إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يحتوي Azure Databricks على العديد من الأدوات المساعدة وواجهات برمجة التطبيقات للتفاعل مع الملفات في المواقع التالية:
- وحدات تخزين كتالوج Unity
- ملفات مساحة العمل
- تخزين كائن سحابي
- تركيبات DBFS وجذر DBFS
- التخزين المؤقت المرفق بعقدة برنامج التشغيل للمجموعة
تحتوي هذه المقالة على أمثلة للتفاعل مع الملفات في هذه المواقع للأدوات التالية:
- Apache Spark
- Spark SQL وDatabricks SQL
- أدوات نظام ملفات Databricks (
dbutils.fsأو%fs) - Databricks CLI
- Databricks REST API
- أوامر Bash shell (
%sh) - تثبيتات المكتبة ذات نطاق دفتر الملاحظات باستخدام
%pip - pandas
- أدوات إدارة ملفات OSS Python ومعالجتها
هام
لا يمكن لعمليات الملفات التي تتطلب الوصول إلى بيانات FUSE الوصول مباشرة إلى تخزين الكائنات السحابية باستخدام URIs. توصي Databricks باستخدام وحدات تخزين كتالوج Unity لتكوين الوصول إلى هذه المواقع ل FUSE.
يدعم Scala FUSE لوحدات تخزين كتالوج Unity وملفات مساحة العمل على الحوسبة المكونة باستخدام كتالوج Unity ووضع الوصول المشترك. في الحساب الذي تم تكوينه باستخدام وضع وصول مستخدم واحد وDatabricks Runtime 14.3 وما فوق، يدعم Scala FUSE لوحدات تخزين كتالوج Unity وملفات مساحة العمل، باستثناء العمليات الفرعية التي تنشأ من Scala، مثل الأمر "cat /Volumes/path/to/file".!!Scala .
هل أحتاج إلى توفير مخطط URI للوصول إلى البيانات؟
تتبع مسارات الوصول إلى البيانات في Azure Databricks أحد المعايير التالية:
تتضمن مسارات نمط URI مخطط URI. بالنسبة لحلول الوصول إلى البيانات الأصلية في Databricks، تعد أنظمة URI اختيارية لمعظم حالات الاستخدام. عند الوصول مباشرة إلى البيانات في تخزين كائن السحابة، يجب توفير نظام URI الصحيح لنوع التخزين.
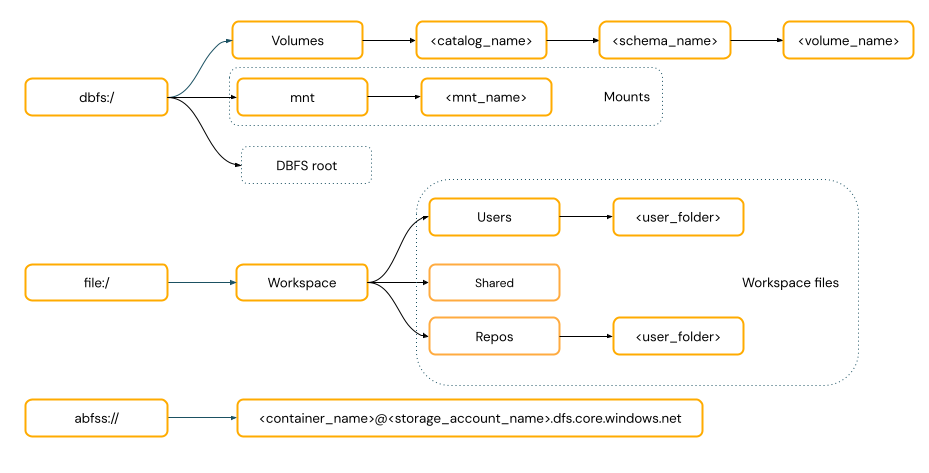
توفر مسارات نمط POSIX الوصول إلى البيانات بالنسبة لجذر برنامج التشغيل (
/). لا تتطلب مسارات نمط POSIX مخططا أبدا. يمكنك استخدام وحدات تخزين كتالوج Unity أو عمليات تحميل DBFS لتوفير الوصول على غرار POSIX إلى البيانات في تخزين الكائنات السحابية. تتطلب العديد من أطر عمل التعلم الآلي ووحدات OSS Python النمطية الأخرى FUSE ويمكنها استخدام مسارات بنمط POSIX فقط.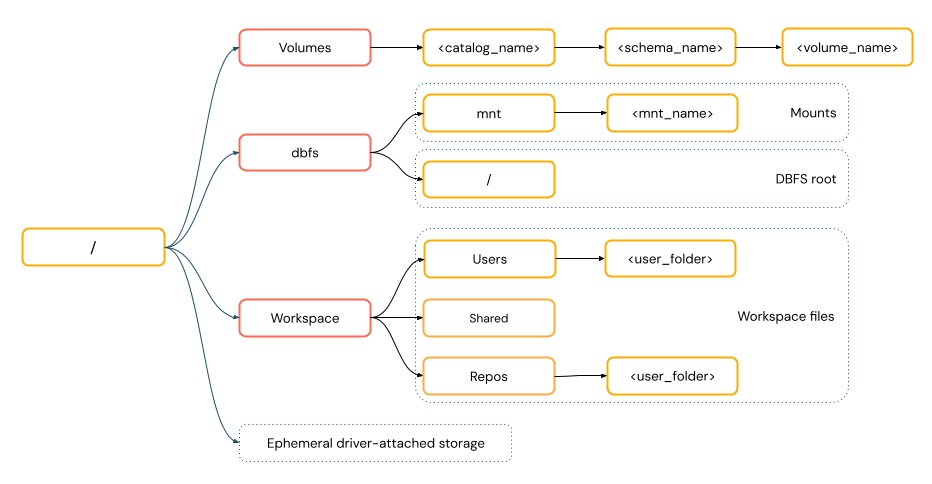
العمل مع الملفات في وحدات تخزين كتالوج Unity
توصي Databricks باستخدام وحدات تخزين كتالوج Unity لتكوين الوصول إلى ملفات البيانات غير الجدولية المخزنة في تخزين كائن السحابة. راجع ما هي وحدات تخزين كتالوج Unity؟.
| أداة | مثال |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL وDatabricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| أدوات نظام ملفات Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| أوامر Bash shell | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| تثبيتات المكتبة | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
إشعار
dbfs:/ المخطط مطلوب عند العمل مع Databricks CLI.
قيود وحدات التخزين
وحدات التخزين لها القيود التالية:
لا يتم اعتماد عمليات الكتابة المباشرة أو غير المتتالية (العشوائية)، مثل كتابة ملفات Zip وExcel. بالنسبة لأحمال العمل ذات الإلحاق المباشر أو الكتابة العشوائية، قم بتنفيذ العمليات على قرص محلي أولا ثم انسخ النتائج إلى وحدات تخزين كتالوج Unity. على سبيل المثال:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')الملفات المتفرقة غير مدعومة. لنسخ ملفات متفرقة، استخدم
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
العمل مع ملفات مساحة العمل
ملفات مساحة عمل Databricks هي الملفات الموجودة في مساحة عمل ليست دفاتر ملاحظات. يمكنك استخدام ملفات مساحة العمل لتخزين البيانات والملفات الأخرى المحفوظة جنبا إلى جنب مع دفاتر الملاحظات وأصول مساحة العمل الأخرى والوصول إليها. نظرا لأن ملفات مساحة العمل لها قيود على الحجم، توصي Databricks فقط بتخزين ملفات البيانات الصغيرة هنا بشكل أساسي للتطوير والاختبار.
| أداة | مثال |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL وDatabricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| أدوات نظام ملفات Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| أوامر Bash shell | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| تثبيتات المكتبة | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
إشعار
file:/ المخطط مطلوب عند العمل مع Databricks Utilities أو Apache Spark أو SQL.
للحصول على القيود في العمل مع ملفات مساحة العمل، راجع القيود.
أين تنتقل ملفات مساحة العمل المحذوفة؟
يؤدي حذف ملف مساحة عمل إلى إرساله إلى سلة المهملات. يمكنك استرداد الملفات أو حذفها نهائيا من سلة المهملات باستخدام واجهة المستخدم.
راجع حذف كائن.
العمل مع الملفات في تخزين كائن السحابة
توصي Databricks باستخدام وحدات تخزين كتالوج Unity لتكوين الوصول الآمن إلى الملفات في تخزين الكائنات السحابية. يجب تكوين الأذونات إذا اخترت الوصول مباشرة إلى البيانات في تخزين كائن السحابة باستخدام URIs. راجع إدارة المواقع الخارجية والجداول الخارجية ووحدات التخزين الخارجية.
تستخدم الأمثلة التالية URIs للوصول إلى البيانات في تخزين كائن السحابة:
| أداة | مثال |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL وDatabricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| أدوات نظام ملفات Databricks | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| Databricks CLI | غير مدعوم |
| Databricks REST API | غير مدعوم |
| أوامر Bash shell | غير مدعوم |
| تثبيتات المكتبة | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | غير مدعوم |
| OSS Python | غير مدعوم |
إشعار
العمل مع الملفات في تركيبات DBFS وجذر DBFS
تركيبات DBFS غير قابلة للتأمين باستخدام كتالوج Unity ولم تعد موصى بها من قبل Databricks. يمكن لجميع المستخدمين في مساحة العمل الوصول إلى البيانات المخزنة في جذر DBFS. توصي Databricks بعدم تخزين أي تعليمات برمجية أو بيانات حساسة أو إنتاجية في جذر DBFS. راجع ما هو DBFS؟.
| أداة | مثال |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL وDatabricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| أدوات نظام ملفات Databricks | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| Databricks CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| أوامر Bash shell | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| تثبيتات المكتبة | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
إشعار
dbfs:/ المخطط مطلوب عند العمل مع Databricks CLI.
العمل مع الملفات في التخزين المؤقت المرفق بعقدة برنامج التشغيل
التخزين المؤقت المرفق بعقدة برنامج التشغيل هو تخزين الكتلة مع الوصول إلى المسار المضمن المستند إلى POSIX. تختفي أي بيانات مخزنة في هذا الموقع عند إنهاء نظام مجموعة أو إعادة تشغيلها.
| أداة | مثال |
|---|---|
| Apache Spark | غير مدعوم |
| Spark SQL وDatabricks SQL | غير مدعوم |
| أدوات نظام ملفات Databricks | dbutils.fs.ls("file:/path") %fs ls file:/path |
| Databricks CLI | غير مدعوم |
| Databricks REST API | غير مدعوم |
| أوامر Bash shell | %sh curl http://<address>/text.zip > /tmp/text.zip |
| تثبيتات المكتبة | غير مدعوم |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
إشعار
file:/ المخطط مطلوب عند العمل مع Databricks Utilities.
نقل البيانات من التخزين المؤقت إلى وحدات التخزين
قد ترغب في الوصول إلى البيانات التي تم تنزيلها أو حفظها في التخزين المؤقت باستخدام Apache Spark. نظرا لإرفاق التخزين المؤقت بالسائق وSpark هو محرك معالجة موزع، لا يمكن لجميع العمليات الوصول مباشرة إلى البيانات هنا. افترض أنه يجب نقل البيانات من نظام ملفات برنامج التشغيل إلى وحدات تخزين كتالوج Unity. في هذه الحالة، يمكنك نسخ الملفات باستخدام الأوامر السحرية أو أدوات Databricks المساعدة، كما في الأمثلة التالية:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
الموارد الإضافية
للحصول على معلومات حول تحميل الملفات المحلية أو تنزيل ملفات الإنترنت إلى Azure Databricks، راجع تحميل الملفات إلى Azure Databricks.