إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يرشدك هذا البرنامج التعليمي من خلال إعداد ملحق Databricks ل Visual Studio Code، ثم تشغيل Python على مجموعة Azure Databricks وكوظيفة Azure Databricks في مساحة العمل البعيدة. راجع ما هو ملحق Databricks ل Visual Studio Code؟.
المتطلبات
يتطلب هذا البرنامج التعليمي ما يلي:
- لقد قمت بتثبيت ملحق Databricks ل Visual Studio Code. راجع تثبيت ملحق Databricks ل Visual Studio Code.
- لديك مجموعة Azure Databricks بعيدة لاستخدامها. دون اسم نظام المجموعة. لعرض المجموعات المتوفرة، في الشريط الجانبي لمساحة عمل Azure Databricks، انقر فوق حساب. راجع الحساب.
الخطوة 1: إنشاء مشروع Databricks جديد
في هذه الخطوة، يمكنك إنشاء مشروع Databricks جديد وتكوين الاتصال بمساحة عمل Azure Databricks البعيدة.
- قم بتشغيل Visual Studio Code، ثم انقر فوق File > Open Folder وافتح بعض المجلدات الفارغة على جهاز التطوير المحلي.
- على الشريط الجانبي، انقر فوق أيقونة شعار Databricks . يؤدي هذا إلى فتح ملحق Databricks.
- في طريقة عرض التكوين ، انقر فوق ترحيل إلى مشروع Databricks.
- يتم فتح لوحة الأوامر لتكوين مساحة عمل Databricks. بالنسبة إلى Databricks Host، أدخل عنوان URL لكل مساحة عمل أو حدده، على سبيل المثال
https://adb-1234567890123456.7.azuredatabricks.net. - حدد ملف تعريف مصادقة للمشروع. راجع إعداد المصادقة لملحق Databricks ل Visual Studio Code.
الخطوة 2: إضافة معلومات نظام المجموعة إلى ملحق Databricks وبدء المجموعة
مع فتح طريقة عرض التكوين بالفعل، انقر فوق تحديد نظام مجموعة أو انقر فوق أيقونة الترس (تكوين نظام المجموعة).
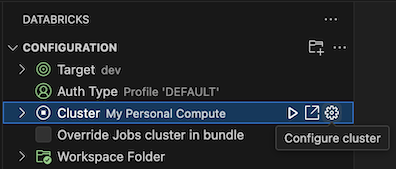
في لوحة الأوامر، حدد اسم نظام المجموعة الذي قمت بإنشائه مسبقا.
انقر فوق أيقونة التشغيل (بدء نظام المجموعة) إذا لم تكن قد بدأت بالفعل.
الخطوة 3: إنشاء التعليمات البرمجية ل Python وتشغيلها
إنشاء ملف تعليمة برمجية Python محلي: على الشريط الجانبي، انقر فوق أيقونة المجلد (المستكشف).
في القائمة الرئيسية، انقر فوق ملف > جديد. قم بتسمية الملف demo.py واحفظه في جذر المشروع.
أضف التعليمات البرمجية التالية إلى الملف ثم احفظه. تنشئ هذه التعليمة البرمجية محتويات إطار بيانات PySpark الأساسي وتعرضها:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show() # Output: # # +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+انقر فوق أيقونة Run on Databricks بجوار قائمة علامات تبويب المحرر، ثم انقر فوق Upload and Run File. يظهر الإخراج في طريقة عرض وحدة تحكم تتبع الأخطاء.
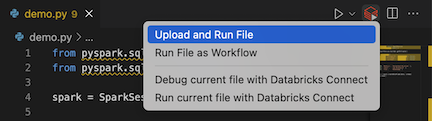
بدلا من ذلك، في طريقة عرض المستكشف، انقر بزر الماوس الأيمن
demo.pyفوق الملف، ثم انقر فوق تشغيل على Databricks>Upload and Run File.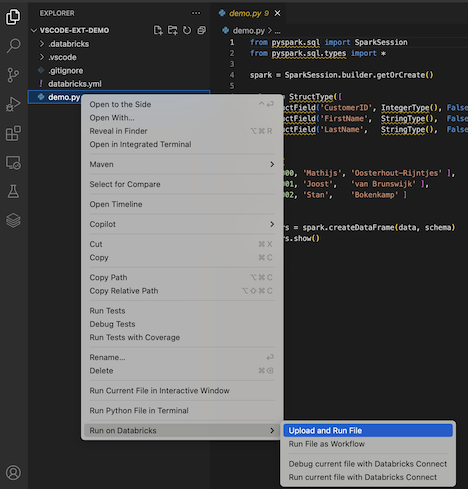
الخطوة 4: تشغيل التعليمات البرمجية كوظيفة
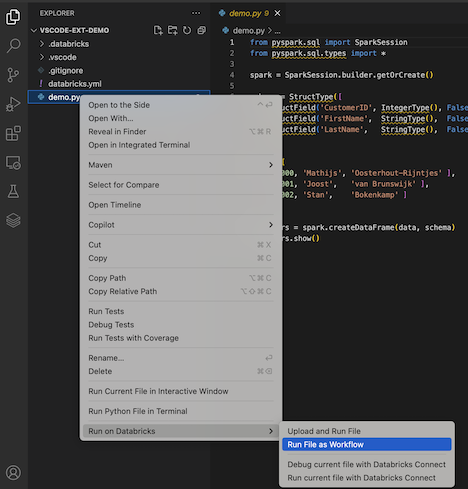
للتشغيل demo.py كوظيفة، انقر فوق الأيقونة تشغيل على Databricks بجوار قائمة علامات تبويب المحرر، ثم انقر فوق تشغيل ملف كسير عمل. يظهر الإخراج في علامة تبويب محرر منفصلة بجوار محرر الملفات demo.py .
![]()
بدلا من ذلك، انقر بزر الماوس الأيمن demo.py فوق الملف في لوحة Explorer، ثم حدد Run on Databricks>Run File as Workflow.
الخطوات التالية
الآن بعد أن استخدمت ملحق Databricks ل Visual Studio Code بنجاح لتحميل ملف Python محلي وتشغيله عن بعد، يمكنك أيضا:
- استكشف موارد Databricks Asset Bundles والمتغيرات باستخدام واجهة مستخدم الملحق. راجع ميزات ملحق Databricks Asset Bundles.
- قم بتشغيل أو تصحيح تعليمات Python البرمجية باستخدام Databricks Connect. راجع تصحيح التعليمات البرمجية باستخدام Databricks Connect لملحق Databricks ل Visual Studio Code.
- تشغيل ملف أو دفتر ملاحظات كوظيفة Azure Databricks. راجع تشغيل ملف على نظام مجموعة أو ملف أو دفتر ملاحظات كمهمة في Azure Databricks باستخدام ملحق Databricks ل Visual Studio Code.
- قم بإجراء الاختبارات باستخدام
pytest. راجع تشغيل الاختبارات باستخدام pytest باستخدام ملحق Databricks ل Visual Studio Code.