "Refresh" لتحديث القائمة.
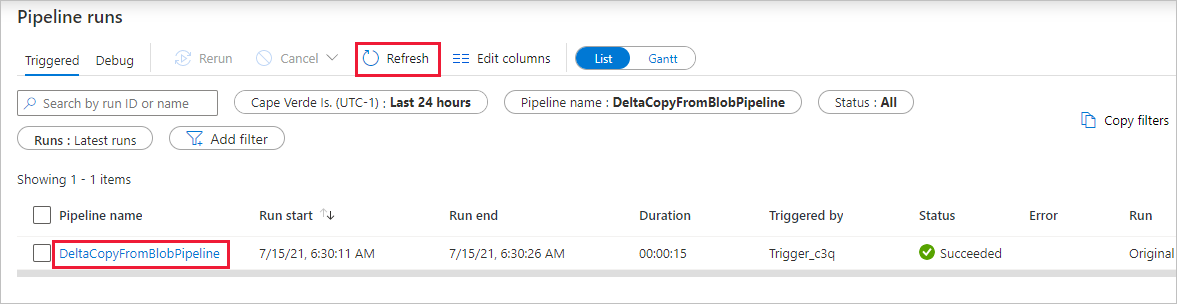
هناك نشاط واحد فقط (نشاط النسخ) في خط التدفقات، بحيث ترى إدخالاً واحداً فقط. اضبط عرض العمود للأعمدة Source وDestination (إذا لزم الأمر) لعرض مزيد من التفاصيل، يمكنك مشاهدة ملف المصدر (file1.txt) وقد تم نسخه من source/2021/07/15/06/ إلى destination/2021/07/15/06/ مع نفس اسم الملف.
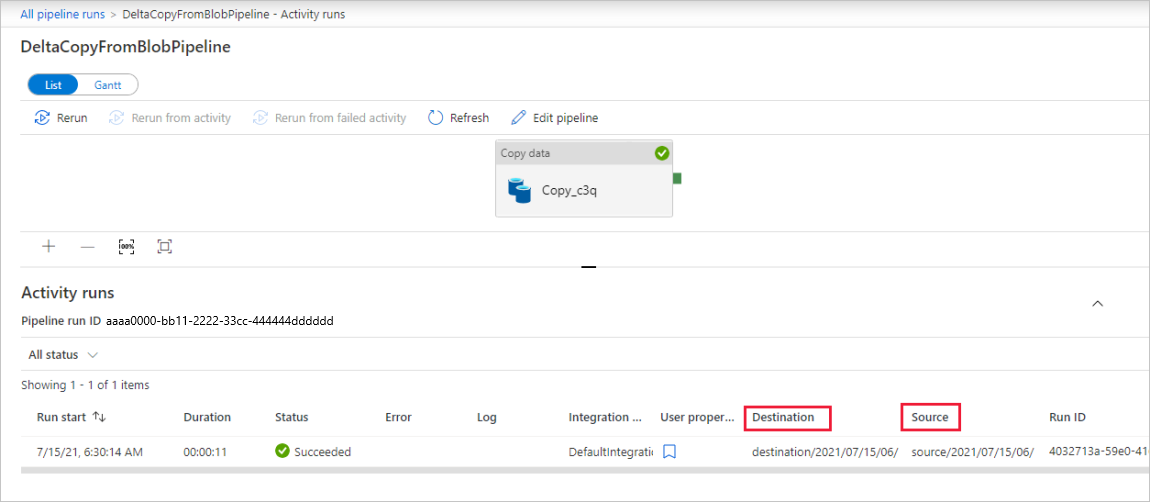
يمكنك أيضاً التحقق من ذلك باستخدام Azure Storage Explorer (https://storageexplorer.com/) لفحص الملفات.
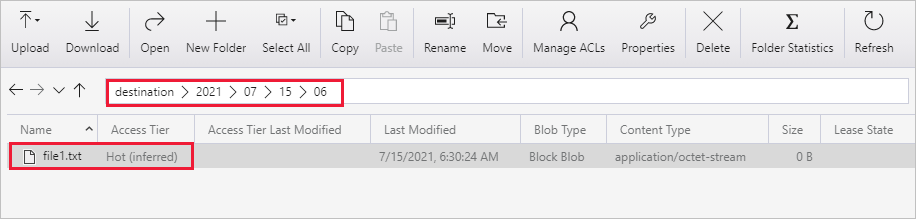
إنشاء ملف نصي فارغ آخر بالاسم الجديد file2.txt. تحميل الملف file2.txt إلى مسار المجلد source/2021/07/15/07 في حساب التخزين الخاص بك. يمكنك استخدام أدوات مختلفة لتنفيذ هذه المهام، مثل Azure Storage Explorer.
إشعار
قد تكون على دراية بضرورة إنشاء مسار مجلد جديد. يرجى ضبط اسم المجلد مع توقيت UTC الخاص بك. على سبيل المثال، إذا كان توقيت UTC الحالي 7:30 صباحاً. في 15 يوليو 2021، يمكنك إنشاء مسار المجلد source/2021/07/15/07/ حسب القاعدة {السنة}/{الشهر}/{اليوم}/{الساعة}/.
للعودة إلى طريقة عرض تشغيل خطوط التدفقات، حدد "All pipelines runs"، وانتظر تشغيل نفس خط التدفقات مرة أخرى تلقائياً بعد ساعة واحدة.
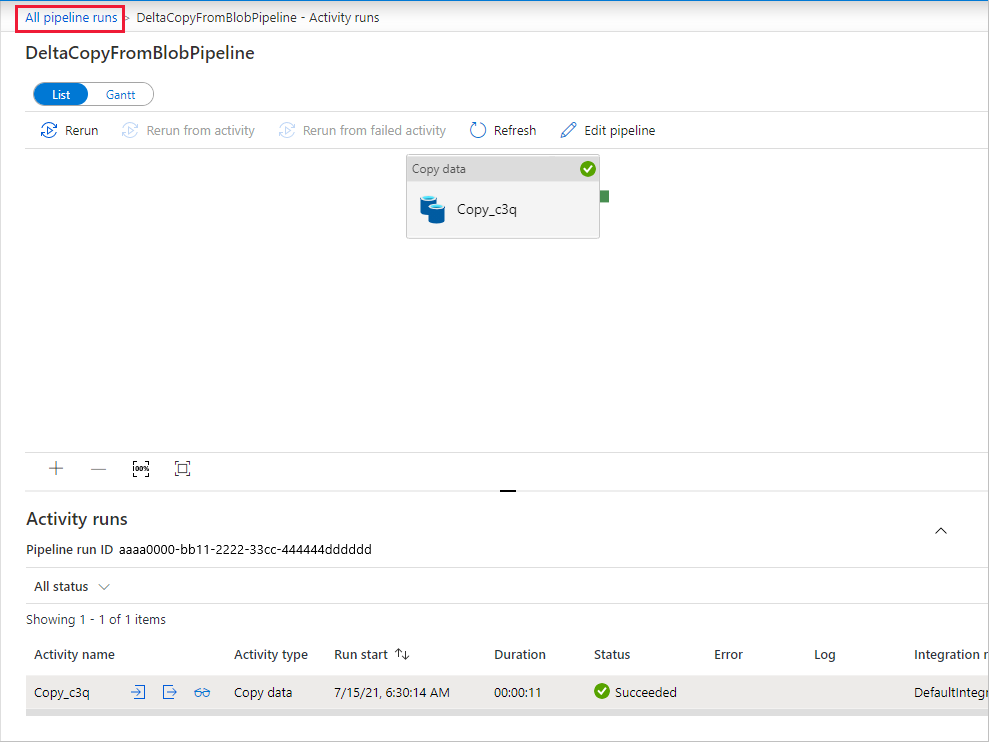
حدد ارتباط DeltaCopyFromBlobPipeline الجديد لتشغيل خط التدفقات الثاني عندما يأتي، وافعل الشيء نفسه لمراجعة التفاصيل. سترى الملف المصدر (file2.txt) تم نسخه من source/2021/07/15/07/ إلى destination/2021/07/15/07/ بنفس اسم الملف. يمكنك أيضاً التحقق من ذلك باستخدام Azure Storage Explorer (https://storageexplorer.com/) لفحص الملفات في الحاوية الواجهة.
المحتوى ذو الصلة
انتقل إلى البرنامج التعليمي التالي لمعرفة المزيد حول تحويل البيانات باستخدام مجموعة Spark على Azure: